경량화란
글의 정보가 정확하지 않을 수 있으니 잘못된 설명이나 틀린 것이 있다면 댓글로 달아주시면 감사하겠습니다.
성능을 떨어뜨리지 않고 모델의 parameter와 연산량을 줄이는 방법을 경량화라고 부르며
경량화의 대표적인 기법으로 Pruning과 Quantization이 있습니다.
Pruning
Pruning에는 여러가지 방법이 있습니다.
특정 layer만 적용을 한다거나 global layer에 대해서 적용을 할 수도 있습니다.
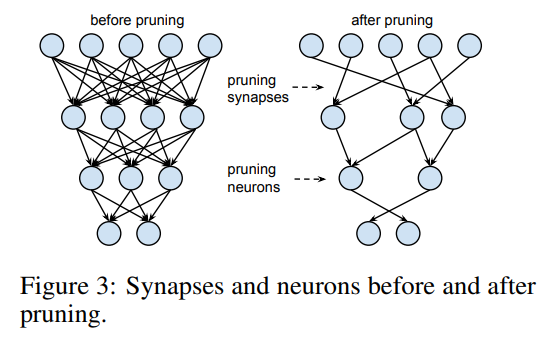
Pruning이란 말 그대로 불필요한 것들을 잘라주는 작업입니다.
예를 들어 나무의 성장을 위해서 잔가지들을 주기적으로 정리해주는 것과 같다고 생각하시면 됩니다.
딥러닝 모델은 학습을 위한 많은 parameter를 가지고 있고 학습이 끝나면 정답을 맞추기 위해 parameter들이 적당한 weight를 가지게 됩니다.
그런 parameter 중 중요도가 낮은 parameter의 연결을 제거하여 모델의 크기를 줄이는 방법입니다.
위의 그림과 같이 neuron을 줄이고 synapse의 연결이 끊기게 되면서 연산량과 parameter의 수가 줄어들게 되면서 경량화가 진행됩니다.
딥러닝 모델의 layer들은 weight와 bias으로 이루어져 있는데, 이중에서 일반적으로 Pruning을 진행하는 것은 weight입니다.
왜냐하면 bias는 parameter에서 차지하는 비율이 적기 때문에 Pruning를 진행해봐야 큰 차이가 나지 않습니다.
Sparsity
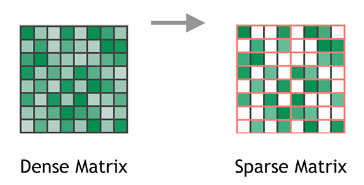
Sparsity이란 행렬안에 0의 값이 얼마나 분포되어 있는지로 이해하시면 편합니다.
위의 그림과 같이 Dense Matrix와 Sparse Matrix는 확연히 차이가 보입니다.
Pruning 또한 이런 방식으로 layer안의 parameter 값들이 없어지면서 진행됩니다.
예를 들어 아래와 같은 행렬이 존재한다고 봅시다.
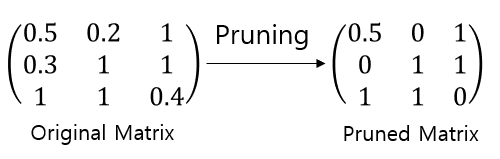
이 행렬에서 전체의 33%만큼 Pruning을 진행하게 되면 이미지와 같이 layer의 parameter들 중33%에 속하는 값들은 0 그리고 나머지 값들은 값을 유지하게 됩니다.
이런 식으로 0으로 변하게 된 부분들은 전체 딥러닝 네트워크에서 얼마나 많은 weight가 0 이라는 값을 가지고 있는지 알 수 있는 기준이 됩니다.
Sparsity을 가장 간단하게 계산을 할 수 있는 방법은 계산법이 있습니다.
수식은 요소마다 가지고 있는 값이 1 또는 0이 되면서, 0이 아닌 값들의 개수를 구하여 전체 대비 0이 아닌 값들의 개수를 확인하면 희소성을 알 수가 있습니다.
실제 성능 분석
이번 문단은 제가 잘못 이해했을 수도 있기때문에 참고만 하시기 바랍니다.
혹시나 다른 작동 원리를 가지고 있고 그런 이유로 speedup에 큰 영향을 주지 않는다면 알려주시면 감사하겠습니다.
저도 검색을 하며 Pruning와 Quantization에 대해서 많이 찾아봤습니다.
링크 글에서 많은 정보를 얻었고 Pruning이 실제로 어떤 결과를 보이는지에 대해서 잘 설명해주고 있습니다.
또한 아래의 링크들을 보시면 Pytorch 공식 홈페이지에서 Pruning이 speedup에 영향을 주지 않는 것 같다라는 질문에 대한 답변들이 2~3개 정도 있습니다.
[1] https://discuss.pytorch.org/t/pruning-doesnt-affect-speed-nor-memory-for-resnet-101/75814
[2] https://discuss.pytorch.org/t/discussion-of-practical-speedup-for-pruning/75212
[3] https://stackoverflow.com/questions/62326683/prunning-model-doesnt-improve-inference-speed-or-reduce-model-size
위의 3가지 질문과 답변들을 종합해보면 Torch에서 지원하는 torch.nn.utils.prune 을 통한 Pruning은 어느정도를 적용할 것인가에 대한 amount 인자를 받습니다. 0~1 사이의 값들 중 입력한 만큼 해당 레이어의 파라미터들 중 입력한 값만큼 Pruning이 진행됩니다.
튜토리얼 링크를 타고 가시면 pytorch 공식 튜토리얼 문서를 번역해놓은 버전을 보실 수 있습니다.
튜토리얼 링크에서 amount 만큼 Layer의 값을 0으로 바꿔주는데, 얼핏 보면 이것으로 인해서 계산량이 줄어든다고 생각하여 speedup이 되겠구나 라는 생각을 하실 수도 있습니다.
저도 그랬거든요!
하지만 실제로 해당 layer의 파라미터 구조가 바뀌지 않고 안의 값만 0으로 바뀌는 것이기 때문에 똑같이 계산이 되고 원래 있던 가중치가 아닌 0을 곱하는 것입니다.
이러한 이유 때문에 speedup에 영향을 주지 못할 수도 있다는 답변이 있습니다.
정리
요약 : 경량화 기법 중 연산량에 영향을 주는 Quantization에 대해서 공부할 예정임
개인적인 공부로 모델 경량화에 대해서 공부하다가 Pruning과 Quantization을 알게 됐습니다.
깊게 공부를 해야한다고 생각하여 Pruning에 대해서 좀 더 찾아봤으나 speedup에 큰 영향을 주지 않을 수도 있다는 글들이 꽤나 많은걸 확인했습니다.
그래서 저는 Pruning은 이론과 튜토리얼을 통해서 기본적인 것을 익힌 후 Quantization에 대해서 좀 더 공부를 해볼 생각입니다.
다음 글은 아마 Quantization의 개념에 대해서 작성할까 합니다.
잘 정리되어 있지 않지만 읽어주셔서 감사합니다.
레퍼런스에 있는 블로그 문장들과 유사한 부분이 있을 수 있습니다.
제가 작문이 좋지 않아서 비슷하게 쓰인 부분이 있고 혹시나 원작자들께서 불편하시다면 댓글로 알려주시면 바로 수정토록 하겠습니다.
레퍼런스
[1] https://tutorials.pytorch.kr/intermediate/pruning_tutorial.html
[2] https://velog.io/@woojinn8/LightWeight-Deep-Learning-1.-Pruning
[3] https://computing-jhson.tistory.com/42
