
오랜만에 글을 작성한다.
이번에는 취향저격 프로젝트에서 사용했던 Doc2Vec에 관하여 간단하게 설명하고자 한다.
Doc2Vec을 이용하기 시작할 때 부터 프로젝트의 방향성을 살짝 바꿔서 기존의 사용자 입력을 장르로 구분하는 것에서 사용자의 입력을 영화의 줄거리와 비교해서 가장 유사한 줄거리를 가진 영화를 추천하는 형식으로 방향을 바꿨다.
- 사용자 입력 -> 장르 구분 -> 장르 내에서 영화 추천
- 사용자 입력 -> 영화 줄거리 비교 -> 유사한 줄거리를 가진 영화 추천
결과부터 말하자면 이번 프로젝트랑 Doc2Vec이 적합하지 않았던 건지 아니면 내가 학습을 잘못 했는지 결과가 좋지 못했다. 사용자가 문장을 입력하면 전혀 비슷하지 않은 다른 영화가 나왔다.
전체적인 코드는 넘어가고 Doc2Vec에 관하여 간단하게 설명하고, 다음 포스팅에서 최종적으로 만든 방식을 포스팅 한 후 취항저격 프로젝트에 관한 포스팅은 마치고자 한다.
Doc2Vec
Word / Document embedding (Word2Vec / Doc2Vec)
먼저 Doc2Vec을 공부하면서 참고했던 블로그를 소개 해주고자 한다. 개념이 너무 어려워서 위의 블로그만큼 설명하기는 힘들 것 같고, 잘 정리 돼 있어서 공부하는데 많은 도움이 됐던 블로그이다.
간단하게 말하면 Doc2Vec은 문서를 벡터화 시키는 건데, Word2Vec이 단어의 벡터화 였다면 Doc2Vec은 문장 혹은 문단, 문서까지 벡터화 시킬 수 있도록 만들어진 것이다.
취향저격 프로젝트에서는 [영화제목1] - [문장1], [영화제목1] - [문장2]이런식으로 데이터를 만들었다. 한 영화와 그 영화에대한 줄거리 문장들인 것이다. 태깅은 영화제목이 될 것이므로 데이터를 만든 후 학습 시켰다.
결과는 좋지 않았다.
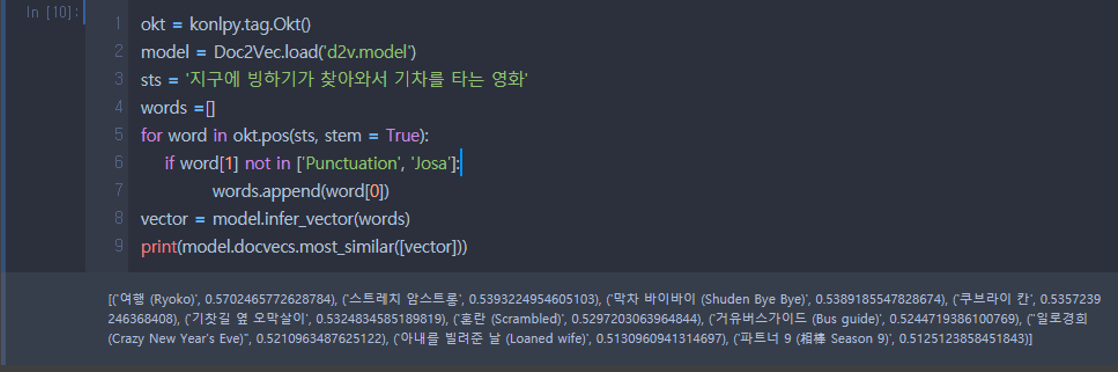
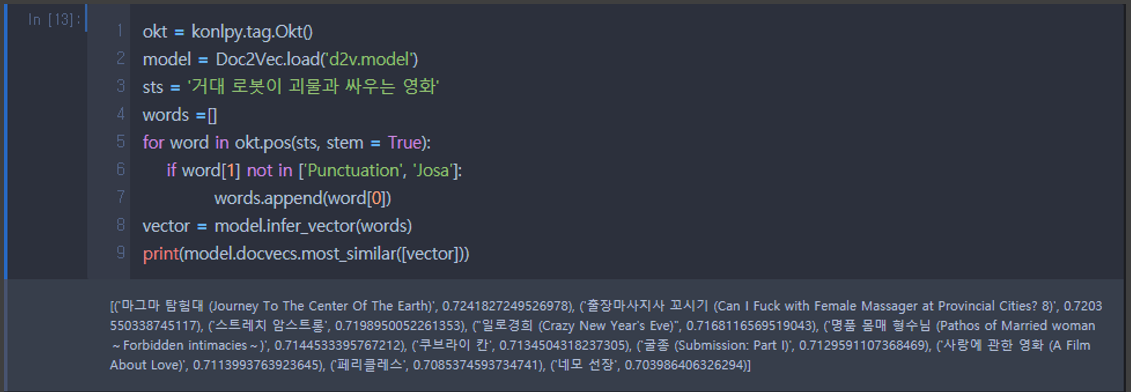
Doc2Vec을 이용했을 때의 결과 사진이다.
영화 제목만이긴 하지만 제목만 봐도 입력한 문장과 연관이 없어보인다.
아마 영화 줄거리 데이터가 좋은 데이터가 아니라 그런 것 같다.
