1. 변수(Variable)
1.1 변수란
단 하나의 값을 저장할 수 있는 메모리 공간
1.2 변수의 선언과 초기화
- 변수 타입 : 변수에 저장할 값의 종류를 지정(정수형, 실수형, 문자형..) -> 알맞은 크기의 저장공간 확보
- 변수 이름 : 메모리 공간에 이름을 붙이는 것 -> 변수를 활용할 수 있게 됨
- 변수의 초기화
1.3 변수 명명규칙
-
대소문자 구분, 길이에 제한 없음
-
변수 명으로 예약어를 사용하면 안됨
- 예약어(keyword, reserved word) : 프로그래밍언어의 구문에 사용되는 단어
-> 클래스/변수/메서드의 이름으로 사용 불가능
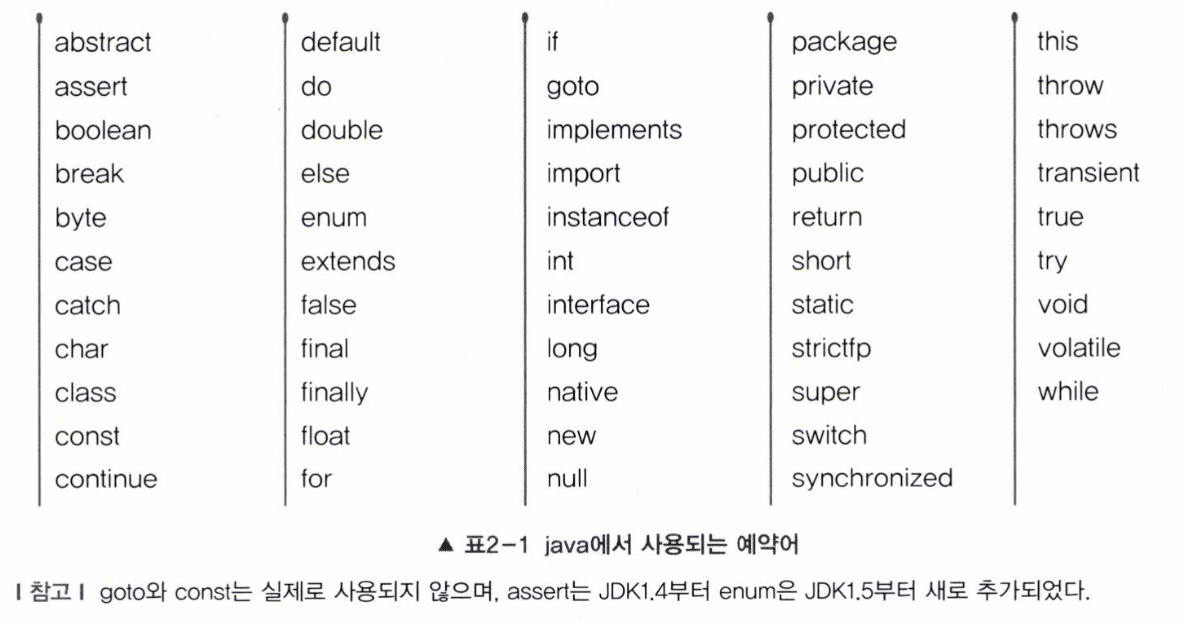
- 예약어(keyword, reserved word) : 프로그래밍언어의 구문에 사용되는 단어
-
숫자로 시작 불가능
-
특수문자는 "_", "$" 만 사용 가능
coding convention
- 클래스 이름은 대문자로 시작
- 여러 단어로 이루어진 이름의 단어는 대문자로 시작(ex. LastIndexOf, StringBuffer)
- 상수의 이름은 모두 대문자로. 여러 단어로 이루어진 경우 '_' 로 구분(ex.PI, MAX_NUMBER)
2. 변수의 타입
- 기본형 변수 : 실제 값(data) 저장 [8개]
논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double)
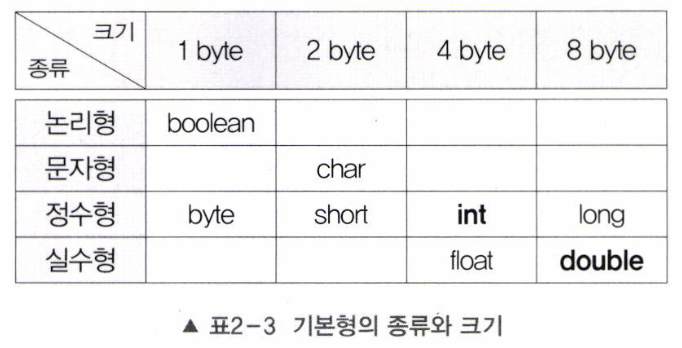

- 논리형
- boolean : 다른 기본형과 연산 불가능
- 문자형
- char : 내부적으로 정수(유니코드)로 저장 -> 정수형/실수형과 연산 가능
- 정수형
- byte : 이진 데이터 처리
- short : C언어와의 호환을 위해 추가됨
- int : ~ == ~
- 실수형 : 정수형과 저장형식이 달라 같은 공간이라도 훨씬 큰 값을 표현, 오차가 발생할 수 있어 정밀도가 중요(정밀도⬆️ = 오차의 범위⬇️) -> 실수형에서 타입 선택시 저장 가능 값의 범위 + 정밀도 고려 필요

- 정밀도가 7자리 = 10진수의 7자리 수를 오차없이 저장 가능
- 참조형 변수 : 객체의 주소(memory address)를 값으로 저장, 기본형 변수 외에 나머지
참조형 변수 간의 연산은 불가능, 실제 연산에 사용되는 것은 모두 기본형 변수
JVM이 32bit라면 참조형 변수의 크기는 4byte (64bit -> 8byte)
새로운 클래스를 작성한다 = 새로운 참조형 변수를 만든다
-> 참조형 변수를 선언할때 변수의 타입으로 클래스의 이름을 사용
2.2 상수(constant)와 리터럴(literal)
상수
: 값을 저장할 수 있는 공간(=변수), 단, 값을 한번 저장하면 변경 할 수 없음
- 방법 : 'final' 키워드 붙이기
- ex)
cf. JDK1.6부터 상수를 선언과 동시에 초기화 하지 않아도 되며, 사용하기 전에만 초기화하면 되도록 바뀌었음final int MAX_SPEED=10; - 상수가 필요한 이유
- 리터럴에 '의미있는 이름'을 붙여서 코드의 이해와 수정을 쉽게 만듬
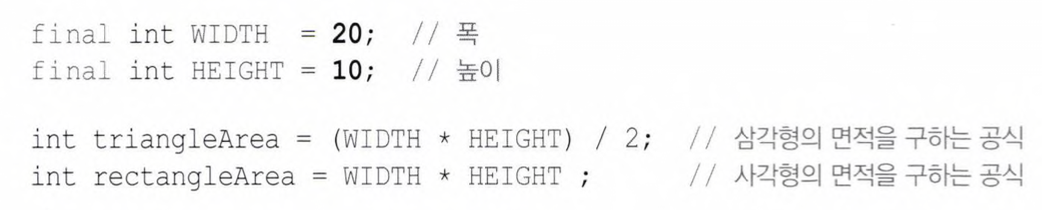
- 리터럴에 '의미있는 이름'을 붙여서 코드의 이해와 수정을 쉽게 만듬
리터럴
: 기존 수학에서 말하는 숫자(상수) = 그 자체로 값을 의미하는 것

리터럴의 타입 / 접미사
- 정수형 리터럴
- 접미사가 없는 경우 : int
- long : 접미사 l / L (ex. 100L)
- byte/short : 별도의 리터럴 존재x, int 사용
- 진법 : 0x/0X(16진수), 0(8진수), 0b(2진수)
- +) 정수형 리터럴의 중간에 구분자 '_'를 넣을 수 있어 가독성 증가
(ex. long big = 100_000_000_000L; // long big = 100000000000L;)
-
실수형 리터럴
- 접미사가 없는 경우 : double
- float : F/f
- double : d/D
- +) 리터럴에 소수점 / E / e / 접미사(F,f, D,d)포함시 실수형 리터럴로 간주
ex)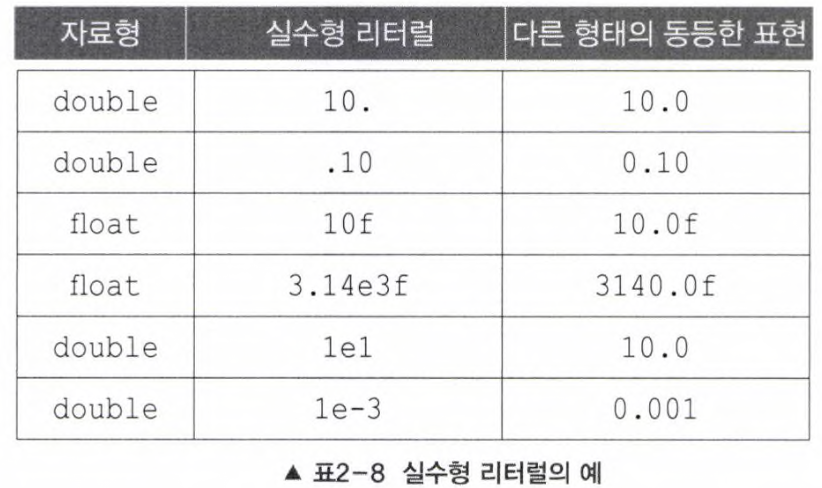
- cf. 기호 p를 이용해 실수 리터럴을 16진 지수 형태로 표현 가능
(p=2의 제곱, p의 왼쪽 = 16진수, p의 오른쪽 = 지수를 10진 정수로)
ex) 0x1p1 =
-
문자형 리터럴 : 접미사 x ('A', '1', '\n')
아무런 문자를 넣지 않는 것은 불가능(ex. char ch='';) -
문자열 리터럴 : 접미사 x ("ABC", "123", "true")
- 빈 문자열 가능 (ex. String str = "")
- 덧셈 연산자를 이용해 문자열 결합 가능
- String + (다른 타입) = String
-> 기본형 타입을 문자열로 변환할때는 빈 문자열("")을 더해주면 됨7 + "7" -> "77" true + "" -> "true"
-
논리형 리터럴 : 접미사x(false, true)
타입 불일치(리터럴 타입 변수 타입)
리터럴 타입 변수 타입 (0)
저장범위가 넓은 타입 <- 좁은 타입의 값을 저장 (0)
저장 범위가 좁은 타입 <- 저장 범위가 더 넓은 리터럴(X 컴파일 에러)
변수타입의 범위 < 리터럴값의 범위 (X 컴파일 에러)
float 타입의 변수 <- double 타입의 literal (X 값의 크기에 상관없이 에러)
ex)
int i = 0x123456789; // 에러 . int 타입의 범위를 넘는 값을 저장
float f = 3.14; //에러.float 타입 보다 double 타입의 범위가 넓다.
byte b = 65; // OK. byte타입에 저장 가능한 범위의 int타입 리터럴
short s = 0x1234; // OK. short타입에 저장 가능한 범위의 int타입 리터럴2.3 printf : 지시자(%d,...를 통해 변환 출력)

- 출력은 기본이 우측정렬(-를 붙이면 좌측정렬)
- %s : %.{출력할문자열길이} ex. %.8s : 왼쪽에서 8글자만 출력
- %f : 소수점 아래 6자리까지 출력(7자리에서 반올림)
- %전체자리.소수점자리f (소수점도 한자리 차지)
ex. %014.10 : 총14자리, 소수점아래 10자리까지, 빈자리 0으로 채움(001.2345678900)
- %전체자리.소수점자리f (소수점도 한자리 차지)
- 줄바꿈 : %n(OS와 상관없이 보다 안전), \n
2.4 화면에서 입력받기(Scanner)
import java.util.Scanner;
public class ex1 {
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
String input = scanner.nextLine(); // 한 줄을 입력받음
int inputN = Integer.parseInt(input); //String->int
// int inputN = scanner.nextInt(); // 정수를 입력받음
System.out.println(inputN);
}
}3. 진법
3.1 10진법, 2진법
컴퓨터의 전기회로는 전압이 불안정해서 10단계(10진법)로 나누어 처리하는 것은 한계가 있음
-> 전기가 흐르면 1, 흐르지 않으면 0 (=2진법)
3.2 비트(bit), 바이트(byte)
- 비트(bit) : 한자리의 2진수 = 컴퓨터가 값을 저장할 수 있는 최소 단위
- 바이트(byte) : 1비트 * 8개 = 데이터이 기본 단위
- 워드(word) : CPU가 한 번에 처리할 수 있는 데이터의 크기 (CPU의 성능에 따라 달라짐)
ex. 32비트 CPU : 1 word = 32 bit(4byte)

n비트로 표현할 수 있는 10진수
- 개수 :
- 값의 범위 : 0 ~
3.3 8진법, 16진법
2진법으로 표현할 때의 단점 : 자리수가 길어진다
-> 8진법, 16진법
2진수 -> 8진수 : 3자리씩 끊어서 변환
2진수 -> 16진수 : 4자리씩 끊어서 변환
3.4 정수의 진법변환
3.5 실수의 진법변환
10진 소수점수 -> 2진 소수점수 변환 방법 : 정수부, 소수부 별도로 변환하여 더함
- 정수부 : 10진수->2진수 변환방법 동일
- 소수부 : 10진 소수점수에 2를 계속 곱함


3.6 음수의 2진 표현 : 2의 보수법
👽 배경
4비트의 2진수로는 총 개의 값을 표현할 수 있다.
부호없는 정수(0과 양수)로 나타내면 0~15까지 나타낼 수 있음
양수와 음수 모두를 표현하려면 4비트 2진수의 절반은 0, 나머지 절반은 1로 시작함을 활용
-> 왼쪽의 첫 번째 비트(MSB = Most Significant Bit)가 0이면 양수, 1이면 음수로 부호를 표현
-> (1) 양수의 첫 번째 비트만 1로 바꾸는 방법 : 여러 문제가 발생
-> (2) 2의 보수법
(1) 양수의 왼쪽 첫 번째 비트만 1로 바꿔서 음수로 표현하는 방법 (ex. 5 = 0101, -5 = 1101) 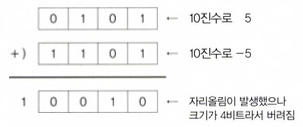
- 표현이 쉽다 : 왼쪽 첫 번째 배트만 1로 바꾸면 됨
- 0이 두개 존재(+0, -0)
- 절댓값은 같고 부호만 다른 두 수를 더했을 때 2진수로 0이 되지 않는다(+5, -5)
- 2진수가 증가할 때 10진 음수는 감소한다
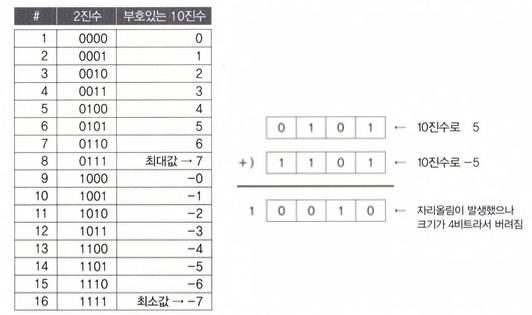
(2) 2의 보수법
어떤 수의 'n의 보수'는 더했을 때 n이 되는 수를 의미한다.
'n의 보수의 관계' = 더해서 n이 되는 두 수의 관계
-> '2의 보수 관계' = 더해서 2가 되는 두 수의 관계
ex. 7의 '10의 보수' = 3, 3의 '10의 보수' = 7 -> 3과 7은 '10의 보수의 관계'에 있다
[2진수로 10]
= 자리올림이 발생하고 0이 되는 수를 의미
-> 2의 보수 관계에 있는 두 2진수를 더하면 (자리올림이 발생하고) 0이 된다.
(ex. , 과 는 서로 2의 보수 관계에 있음)
👽 음수를 2진수로 표현하기
- 절댓값 취하기
- 2진수로 바꾸기
- 2의 보수(1의 보수 + 1)
ex) -5 -> 5 -> ->
✹ 2의 보수 구하기 = 1의 보수(0,1 반전) + 1
∵ 어떤 2진수에 1의 보수를 더하면 모든 자리가 1이 된다. 여기에 1을 더하면 0이 된다(올림 발생)
즉 1의 보수 + 1 = (자리 올림이 발생하고) 0
4. 기본형
4.1 논리형 - boolean
- 값 : true / false
- 1 bit로 충분하지만 자바에서 데이터를 다루는 최소단위가 byte이기 때문에 1byte 차지
✹ TRUE/FALSE가 아님을 주의
4.2 문자형 - char
단 하나의 문자만을 저장
(음수를 표현하지 않아 동일하게 2byte 정수형-short-과 표현할 수 있는 값의 범위가 다름)
✹ 실제로는 문자가 아닌 '문자의 유니코드(정수)'가 저장됨
ex) 문자 'A'는 유니코드 65가 저장됨 (유니코드를 알고 싶다면 정수형-int로 변환하면 됨)
char ch = 'A'; // (1)
char ch = 65; // (2)
// (1), (2)는 동일
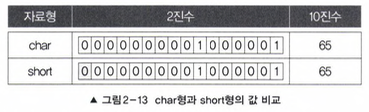
System.out.println(ch); // A가출력된다.
System.out.println(s); // 65가출력된다.
char와 short형 변수에 실제 저장된 값은 같지만 출력할 때 다르다
(=값은 어떻게 해석하느냐에 따라 결과가 달라진다.
ex. 1231이라는 값은 천이백삼십일/12월31일 /12시31분 등 다양하게 해석할 수 있다)

👽 인코딩, 디코딩
인코딩 : 문자('A') -> 유니코드(65)
디코딩 : 유니코드(65) -> 문자('A')
👽 아스키(ASCII), 유니코드(Unicode)
아스키(ASCII)
ASCII = American Standard Code for Information Interchange
128()개의 문자 집합을 제공하는 7bit 부호
구성 : 제어문자+기호/숫자/영대소문자
*제어문자 : 처음 32개 문자, 인쇄와 전송 제어용으로 사용됨
특징 : ‘0〜 9’,영문자 ‘A〜 Z’와 'a〜z'가 연속적으로 배치되어 있음
- 확장 아스키 : 남는 공간을 활용해서 문자를 추가로 정의한 것(데이터는 일반적으로 byte단위로 다뤄지는데 아스키는 7bit->1bit가 남음)
- 여러 종류 존재 : ISO(국제표준화기구)에서 발표한 ISO 8550-1,...
- 확장 아스키로 표현 가능한 문자 개수 : 255개 (한글을 표현하기에 부족)
- 한글표현 방법 : 조합형(초성+중성+종성 조합), 완성형(확장 아스키의 일부 영역(162~254)에 해당하는 두 문자코드를 조합
유니코드(Unicode)
등장 배경 : 인터넷이 발명되면서 서로 다른 언어(서로 다른 문자 인코딩)를 사용하는 컴퓨터간의 문서교환이 어려워짐
- 2byte + 21bit(추가된 보충문자)
- 유니코드 문자 셋(set) : 유니코드에 포함시키고자 하는 문자들의 집합UTF-8, UTF-16)
- UTF-8 vs UTF-16
- UTF-16 : 모든 문자 크기가 동일해서 다루기 편함, 문서의 크기가 커진다는 단점(영어/숫자를 1byte로 표현할 수 있는데 2byte)
- UTF-8 : 문서의 크기가 작지만 문자 크기가 가변적이어서 다루기 어려움 -> 전송속도/문서 크기가 중요한 인터넷 웹문서에서 사용되는 수가 빠르게 증가 중
✹JAVA : UTF-16 사용(모든 문자를 2byte의 고정 크기로 표현, 처음 128문자는 아스키와 동일)
<-> UTF-8 : 하나의 문자를 1~4byte의 가변크기로 표현
4.3 정수형 - byte, short, int, long


정수형의 표현형식
- n 비트로 표현할 수 있는 정수의 개수 : 개(=개)
- n 비트로 표현할 수 있는 부호있는 정수의 범위 : ~
정수형 선택
byte/short보다는 int 사용, 그보다 큰 범위는 long
∵JVM의 피연산자 스택이 피연산자를 4byte단위로 저장해서 그보다 작은 byte/short는 변환하는 연산이 추가적으로 필요
정수형의 오버플로우
오버플로우(overflow) : 타입이 표현할 수 있는 값의 범위를 넘어서는 것
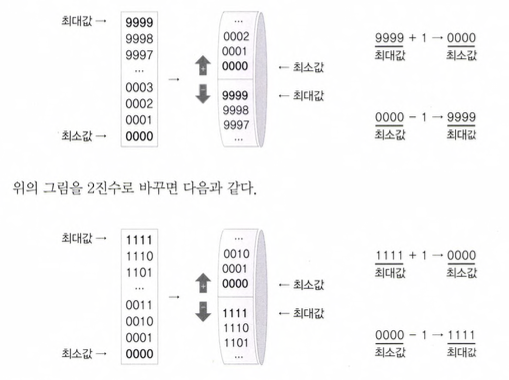
부호있는 정수의 오버플로우 : 부호비트가 0에서 1이 될 때 오버플로우가 발생

4.4 실수형 - float, double
실수형은 얼마나 큰 값을 표현할 수 있는가 + 얼마나 0에 가깝게 표현할 수 있는가가 중요
| 타입 | 저장 가능한 값의 범위 | 정밀도 | 크기 |
|---|---|---|---|
| float | ~ , ~ | 7자리 | 4byte |
| double | ~ , ~ | 15자리 | 8byte |
정밀도 n = n자리의 10진수를 오차없이 저장할 수 있다
✹ 높은 정밀도가 필요한 경우 double 타입 변수 사용, float : 연산 속도 향상/메모리 절약
언더플로우 & 오버플로우
오버플로우 : 무한대가 됨
언더플로우 : 0 (실수형으로 표현할 수 없는 아주 작은 값)
값 저장 형식
☑️ 정수형
| S(1) | 값(31bit) |
|---|
S : 부호
☑️ 실수형 : 부동소수점
=
| S(1) | E(8) | M(23) |
|---|
-
S(부호) : 0(양수), 1(음수)
-
E(지수) : 부호있는 정수
-127~128(float), -1023~1024(double)- -127, 128 : 숫자 아님(NaN), 양의 무한대, 음의 무한대
-
M(가수) : 실제값 저장
- float : 2진수 23자리 == 10진수 7자리(float의 정밀도)
- double : 2진수 52자리 (= float의 약 2배 높은 정밀도)
ex) 9.1234567
=
=
(1) 정규화 : 1.xxx 형태로 변환
1001.000111111001101011011... -> 1.001000111111001101011011
(2) 지수 : 기저법(지수에 기저인 127을 더하여 2진수로 변환하여 저장)
3+127 = 130 =

부동소수점의 오차
- 10진수로는 유한소수이지만 2진수로는 무한소수인 경우
(ex. 9.1234567 = 1101.000111111001101011011... )
- 가수를 저장할 수 있는 자리수가 한정되어 있음(잘리는 부분이 생김)

-> 최대 오차 : 약 (=가수의 마지막 비트의 단위)
-> float의 정밀도가 7자리(=소수점이하 6자리)

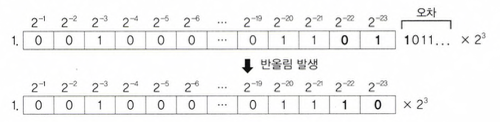
cf. 가수부분 저장시 잘려나가는 데이터가 있는 경우 반올림해서 저장됨
5. 형변환(캐스팅)
변수 또는 상수의 타입을 다른 타입으로 변환하는 것
서로 다른 타입간의 연산을 수행해아하는 경우
5.2 형변환 방법
(타입)피연산자
괄호 : 캐스트 연산자 / 형변환 연산자
- 형변환 가능 타입 : 기본형에서 boolean을 제외한 나머지 타입간의 형변환
(기본형<->참조형 : 불가능)
5.3 정수형간의 형변환
큰타입 -> 작은타입으로의 변환 : 값손실 발생 위험 있음
작은타입->큰타입으로의 변환 : 빈 공간을 0(양수), 1(음수)으로 채움(=값 손실 없음)
5.4 실수형 간의 형변환
float->double
- 지수(E) : float의 기저인 127을 뺀 후 double의 기저인 1023을 더해서 변환
- 가수(M) : float의 가수 23자리를 채우고 남은 자리를 0으로 채움

double -> float
- 지수(E) : double의 기저인 1023을 뺀 후 float의 기저인 127을 더함
- 가수(M) : double의 가수 52자리 중 23자리만 저장되고 나머지는 버려짐
- 가수의 24번째 자리에서 반올림이 발생 할 수 있음(24번째 자리의 값이 1인 경우 1 증가)
- float의 타입의 범위를 넘는 값을 float로 형변환 하는 경우 : or
- double, float는 저장될 때 값이 달라지기 때문에 형변환을 해도 값이 같아지지는 않음

5.5 정수형과 실수형 간의 형변환
정수형 -> 실수형
정수를 2진수로 변환 -> 정규화
*float는 10진수로 7자리의 정밀도만을 제공 -> 8자리 이상의 값을 실수형으로 변환할 때는 double로 형변환해야 오차가 발생하지 않음

실수형 -> 정수형
- 소수점이하 값은 버려짐(반올림x)
- 실수의 소수점을 버리고 남은 정수가 정수형의 저장범위를 넘는 경우에는 정수의 오 버플로우가 발생한 결과를 얻는다.
5.6 자동 형변환
서로 다른 타입간의 대입이나 연산을 할 때, 컴파일러가 생략된 형변환을 자동적으로 추가하기도 함
(기존의 값을 최대한 보존할 수 있는 타입으로 자동 형변환)
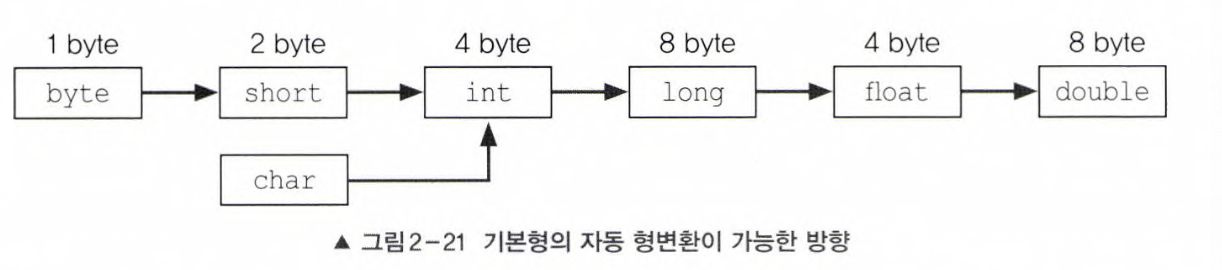
- 큰 타입에 작은 타입을 저장/연산하는 경우 : 작은 타입을 큰 타입으로 형변환
- 실수형에 정수를 저장/연산하는 경우 : 정수를 실수로 형변환
자동형변환 되지 않는 경우
- 작은 타입에 큰 타입을 저장하는 경우(byte변수에 int 저장)
