2022-05-16 ~ 2022-05-22
멋사 4주차
1. Lecture
-
MLP(Multi-Layer Perceptron)
-
DL
-
Forward Pass
-
Activation Function
-
Loss Function
-
(실습) Pytorch
-
(실습) MLP MNIST Classification
(1) Forward Pass
-
입력이 주어진 상태에서 MLP 모델이 출력을 추론하는 과정
-
Parameters와 activation function을 이용해 각 입력에 대해 출력을 함수의 형태로 얻음
-
각층에서 입력이 weights와 곱해지는 선형적인 형태를 가지기 때문에 행렬곱의 형태로 간단하게 표현 가능
(2) Backward Pass
-
Back propagation
-
Forward pass로 얻은 출력 추론값과 해당 입력의 참 출력값을 이용해 loss 값을 얻어, 전체모델을 학습하는 과정
-
Loss로부터 얻은 error signal을 back propagation 알고리즘을 이용해 모든 parameter에 전파
(3) Batch Training
대용량의 데이터를 가지고 학습을 진행할 때 모든 데이터에 대해서 학습을 하는 경우 계산량이 많아져서 한 번 가중치를 업데이트 하는데 학습시간이 증가한다. Batch를 사용하여 이러한 문제점을 해결할 수 있다. (전체 데이터를 쓰면 정확하지만 느리지만, Batch를 사용할 경우 빠르지만 헤맬 수 있다.)
하나의 데이터를 벡터로 표현했을때, 데이터의 묶음(batch)을 행렬로 표현해 parameters와의 곱을 행렬과 행렬의 곱으로 표현
(4) Mini-Batch Training
효율적인 학습을 진행하는 동시에 학습과정에 randomness를 추가해주기 위해 데이터셋 전체를 하나의 batch로 보는 것이 아니라 그 일부를 mini-batch로 취급하여 전체 데이터 셋으로 여러번의 학습과정을 진행
2. Pytorch
(1) Introduction
PyTorch는 TensorFlow와 함께 가장 많이 사용되는 딥러닝 학습 패키지로 TensorFlow보다 늦게 등장했지만 사용 방법이 더 직관적이기 때문에 최근에는 더 많이 사용되고 있다.
PyTorch의 tensor datatype은 Numpy의 행렬 연산과 유용한 기능들을 지원하며, PyTorch 내부적으로 모델 학습과 관련된 다양한 알고리즘들이 구현되어 있다.
torchvision 등 학습과 실습에 유용한 패키지들이 추가적으로 개발되어 있기 때문에 AI 엔지니어로서 딥러닝 모델을 개발하는 데에 필수적인 툴이다.
(2) Torch tensor
Torch의 tensor는 numpy의 ndarray와 마찬가지로 다차원 데이터 배열이다.
numpy의 연산과 기법들을 대부분 사용 가능하며, 다른 점은 모델 학습에 필요한 back propagation을 다루기 위해 이를 위한 정보들을 내부에 추가적으로 저장한다는 것이다.
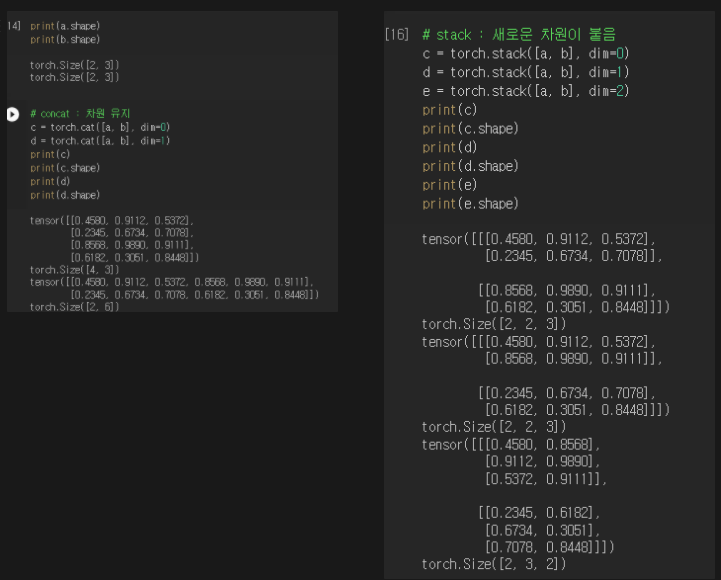
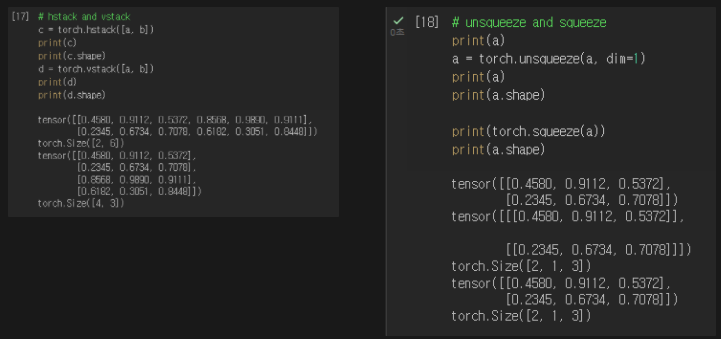
(3) datasets, dataloaders
dataset은 전체 데이터를 sample 단위로 처리해서 주는 역할을 하며 dataloader는 이를 batch 단위로 묶어주는 역할을 한다.
(4) torch.nn.Module
pytorch 모델은 parameters를 추적하며 forward pass를 진행한 뒤 back propagation을 통해 학습을 진행해야 한다.
그렇지만 deep learning 모델은 굉장히 여러 층의 layer를 포함하기 때문에 이들을 각각 다루는 건 굉장히 복잡하고 지저분한 작업이 된다
torch.nn의 Module class는 이러한 작업을 대신 해준다.
전체 모델과 그 내부의 block, 각 block 내부의 layer들이 Module을 subclass 하게 되면 parameters를 추적해주고 유용한 기능들을 한 번에 수행 해준다.
멀캠 프로젝트 6주차 (END)
1. Multicampus에서 배운 것들
파이널 프로젝트를 끝으로 멀티캠퍼스 과정이 종료되었다.
관련 지식 하나도 없이 시작하여, 2021년말부터 5월까지 많은 것을 배우고 많은 것을 할 수 있게 되었다.
다뤘던 내용을 정리해보자면 아래와 같다.
- Python, Jupyter Notebook 등 환경설정
- Python 기본문법
- 데이터 수집 및 관리 (Pandas, Numpy, Selenium, BeautifulSoup, 정규표현식)
- 데이터 시각화 (Matplotlib, Seaborn, Wordcloud)
- 머신러닝 및 딥러닝 기초 (경사하강법, 회귀, 분류, sklearn, 추천시스템)
- 딥러닝 (텍스트 임베딩, Keras, MLP, RNN, LSTM, mecab, transformer, BERT)
- AWS
- SQL
- Github
- Algorithm 기초
각각의 개념들의 깊이는 다르며, 관심이 있는 것은 추가학습을 하며 살을 붙여 나갔다.
2. Final Project
2022.04.04 부터 시작한 파이널 프로젝트가 2022.05.18에 마무리 되었다.
원래 5명인데, 우리조는 한명이 취업에 성공하여 4명이 진행하였다.
고생한 보람이 있게 우수상을 받을 수 있었다.
역시 프로젝트는 주제선정이 가장 어렵다. 2주간의 회의 끝에 '부동산 시계열 데이터를 이용한 저평가 매물 찾기'가 선정되었다.
주식 데이터는 yfinance, FinanceDataReader를 통해 쉽게 자료를 수집할 수 있지만,
부동산 데이터는 KOSIS, KB부동산 등에서 수집하여 소스코드를 직접 만들어서 EDA를 수행하여야 한다.
프로젝트의 세부내용은 Github에 정리해두었다.
