RDD : Resilient Distributed Data, 단순하게는 분산되어 존재하는 변하지 않는 데이터 요소들의 모임이다
- RDD는 여러 머신으로 구성된 클러스터 환경에서의 분산처리를 전제로 설계되었고, 그 내부는 파티션이라는 단위로 나뉜다
RDD 특징
-
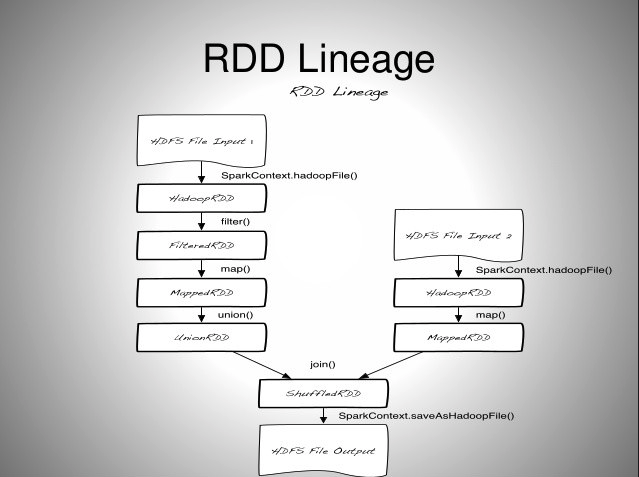
RDD는 위와 같은 Lineage를 가진다
-
RDD는 불변의 특성을 가지기 때문에 특정 동작을 위해 기존 RDD를 변형한 새로운 RDD를 생성한다
-
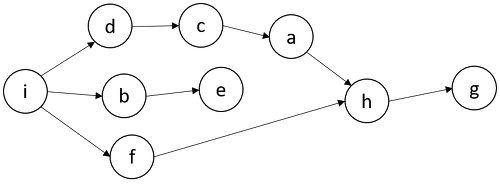
특정 동작에 의해 생성되는 RDD는 DAG(Directed Acyclic Graph)의 형태를 가진다 (아래의 형태)
-
특정 RDD 관련 정보가 유실되었을 경우, 그래프를 복기하여 자동으로 복구 가능하다
-
덕분에 Fault-tolerant 하다는 특징이 있다
RDD 동작 원리
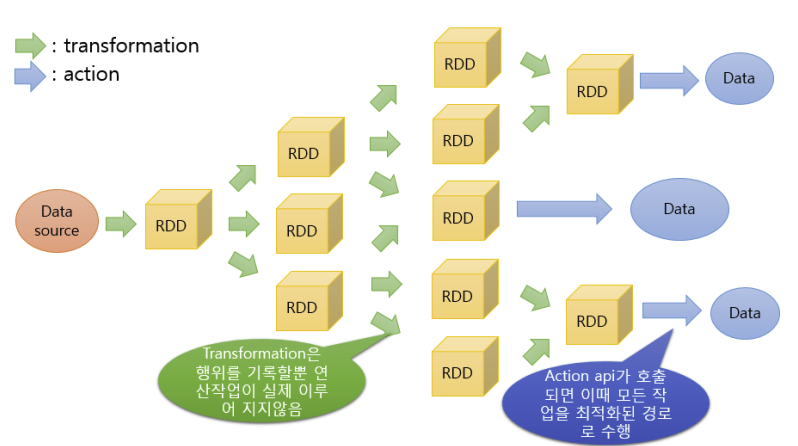
이미지 출처: https://artist-developer.tistory.com/17?category=962892
- RDD는 기본적으로 Lazy-Evaluation(여유로운 연산)으로 처리한다
- Action 연산자를 만나기 전까지는 연산을 하지 않는다
Transformation & Action
Transformation
- 기존 RDD에서 새로운 RDD를 생성하는 동작 => 리턴값이 RDD

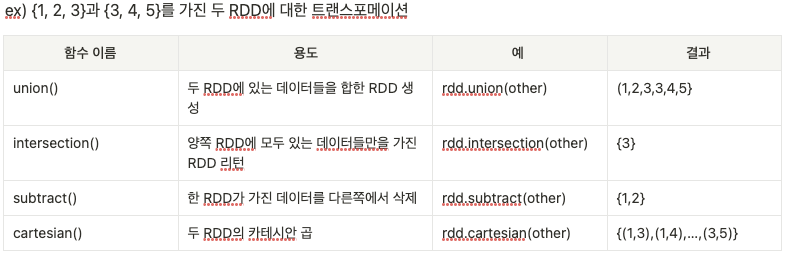
Action
- 드라이버 프로그램에 최종 결과 값을 돌려주거나 외부 저장소에 값을 기록하는 연산 작업
- 새로운 액션을 호출할 때마다 전체 RDD가 처음부터 계산됨
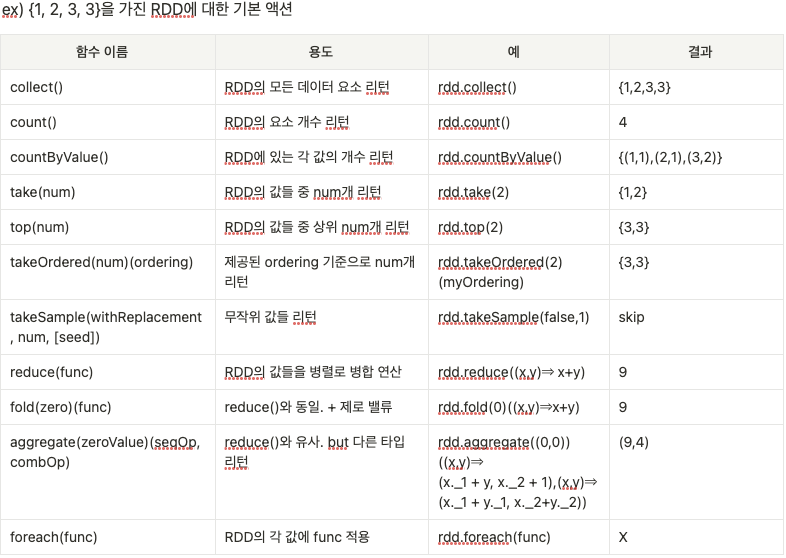

위의 사진을 보면, RDD Python의 성능이 제일 뒤처진다. 주언어가 파이썬인 나로써는 RDD는 개념 정리만 해두고 필요할 때까지는 묻어둘 것 같다..

데이터 엔지니어로 전향중인 백엔드 개발자입니다