1. Inf1이란?
- AWS에는 Inf1이라는 인스턴스 타입이 존재한다.
- Inf1은 aws의 inference 전용 칩인 NeuronCore을 사용한 기계학습 추론용으로 나온 인스턴스이다
- 특별한 목적(기계학습)을 가지고 나온 인스턴스인 만큼, 머신러닝 모델 추론에 특화 되어 싸고 빠르게 모델 서빙을 할 수 있다고 홍보하고 있다.
1-1 Inf1 특징
- aws의 inference 전용 칩인 NeuronCore을 사용한 칩
- NeuronCore가 잘 처리하는 일
- AWS neuron SDK를 썼을때도 효과적임
- 높은 성능의 througput과 latency
- 같은 가격의 gpu 장비보다 여러 모델(yolo, bert 등) 기준으로 더 빠르고 더 많은 예측을 할 수 있다.
1-2 Neuron SDK란?
AWS Neuron SDK을 통해 AWS inf1 chip이 지원하는 neural network operators을 실행할 수 있다.AWS Neuron SDK을 통한 연산이 아니라면 CPU를 사용하게 된다.
즉 Inf1을 잘 사용하기 위해서는 모델 추론 부분이 무조건
AWS Neuron SDK을 활용한 형태이여야 한다.
2. INF1은 싸다?
2-1 홍보자료
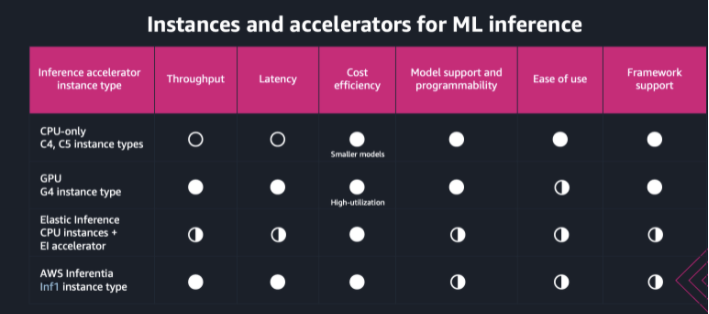
- 가격홍보시 주로 gpu 인스턴스인 G4 instance 대비 45프로 절감 했다는 식으로 말한다.
- 하지만 만약에 모델 서빙을 위해 C5를 쓰고 있다면 정말 싸게 쓸 수 있는지는 테스트해봐야 한다.
- 위 표는 aws 엔지니어가 만들었는데 small model에서는 C타입의 cost efficiency가 있다고 언급하고 있다.
- Small model일 경우 오히려 inf1에 비해 밀릴 수도 있다.
2-2 Spot
- inf 1 장비의 스팟 중단 비율은 최고레벨인
>20%이다. - 중단 비율 참고 : https://aws.amazon.com/ko/ec2/spot/instance-advisor/
- 온디맨드에서 50프로 이상의 비용절감을 보여도 만약 spot을 효율적으로 쓰지 못 할 경우 의미가 없을 수 있다.
3 Neuron Core란?
3-1 Neuron Cores
- 지원하는 데이터 타입(FP16 , BF 16 등)이 있어서 FP32가 들어오면 BF16으로 강제 타입 캐스팅등을 한다. INT8은 지원하지 않는다
Batching (—-batch_size 파라메터 model compile시 지정함)
- 데이터를 주어진 배치단위로 처리함
- 필요한 파라메터를 들고와서 모든 배치가 사용한 후 다음 layer 계산에 필요한 파라메터를 가져온다고 함
- 배치사이즈 정하는법 :Neuron Batching - AWS Neuron documentation
pipelining (—-num-neuroncores 파라메터 model compile 시에 지정함)
- 여러개의 neuron core가 한번에 작업을 처리함
- 설정에 따라 모델이 처리하는 latency에 차이가 있기 때문에 적절한 설정이 필요하다 한다.
- 파이프라이닝 설정법 : NeuronCore Pipeline - AWS Neuron documentation
3-2 세팅별 성능에 차이가 존재함
- 이 사이트의 자료에서 각종 옵션별 실험을 진행한것이 있다. Neuron core의 세팅 값들을 어떻게 설정하느냐에 따라서 성능차이가 존재한다.
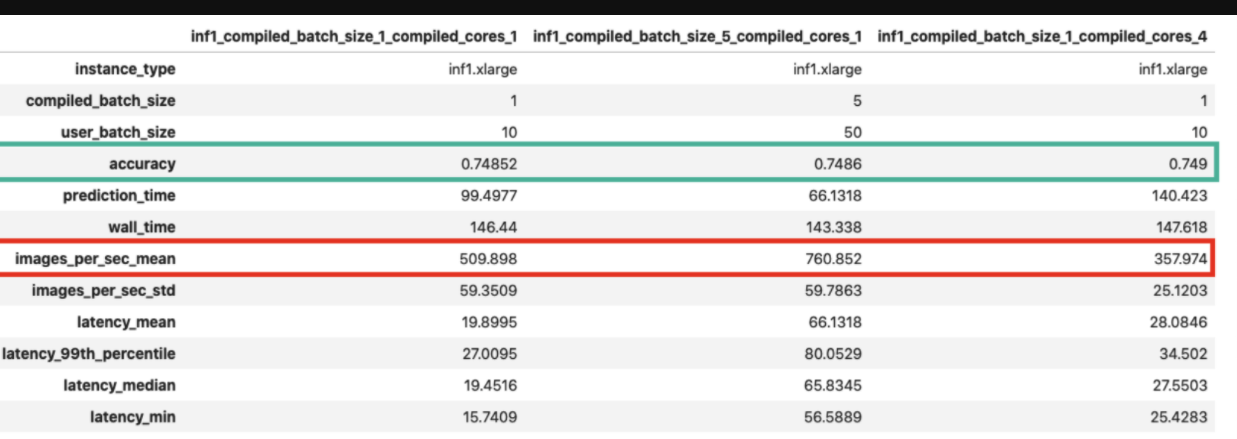
이미지 참고 : https://towardsdatascience.com/a-complete-guide-to-ai-accelerators-for-deep-learning-inference-gpus-aws-inferentia-and-amazon-7a5d6804ef1c
4. Nueron SDK 적용하기
Tensorflow
Inf1을 잘 사용하기 위해서는 모델 추론 부분이 무조건
AWS Neuron SDK을 활용한 형태이여야 한다.
-
AWS에서는 tensorflow, pytorch와 같은 library에
AWS Neuron SDK를 적용하여 tensorflow.neuron(tfn)이라는 것을 개발했다. -
기존 코드에서 tensorflow.neuron 을 추가해주고 간단한 작업을 몇번 거치면 기존의 tensorflow모델에
AWS Neuron SDK를 적용할 수 있다. -
예제 코드 (코드 복붙 해온 AWS 공식 사이트)
import tensorflow as tf
import tensorflow.neuron as tfn
input0 = tf.keras.layers.Input(3)
dense0 = tf.keras.layers.Dense(3)(input0)
model = tf.keras.Model(inputs=[input0], outputs=[dense0])
example_inputs = tf.random.uniform([1, 3])
### 이부분에서 바꿔줌
model_neuron = tfn.trace(model, example_inputs) # trace
model_dir = './model_neuron'
model_neuron.save(model_dir)
model_neuron_reloaded = tf.keras.models.load_model(model_dir)Tfserving
- 아래 링크를 참고하면 Tfserving에도 적용할 수 있다.
5 참고자료 및 사이트
- https://aws.amazon.com/ko/ec2/instance-types/inf1/
- https://pages.awscloud.com/rs/112-TZM-766/images/AL-ML for Startups - Select the Right ML Instance.pdf
- https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/tensorflow-neuron/index.html
- https://aws.amazon.com/ko/blogs/aws/amazon-ecs-now-supports-ec2-inf1-instances/
- https://towardsdatascience.com/choosing-the-right-gpu-for-deep-learning-on-aws-d69c157d8c86
- https://towardsdatascience.com/a-complete-guide-to-ai-accelerators-for-deep-learning-inference-gpus-aws-inferentia-and-amazon-7a5d6804ef1c
- https://perspectives.mvdirona.com/2018/11/aws-inferentia-machine-learning-processor/
- https://github.com/aws/aws-neuron-sdk/
- https://awsdocs-neuron.readthedocs-hosted.com/en/v1.16.0/neuron-guide/neuron-frameworks/tensorflow-neuron/api-tracing-python-api.html

Machine Learning Engineer: recsys, mlops