[파이널 프로젝트] 클러스터 오브젝트 구축(front/back deployment, service, ingress, EFS 스토리지, HPA, AutoScaling)
구름_Kubernetes

인프라 구축
-
Front/back 개발을 담당하는 팀원도 이제 개발을 시작했기에 Front/back 실행파일이 존재하지 않는다.
-
따라서 개발자가 git에 push한 실행파일을 가지고 Jenkins가 테스트와 빌드를 거쳐 이미지를 생성해 Docker Hub에 넣어서 ArgoCD와 연동중인 Git에서 Docker Hub에 Push된 이미지를 가져와 배포하지 못한다.
-
따라서 우선적으로 개발이 완료되기 전까지는 Jenkins를 사용하지는 않고 기존의 이미지를 사용하여 클러스터에 배치할 오브젝트를 YAML파일로 작성을 해두기로 했다.
-
이후 YAML파일로 작성한 코드를 새로운 Git repo를 생성해서 Push한다.
-
ArgoCD에 접속할 수 있게 ArgoCD서비스를 설치하고 aws로드밸런서 주소로 ArgoCD로 접속한다.
ArgoCD에서 yaml파일이 존재하는 Git을 연동해서 클러스터를 배포한다.
📌 개발이 완료되기 전까지 인프라 구축을 완료할 것이다.
-
생성한 클러스터 오브젝트들은 ArgoCD로 배포가 잘 되는지 테스트 단계를 거친다.
-
이후 개발이 완료되면 개발자의 Front / Back 코드를 가지고 Jenkins에서 이미지화 시켜서 ArgoCD가 기존의 이미지가 아닌 새로운 개발자의 이미지로 배포하게 파이프라인을 구성한다.
📒 Frontend - Backend - DB : 3-tier (3계층) 구조
- Frontend는 클라이언트가 보는 정적페이지를 구축
- Backend는 서버의 역할로, 클라이언트가 정적페이지와 상호작용을 할때 DB의 정보를 가지고 페이지가 계속 바뀌게끔 동적으로 구성한다.
- DB는 RDS(관계형 데이터베이스)를 이용하여 정보를 체계적으로 관리
📒 Backend - Spring Boot, Frontend - html, css, js
- 개발자가 Spring Boot로 Backend 코드를 완성하게되면 src디렉터리와 pom.xml파일이 결과물로 산출된다. 이 산출물을 maven or gradle로 test와 빌드를 거치게 되고 target 디렉터리가 반환된다. target 디렉터리에는 jar or war파일이 존재한다.
- Dockerfile에서 tomcat서버를 생성하고 war or jar 파일을 tomcat서버의 특정 디렉터리에 복사하는 코드를 작성한다.
- 이렇게 복사함으로서 java기반의 웹 어플리케이션인 tomcat서버에 Backend 서버를 배포하는 것이다. 이것을 이미지로 만들어서 파드로 띄우게 되면 백엔드 서버역할을 하는 파드가 생성되는 것이다.
- Frontend를 구성하면 마찬가지로 실행파일이 생성되고 이 파일을 이미지로 구성해서 파드를 띄우면 클라이언트는 index.jsp처럼 웹 페이지를 보게 될 것이다. 여기에 Backend를 연결하게 되면 Backend 서버에 의해 클라이언트와 웹 페이지와의 동적인 상호작용이 가능해진다.
😊 만일 프로젝트의 규모가 작다면 그냥 Frontend를 구성하지 않고 Backend에서 index.jsp와 같은 client가 보는 웹페이지를 작게 구성해서 tomcat서버에 같이 올릴 수도 있다. 이렇게 해도 클라이언트는 Frontend없이 웹 페이지를 볼 수 있다. 하지만 보통 클라이언트가 상호작호작용하는 웹페이지는 대량의 데이터가 오가기 때문에 Frontend tier를 구성한다.
인프라 세팅에 사용된 코드들은 해당 깃 저장소에서 확인가능하다.
인프라 개발 세팅
eks 클러스터 배포
# cluster.yaml파일 작성
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: finalproject
region: ap-northeast-2
version: "1.24"
# AZ
availabilityZones: ["ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c"]
# IAM OIDC & Service Account
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: aws-load-balancer-controller
namespace: kube-system
wellKnownPolicies:
awsLoadBalancerController: true
- metadata:
name: ebs-csi-controller-sa
namespace: kube-system
wellKnownPolicies:
ebsCSIController: true
- metadata:
name: cluster-autoscaler
namespace: kube-system
wellKnownPolicies:
autoScaler: true
- metadata:
name: efs-csi-controller-sa
namespace: kube-system
wellKnownPolicies:
efsCSIController: true
# Managed Node Groups
managedNodeGroups:
# On-Demand Instance
- name: mynodes-t3
instanceType: t3.medium
minSize: 2
desiredCapacity: 2
maxSize: 5
privateNetworking: true # 워커노드를 프라이빗 네트워크에 감춘다.
#ssh:
#allow: true
#publicKeyPath: ./keypair/myeks.pub
availabilityZones: ["ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c"]
iam:
withAddonPolicies:
autoScaler: true
albIngress: true
cloudWatch: true
ebs: true
# Fargate Profiles
fargateProfiles:
- name: myfg
selectors:
- namespace: dev
labels:
env: dev
# CloudWatch Logging
cloudWatch:
clusterLogging:
enableTypes: ["*"] # 모든 로그를 클라우드워치에 남긴다
- 이전에 작성한 인프라 아키텍처대로 두개의 워커노드(EC2인스턴스)를 생성한다
- 각 EC2인스턴스는 2a, 2b, 2c 가용영역에 분포된다.
- Ingress와 HPA, 오토스케일링 그룹, 스토리지를 위한 애드온을 생성한다.
클러스터 오브젝트 생성
인프라 구축 작업에서는 Frontend에는 nginx이미지를, Backend에는 이전 파이프라인 실습에서 빌드하였던 이미지를 임시적으로 사용해서 디플로이먼트를 생성하고, 서비스와 ingress를 생성하는 것을 목표로 한다.
- 개발이 완료되는 대로 해당 Front와 Back에 임시적으로 사용되었던 이미지를 교체할것이다.
- YAML파일 작성 코드들, 기타 코드들은 모두 GitHub에서도 확인 가능하다.
Frontend
간단하게 nginx이미지로 Frontend파드를 생성해서 외부에서 접속이 잘 되는지 테스트한다.
- 프론트 관련 yaml파일들은 레이블을 tier: frontend로 통일하였다.
Deployment
# front-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: front-deploy
spec:
replicas: 2
selector:
matchLabels:
tier: frontend
template:
metadata:
name: front-deploy
labels:
tier: frontend
spec:
containers:
- name: front-app
image: nginx:alpine
ports:
- containerPort: 80
protocol: TCP- 파드는 2개 성성하도록 하였다.
- 컨테이너 이미지로 nginx 이미지를 가져오고 포트는 80으로 지정하였다.
Service
# front-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: front-svc
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 31112
selector:
tier: frontendIngress
# front-ing.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: front-ing
annotations: # AWS에서 ALB로 사용할수 있게 함
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: instance
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: front-svc
port:
number: 80- 외부에서 포트번호를 입력하지 않고도 접속이 가능하게 하는 L7에서 작동하는 ALB 생성
- Ingress를 사용하기 위해서는 LoadBalancer Controller 애드온을 설치하여야한다. 처음에 클러스터를 만들때 서비스 계정과 iam 애드온을 추가해서 만들었었다.
- 애드온 설치후 위의 어노테이션 추가
💡 지금은 front와 back 각각의 인그레스를 따로 만들어서 테스트를 진행하였다. 후에 2개의 인그레스를 하나로 합쳐서 prefix를 이용해서 프론트와 백에 접속할수 있도록 진행할 예정이다.
Backend
이전의 실습했던 이미지를 Docker Hub에서 가져와서 간단한 Backend 테스트한다.
- 백엔드 관련 yaml파일들은 레이블을 tier: backend로 통일하였다.
Deployment
# back-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: back-deploy
spec:
selector:
matchLabels:
tier: backend
replicas: 2
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: back-app
image: suhwan11/hello-world:49 # 이전에 생성했던 이미지
ports:
- containerPort: 8080
protocol: TCP- 이전에 생성했던 이미지는 git에 있는 src와 pom.xml를 Jenkins가 Maven으로 테스트와 빌드를 거쳐서 target을 만든 것이다. 이후 이 디렉터리 안에있는 war파일을 tomcat서버를 통해 백엔드 서버를 생성하는 것까지 진행하는 이미지이다. 이때 프론트엔드 구성없이 웹페이지를 간단하게 확인하기 위해 war파일에는 index.jsp가 존재해서 tomcat서버에 같이 올라간다.
- 이미지에 적용되는 포트가 8080이기에 컨테이너 포트를 8080으로 뚫어 주었다.
Service
# back-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: back-svc
spec:
selector:
tier: backend
ports:
- port: 80
targetPort: 8080
nodePort: 31111
type: NodePortIngress
# back-ing.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: front-ing
annotations: # AWS에서 ALB로 사용할수 있게 함
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: instance
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: front-svc
port:
number: 80- Ingress를 사용하기 위해서는 LoadBalancer Controller 애드온을 설치하여야한다. 처음에 클러스터를 만들때 서비스 계정과 iam 애드온을 추가해서 만들었었다.
- 애드온 설치후 위의 어노테이션 추가
결과 테스트
-
ArgoCD에서 간단한 Front와 Back 파드, service, Ingress가 정상적으로 배포가 되는 것을 확인
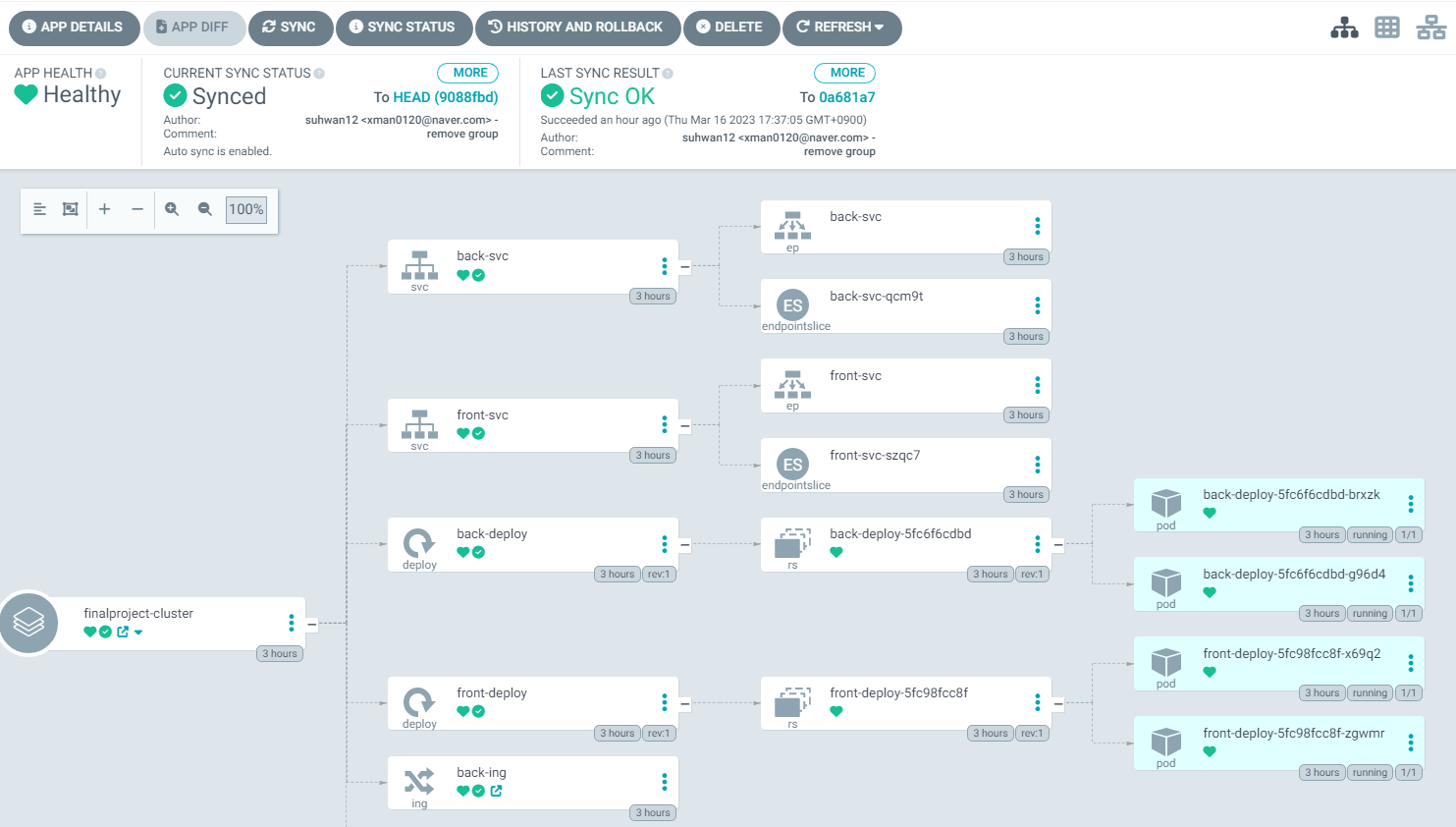
-
AWS콘솔에도 Front Ingress와 Back Ingress 두개가 ALB로 생성되어있는 것을 확인 가능
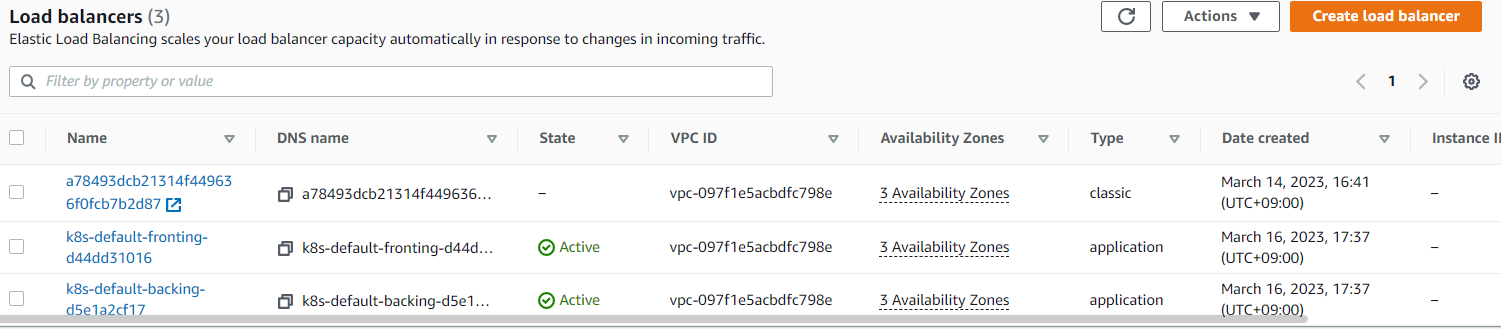
-
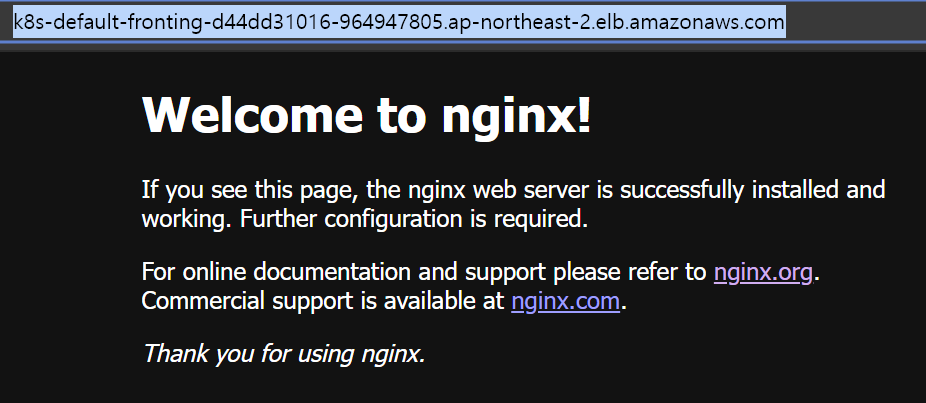
Front Ingress로 생성된 ALB의 DNS Name을 브라우저에 입력하면 정상적으로 웹페이지가 뜨는 것을 확인할 수 있다.
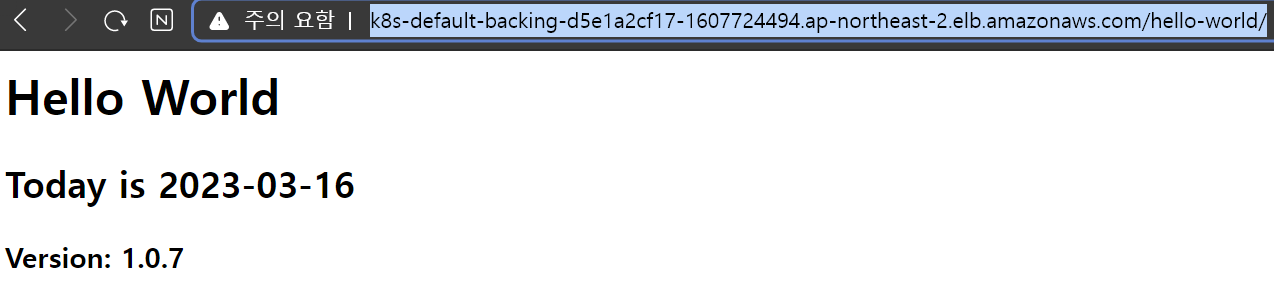
- Back Ingress로 생성된 ALB의 DNS Name을 브라우저에 입력하면 정상적으로 백엔드 서버가 tomcat서버에 올라와서 배포가 되어 서버가 생성 되었고, frontend 구성 없이 간단하게 테스트하기 위한 index.jsp의 내용이 웹페이지로 뜨는 것을 확인할 수 있다.
이미지를 생성할때 hello-world를 추가해야 보이게 설정해두었기 때문에 DNS 주소 뒤에 /hello-world를 붙여줘야한다.
EFS 스토리지
여러 AZ에 배포된 EC2인스턴스들이 동시적으로 하나의 스토리지에 접근해서 읽기/쓰기가 가능하게 하기 위해 EFS스토리지를 사용하는 것으로 결정했다.
📒 EBS스토리지는 AZ단위에서만 작업이 가능하다면, EFS는 AZ가 다른 인스턴스들도 하나의 스토리지에 접근이 가능하다. 물론 비용은 EBS보다 비싸다.
AWS EBS는 특정 가용영역에 생성되어 EC2에 붙는 스토리지로서 AccessMode가 ReadWriteOnce이다.
그러므로 동일한 노드에 배포된 Pod끼리만 공유가 가능하다.
서로 다른 노드에 배포된 Pod에서 동일한 스토리지를 공유하고 싶다면 EFS를 사용해야 한다.Amazon Cloud Storage 비교 총정리
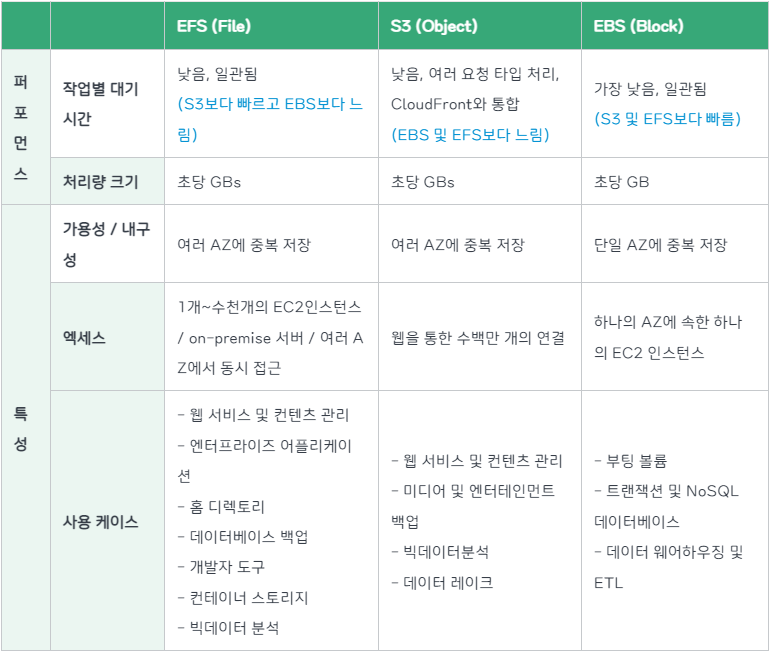
- 추후에 스토리지 클래스가 지정된 PVC를 파드에 마운트해서 PV를 동적으로 프로비저닝해서 PV가 EFS에 요청할 수 있게 만들것이다.
- 이를 위해서는 EFS에 요청할 수 있는 PV가 필요하고 이러한 PV의 프로파일 정보를 가진 스토리지 클래스가 필요하다.
- 따라서 EFS CSI 드라이버를 설치하고 설치한 드라이버를 이용하여 스토리지클래스를 생성하면 추후에 이 스토리지클래스를 이용하여 PVC를 생성하고 파드에 마운트하면 파드는 PVC에 의해 동적으로 생성된 PV가 EFS에 요청을 통해 스토리지와 상호작용을 할 수 있게 된다.
IAM정책 및 역할을 생성해서 이것을 부착한 서비스 계정을 생성한뒤 EFS-CSI 드라이버 설치과정에서 이 서비스 계정을 등록하여야 했다. 문제는 그냥 kubectl로 EFS-CSI드라이버를 설치해버린것이다. 이후 스토리지클래스와 PVC를 생성해서 ArgoCD에 배포를 해봤지만 당연히 접근권한이 존재하지 않아 EFS에 연동이 되지 않았다.
-> 이것을 해결하기 위해 클러스터를 다시 배포하였고, 클러스터 배포 YAML파일에서 IAM OIDC를 추가하여 EFS-CSI에 권한이 있는 서비스 계정을 생성하였다. 현재는 미리 추가해둔 클러스터 파일로 배포를 진행하였다.
# IAM OIDC & Service Account iam: withOIDC: true serviceAccounts: . . . - metadata: name: efs-csi-controller-sa namespace: kube-system wellKnownPolicies: efsCSIController: true . . .
- efs-csi에 권한(IAM 정책, IAM 역할)이 있는 서비스 계정 생성
- 해당 코드를 추가후 클러스터를 다시 배포하여 AWS콘솔에서 EFS스토리지가 생성되어 있는 것을 확인
- 위에서 생성한 서비스 계정을 이용하여 EFS-CSI 드라이버를 설치한다.
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
helm repo update
helm upgrade -i aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver \
--namespace kube-system \
--set image.repository=602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/eks/aws-efs-csi-driver \
--set controller.serviceAccount.create=false \
--set controller.serviceAccount.name=efs-csi-controller-sa
- 이후 EFS가 클러스터와 통신하기 위해서는 보안그룹이 필요한데 이 보안그룹을 생성하기 위해 클러스터의 vpc_id와 cidr_range를 변수로 저장해놓는다.
vpc_id=$(aws eks describe-cluster \
--name finalproject \
--query "cluster.resourcesVpcConfig.vpcId" \
--output text)
cidr_range=$(aws ec2 describe-vpcs \
--vpc-ids $vpc_id \
--query "Vpcs[].CidrBlock" \
--output text \
--region ap-northeast-2) -
AWS 콘솔에서 보안그룹 생성을 클릭해 [echo "$vpc_id"] 로 나온 vpc_id에 해당하는 vpc를 선택하고, 인바운드 규칙을 편집하여 유형에 NFS(TCP ,2049)선택 및 소스에는 [echo "$cidr_range"] 로 나온 ip값을 추가한다.
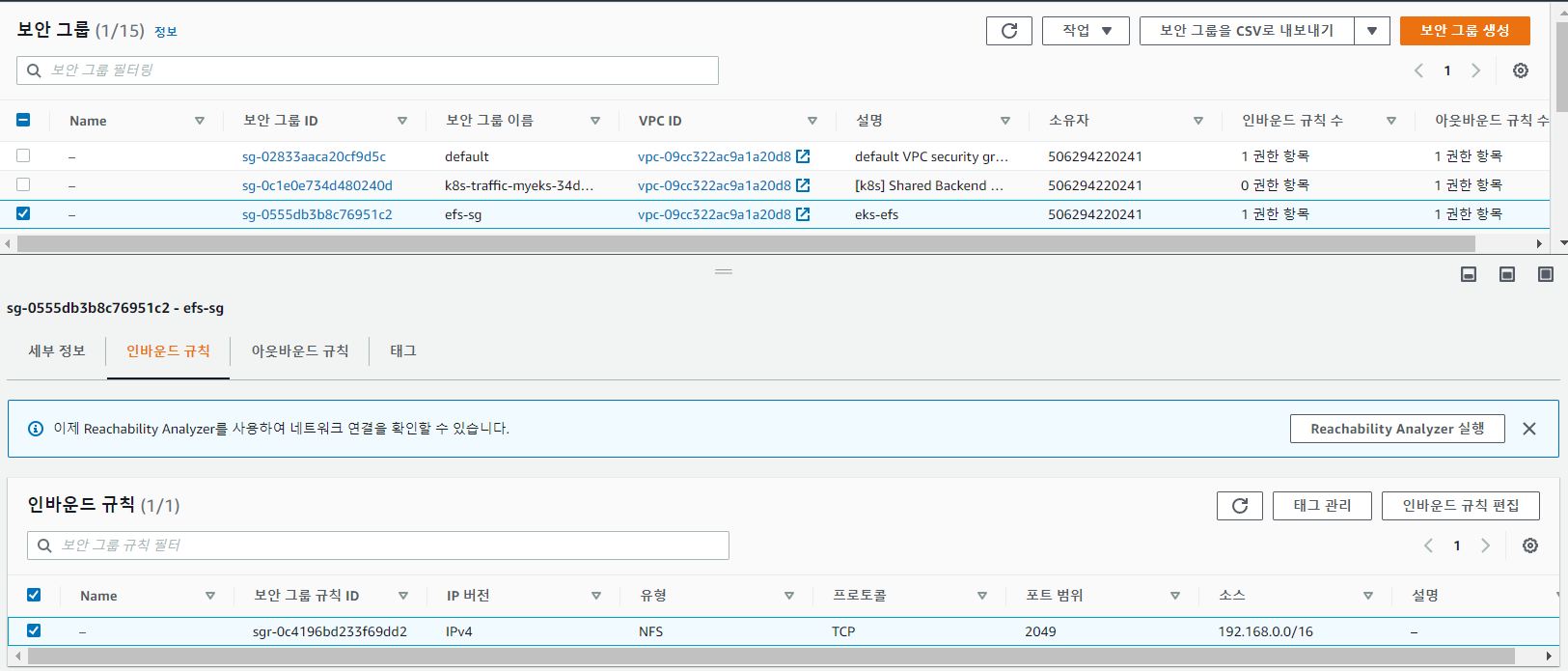
-
쉘에서 클러스터의 EC2인스턴스들의 서브넷 ID와 VPC ID를 출력한다.
aws ec2 describe-subnets \
--filters "Name=vpc-id,Values=$vpc_id" \
--query 'Subnets[*].{SubnetId: SubnetId,AvailabilityZone: AvailabilityZone,CidrBlock: CidrBlock}' \
--output table- 마찬가지로 EC2인스턴스의 IP를 출력한다.
- 출력된 인스턴스의 IP를 위의 테이블형태로 나온 CIDR과 비교해서 인스턴스가 어떤 서브넷에 포함되어 있는지 확인한다.
kubectl get nodes -o wide- 어떤 서브넷에 포함되어있는지 알았다면 서브넷 ID를 알 수 있고,
AWS콘솔에서 EFS에 들어가 파일 시스템을 생성한다. 스토리지 클래스를 standard로 선택하고 사용자지정을 클릭한다.
다음으로 넘어가 네트워크를 Mount할 때 서브넷 ID에 해당하는 AZ를 선택한다. 해당 가용영역의 서브넷에 위에서 생성했던 클러스터에 접속가능한 보안그룹을 부착한다. - EFS는 여러 AZ에 존재하는 모든 인스턴스가 동시에 접속할 수 있기 때문에 인스턴스가 존재하는 모든 서브넷의 가용영역과 서브넷 ID, 보안그룹을 선택해 Mount한다.
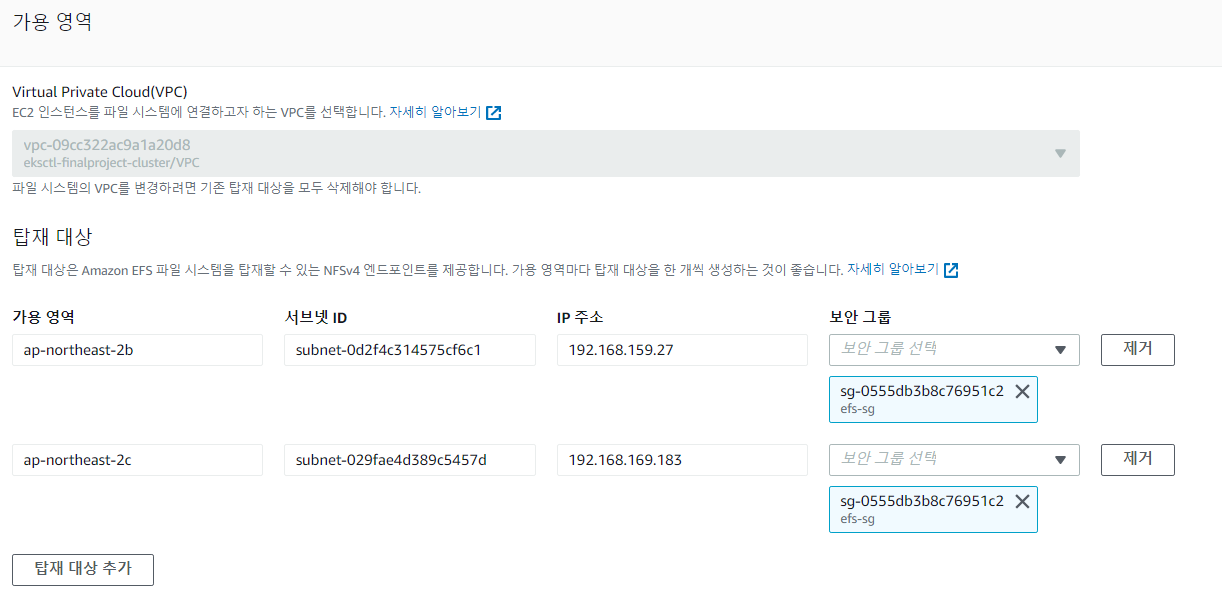
스토리지 클래스 생성
# efs-storage-class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: efs-sc
parameters:
directoryPerms: "700"
fileSystemId: fs-07b34570f35c4cc5d # 위에서 생성한 EFS의 ID추가
provisioningMode: efs-ap
provisioner: efs.csi.aws.com # EFS-CSI 드라이버 선택
reclaimPolicy: Delete
volumeBindingMode: ImmediatePVC 생성
# efs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc # 위에서 생성한 스토리지 클래스
resources:
requests:
storage: 1Gibackend - Deployment 수정
# back-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: back-deploy
spec:
selector:
matchLabels:
tier: backend
replicas: 2
template:
metadata:
labels:
tier: backend
spec:
containers:
- name: back-app
image: suhwan11/hello-world:49
ports:
- containerPort: 8080
protocol: TCP
volumeMounts: # 생성한 볼륨 마운트
- name: efs-volume
mountPath: /data
resources:
requests:
cpu: 200m
memory: 200M
volumes: # 위에서 생성한 PVC를 이용하여 볼륨 생성
- name: efs-volume
persistentVolumeClaim:
claimName: efs-pvc-
스토리지 클래스 , PVC, 수정한 Deployment를 ArgoCD를 이용해서 배포하면 아래와 같이 정상적으로 작동하는 것을 확인
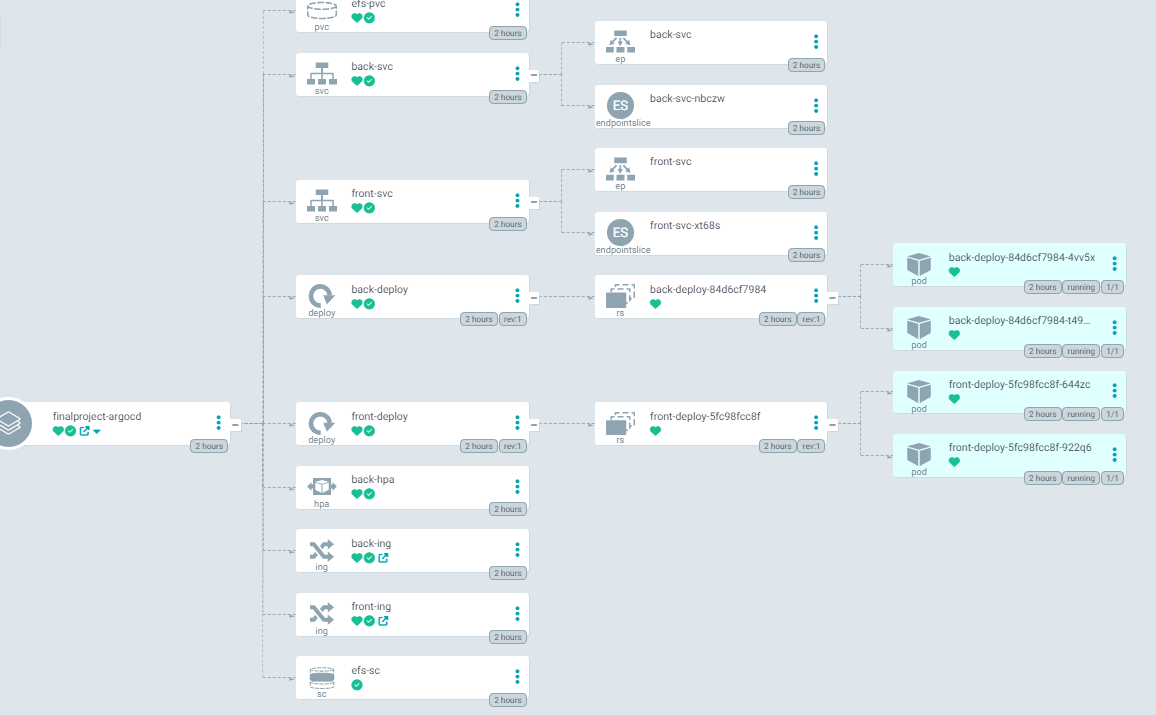
-
서로 다른 AZ에 노드가 각각 존재하고 각 노드에는 디플로이먼트로 배포된 백엔드 파드가 각각 하나씩 있다.
-
위의 파드에서 data디렉터리에 작성했던 test.txt파일이 다른 AZ에 있는 노드의 파드에 접속하여 확인해보면 data 디렉터리에 test.txt파일이 공유되어 존재하는 것을 확인할 수 있다.
kubectl exec -it < 파드이름 > -- sh
cd /data
cat > test.txt
# text입력 후 exit
다른 노드의 파드에 접속
kubectl exec -it < 다른 노드의 파드이름 > -- sh
cd /dataHPA
HPA를 사용하기 위해서는 Metrics server 애드온을 설치하여야 한다. 이는 클러스터를 배포할때 설정해두었다. 또한 hpa를 사용하기 위해 deployment에 request값을 설정해줘야 한다.
# back-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: back-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: back-deploy # backend Deployment와 연결
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70Cluster Autoscaler
-
HPA로 파드의 CPU 평균 사용률이 높아짐에 따라 노드(= EC2인스턴스)에 배치되는 파드의 개수를 늘렸다면, 파드의 개수가 늘어남에 따라 노드가 자신의 자원을 가지고 늘어난 파드의 request값을 보장해준다 .
-
이때 늘어난 파드의 request값을 더이상 노드가 보장해주지 못한다면 노드를 늘려서 새로운 노드에 파드를 배치해야한다.
-
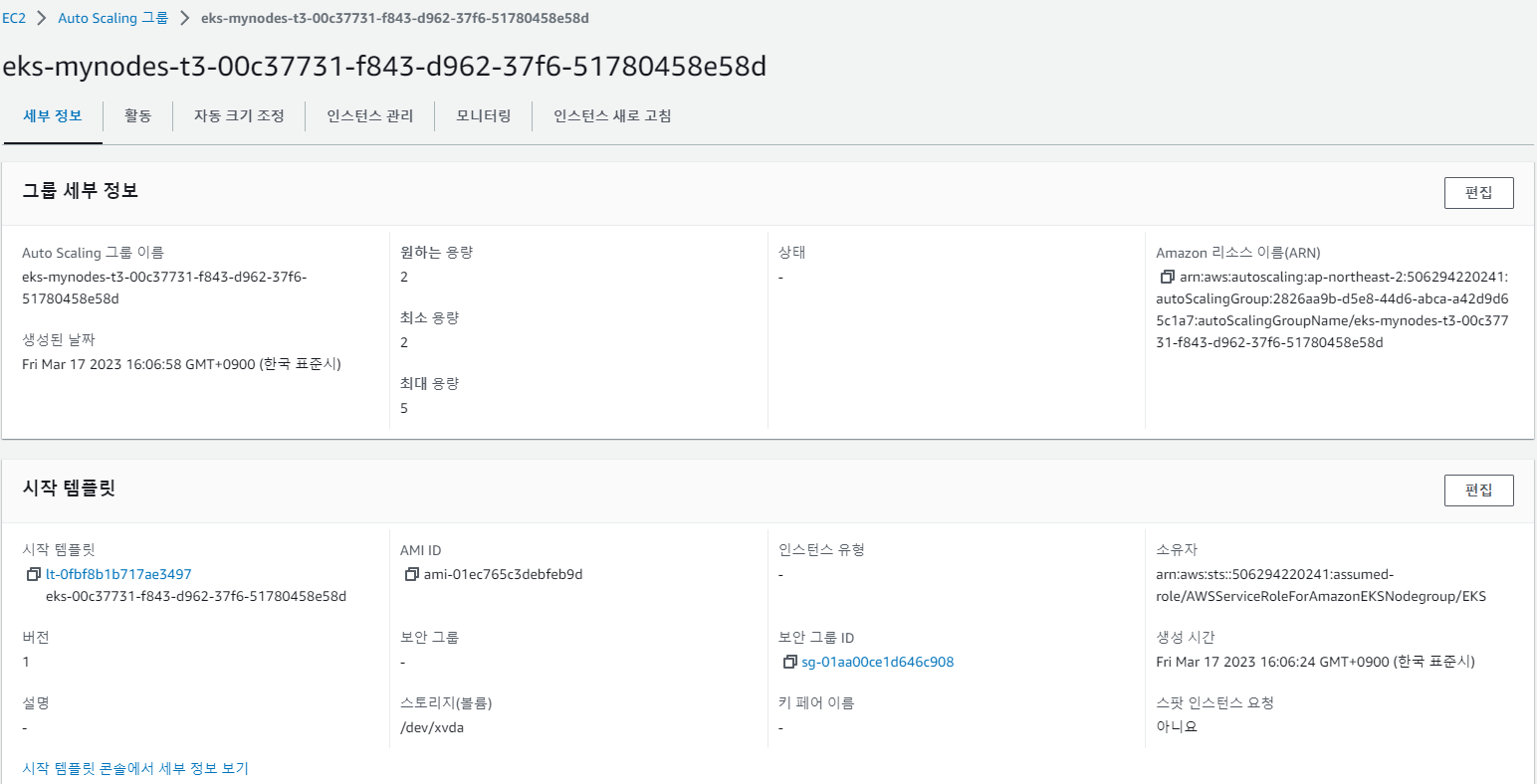
이것을 위해 Auto Scailing Group을 생성한다.
- EC2인스턴스의 Auto Scailing이 가능하게 하기위해서는 Cluster Autoscaler 애드온을 설치하여야 한다. 이는 클러스터를 배포할때 설정해두었다.
-
min 값은 2 , max 값은 5 , desired 값은 2로 지정하였다.
- 즉, 현재 배포된 클러스터의 노드의 개수는 2개이고, 2개이하로는 scale down되지 않게 설정하였으면, 최대 늘어날 수 있는 노드는 5개로 설정하였다.
📝 회고
여러 사람이 동일한 클러스터에 연결해서 작업을 하다보니 한 사람이 말을 안하고 어떤 것을 지우거나 설치하게 되면, 다른 사람이 작업할때 인지를 못하고 중복으로 작업하거나, 서비스가 꼬여버려서 더이상 클러스터를 이용할 수 없게 되었다.
따라서 하나의 클러스터의 동일한 환경에서 작업을 하되, 유저 계정을 각각 생성해서 RBAC을 통해 권한을 나누어 작업을 하면 여러 사람이 동일한 환경에서 작업을 할 수 있으면서 동시에 각자의 구역을 나누어서 작업을 할 수 있을 거 같아서 훨씬 효율적일 것이다.
