Label-Efficient Semantic Segmentation with Diffusion Models (ICLR 2022)
Semantic parts Segmentation
이번 포스팅에서는 Diffusion Model 을 사용하여 Computer Vision task인 Semantic Segmentation 문제를 푼 Task를 알아볼 것이다.
이 논문에서는 diffusion model이 segmentation에서도 좋은 성능을 낼 수 있음을 증명서고 Dataset이 적은(scarce) 경우에도 잘 될 수 있다는 것을 증명한 논문입니다.
- 저자들은 reverse diffusion process의 Markov 단계를 수행하는 네트워크에서 intermediate activation을 조사합니다.
- intermediate activation 에서 나온 정보를 가져와 semantic segmentation task를 수행합니다.
- DatasetGAN, Self supervised learning method 등 의 representation model의 intermediate activation 을 활용한 방법들과 비교 분석한 논문입니다.
Method
Representation from diffusion models
- Extracting representation
The UNet’s intermediate activations are then upsampled to with bilinear interpolation. This allows treating them as pixel-level representations of
Representation Analysis
- DDPM은 U-Net 구조를 사용하는 데 이 때 어떤 block의 feature를 가져와야 효율적으로 semantic 한 정보를 가져올 수 있는지 조사합니다.
- Decoder block 만 가져오는 이유 : skip connection으로 이미 encoder의 feature를 가져왔기 때문에에 굳이 또 가져와서 parameter 수를 늘릴 필요가 없기 때문입니다.
- LSUN-Horse(21), FFHQ(34) dataset에서 조금만 가져와 분석합니다.
- MLPs are trained on 20 images and evaluated on 20 hold-out ones. (train / test 20 : 20)
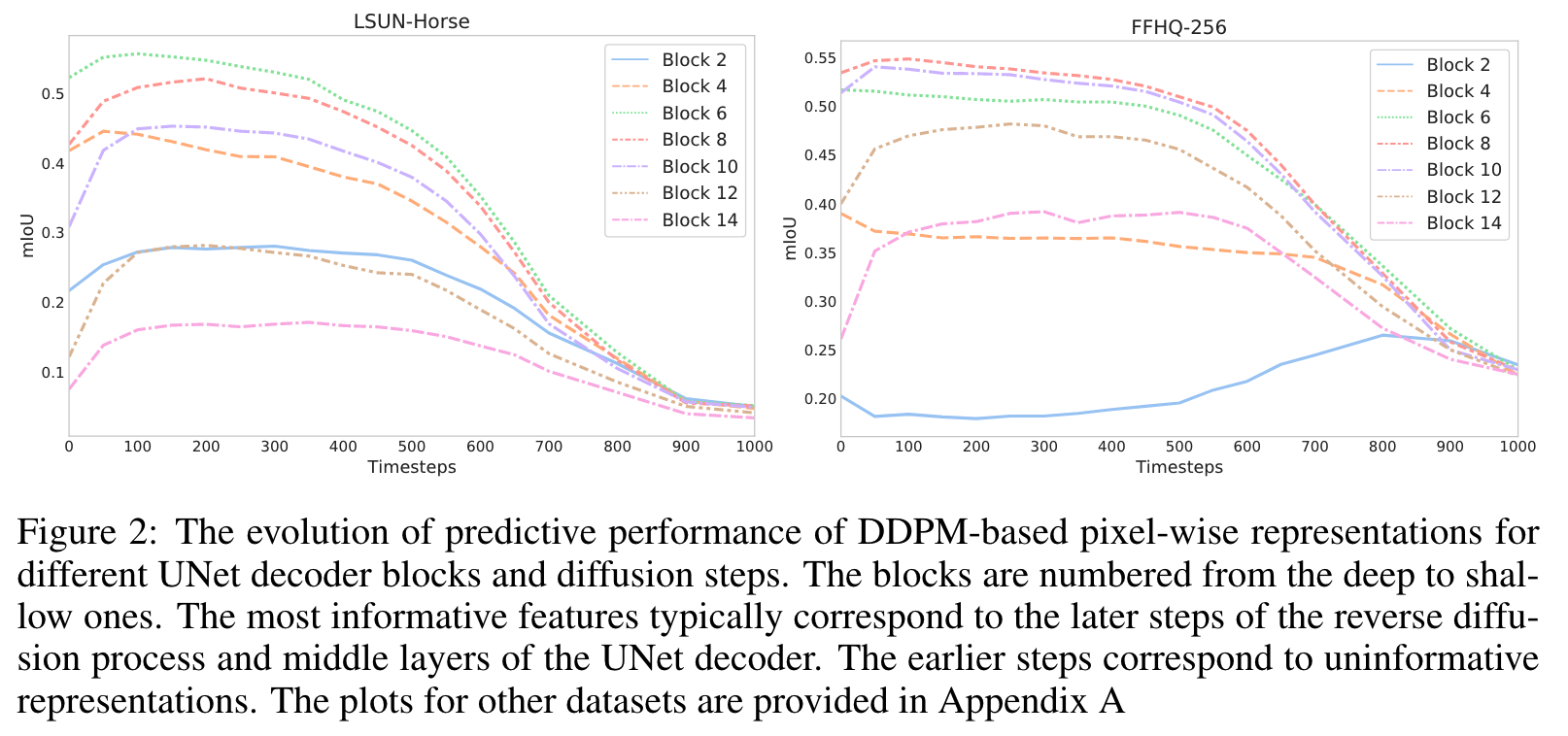
각 block, 여러 timestep에서 semantic segmentation 성능을 뽑아본 지표
- 위 지표를 보면 middle layer에서의 feature를 활용하는 것이 좋아보입니다.
- reverse diffusion process의 이후 단계에 해당하는 featyre는 일반적으로 의미 정보를 보다 효과적으로 본다.
- 대조적으로 초기 단계에 해당하는 것은 일반적으로 정보가 없습니다.
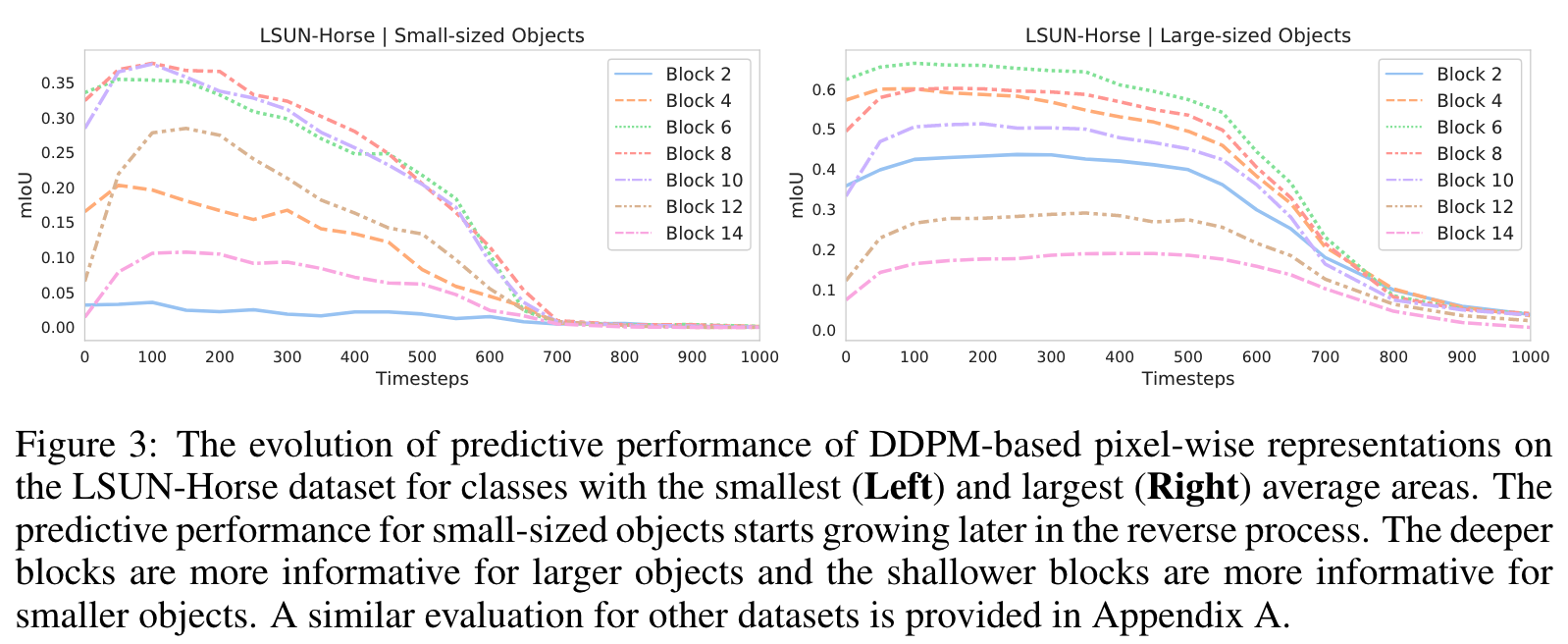
- small-sized & large-sized semantic class을 고려해서 어떤 block이 좀 더 정보를 잘 잡는지 파악합니다.
- small size은 얕은 block에서 Large size은 깊은 block에서 semantic한 의미를 잘 찾아냅니다.
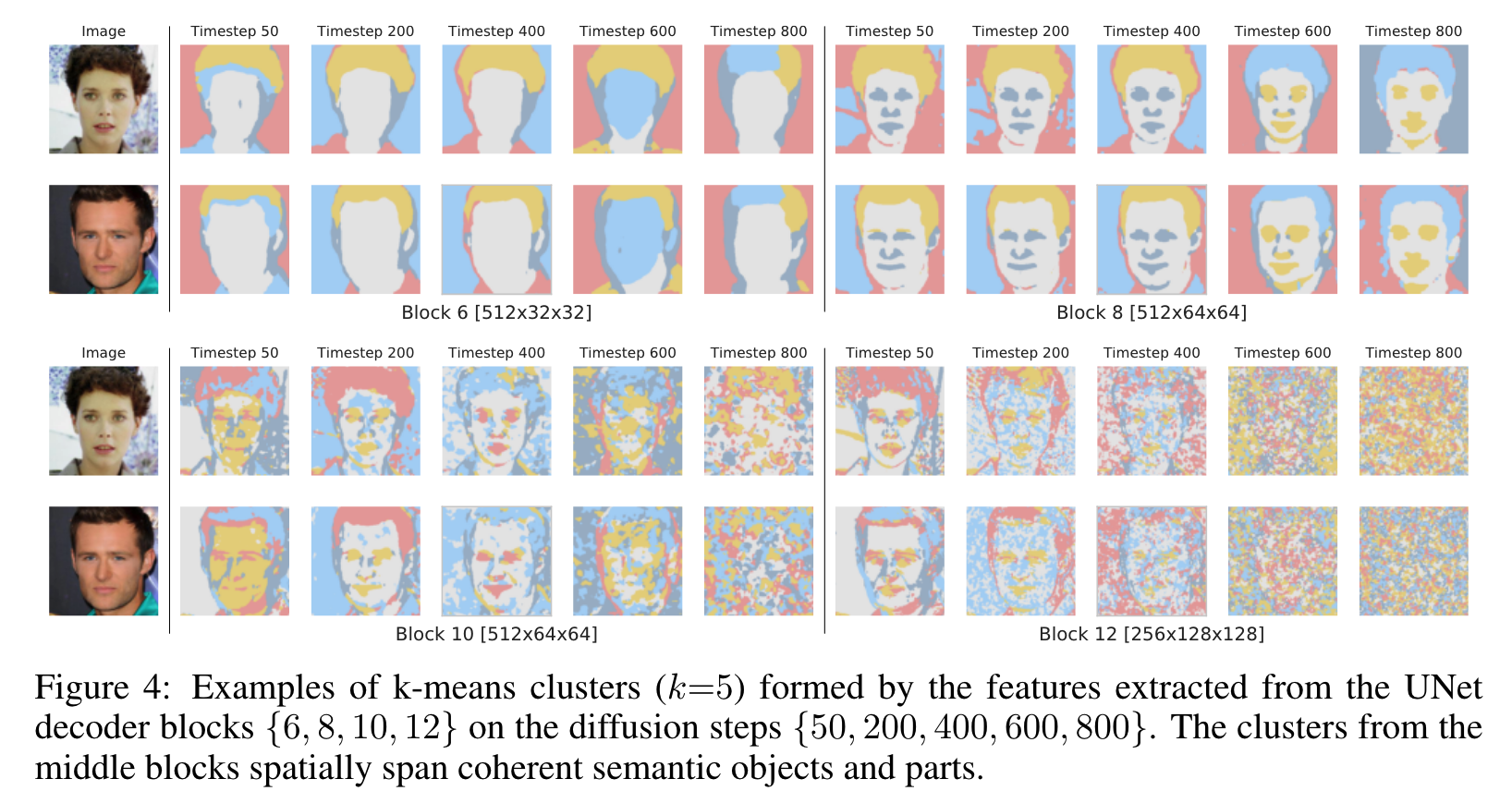
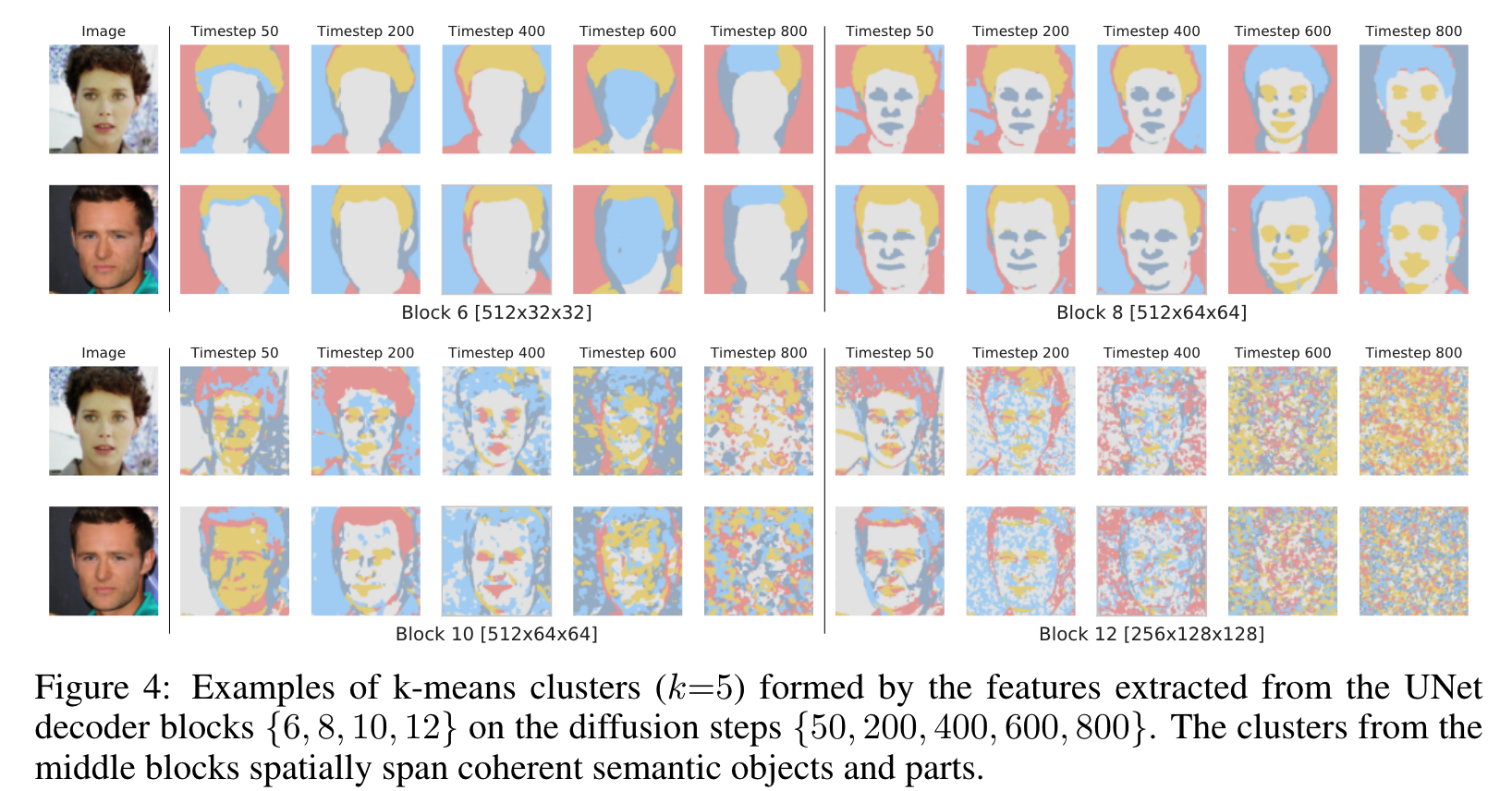
- : coarse(조잡)한 semantic한 mask만 제공합니다.
- : fine grained face part는 잘 찾지만fragmentation에서의 의미는 제대로 못잡습니다.
- process 초기 단계에서 DDPM 샘플의 전역 구조가 아직 나타나지 않았기 때문에 이 단계에서 분할 마스크를 예측하는 것이 거의 불가능하다는 사실을 보여줍니다. ()
DDPM-Based Representations for Few-Shot Semantic Segmentation
Figure1 에서의 Arichitecture로 학습!
- 특정 도메인에서 레이블이 지정되지 않은 많은 수의 이미지 을 사용할 수 있으며
- training images groundtruth
- Semantic mask 가 제공됩니다.
학습 방법
- Training a diffusion model on the whole
- diffusion model은 UNet block의 하위 집합과 diffusion step 를 사용하여 레이블이 지정된 이미지의 픽셀 수준 표현을 추출하는 데 사용됩니다.
- 이 작업에서 사용되는 block은 ={5, 6, 7, 8, 12}
- reverse diffusion process step ={50, 150, 250}의 representation을 사용합니다.
- 각 dataset에 따라 위 조건의 따로 조정하진 않았다.
- 모든 block 와 step 에서 추출된 representation feature들은 upsamping하여 concat 시깁니다.
- pixel level representation의 차원은 8448입니다.
- 그런 다음DatasetGAN에 따라 이러한 feature vector에 대해 독립적인 다층 퍼셉트론(MLP)의 앙상블을 훈련합니다.
- 테스트 이미지를 분할하기 위해 DDPM 기반 픽셀 단위 representation을 추출하고 이를 사용하여 Ensenble에 의한 pixel label을 예측합니다. 최종 예측은 vote로 결정.
EXPERIMENTS
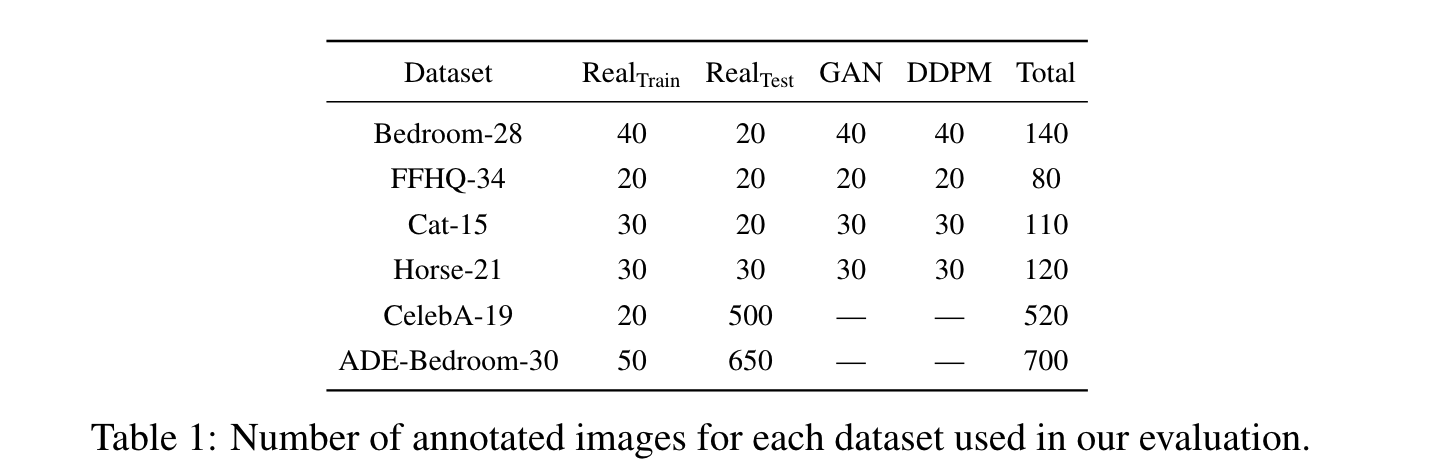
Dataset
- Bedroom-28, FFHQ-34, Cat-15, Horse21
- dataset-class 개수
- LSUN, FFHQ에서 추출
- ADE-Bedroom-30 : a subset of the ADE20K dataset , where we extract only images of bedroom scenes with 30 most frequent classes.
- CelebA-19 is a subset of the CelebAMask-HQ dataset (Lee et al., 2020), which provides the annotation for 19 facial attributes
- All images are resized to 256 resolution.
Compared other methods
- DatasetGAN : GAN에 의해 생성된 pixel-level feature를 활용합니다. 첫번째로 GAN 생성 이미지에 주석을 답니다. 두번째로 생성한 이미지의 latent code를 사용하여 pixel-level representation으로 고려하여 intermediate generator activation을 얻습니다. 세번째로 이러한 representation이 주어지면 classifier는 각 pixel에 대한 semantic label을 예측하도록 훈련됩니다. 마지막으로 이 classifier는 새로운 synthetic GAN images을 labeling하는 데 사용되며, 이 이미지는 DeepLabV3 segmentation 모델의 훈련 세트 역할을 합니다.
- DatasetDDPM : DatasetGAN에서 GAN을 diffusion model로 대채한 것이다.
- MAE : Self Supervised Learning 에서 최신 sota 중 하나 이다. 누락된 patches를 재구성하기 위해 denosing autoencoder를 학습합니다.
- SwAW : 이 것도 최신 Self Supervised learning mehtod 중 하나이다.
- GAN Inversion : real image에서 latent code를 뽑아내어서 조작하는 아이디어를 가진 논문입니다. 우리는 여기서 intermediate generator activations르 가져와 pixel-level representation으로 활용합니다.
- GAN Encoder : Inversion 에서 LSUN에서 image를 재구성하는데 어려움을 격기 때문에 encoder의 activation을 가져온것입니다.
- VDVAE : Autoencoder 모델에서 최신 SoTA입니다. intermediate activation은 encoder와 decoder 모두에서 추출되어 연결됩니다. LSUN dataset로 pre-trained model이 없지만 FFHQ-256에서 공개적으로 사용 가능한 checkpoint에서만 이 모델을 평가합니다. VAE는 여전히 LSUN에서 GAN 및 DDPM보다 훨씬 성능이 좋지 못합니다.
- ALAE : StyleGANv1 Generator를 가져와 adversarial training에 encoder를 추가합니다. encoder model에서 feature을 추출합니다. 평가에서는 LSUN-Bedroom 및 FFHQ-10245에서 공개적으로 사용 가능한 모델을 사용합니다.
Generative pretrained models
실험에서 StyleGAN2 모델을 사용하고 최신 DDPM기반 방법인 pretrained ADM 모델을 사용합니다.
- FFHQ-256에 대한 pretrained model이 없기 때문에 [코드](https://github.com/openai/guided- diffusion) 방식으로 학습합니다.
- ADEBedroom-30 데이터 세트에 대한 평가를 위해 LSUN-Bedroom에서 pretrained model(baseline 포함)을 사용합니다.
- Celeba-19의 경우 FFHQ-256에서 훈련된 모델을 평가합니다.
Main Results
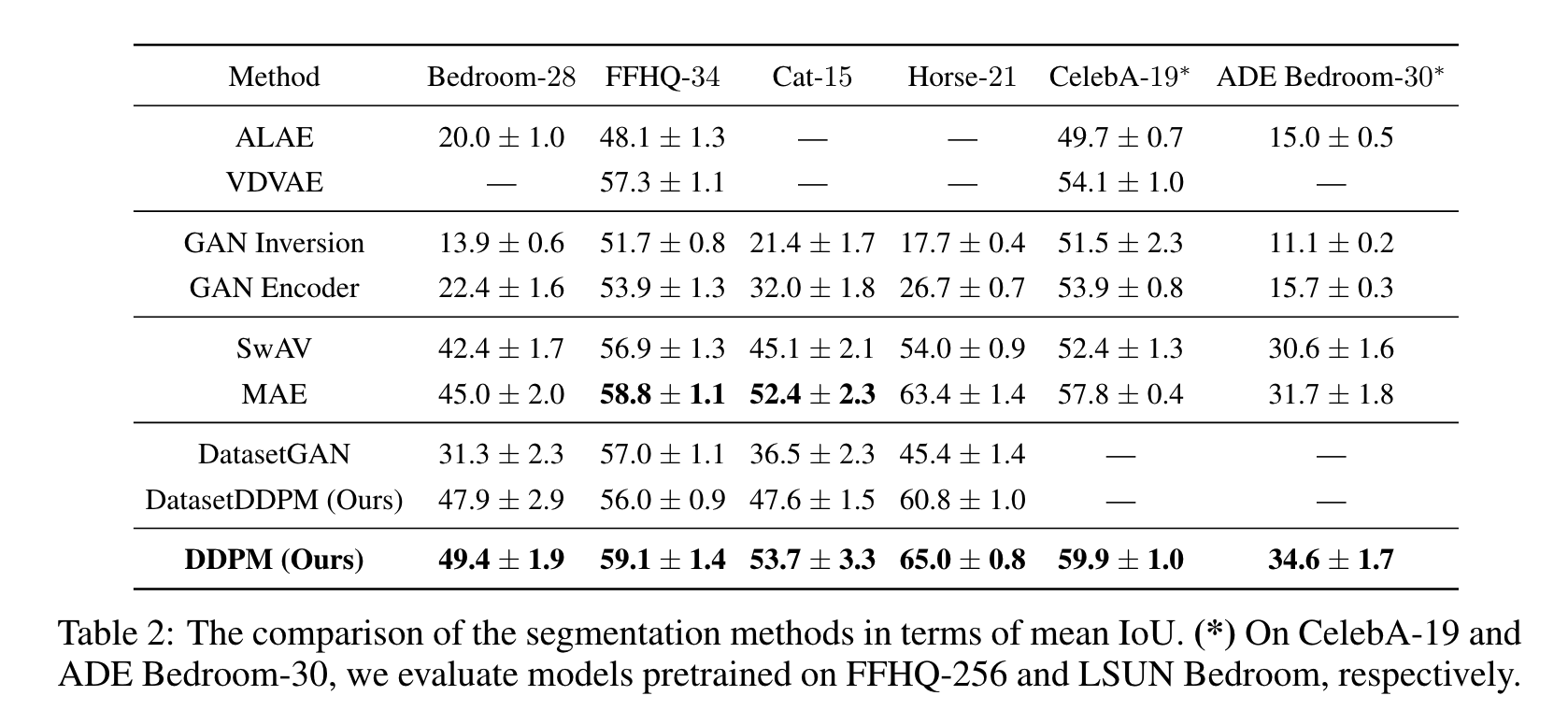
- DDPM representations이 성능에 많은 영향을 준다는 것을 알 수 있다.
- MAE가 baseline 중 가장 견줄만한 성능을 내고 있다.
- SwAV가 비교적 낮은 성능을 보이는 데 이것은 discriminative 방식으로 훈련되는 것이 세밀한 semantic segmentation에서는 필요한 detail을 억제할 수 있다는 사실을 알 수 있습니다. 이 결과는 paper의 연구 결과에 나온 것과 동일하며 semantic segmentation을 할 때에는 차선책이 필요하다는 것을 보일 수 있다.
- DatasetDDPM이 DatasetGAN보다 성능이 더 좋은데 이것은 DDPM이 좀 더 real data와 synthetic과 domain gap이 작다는 것을 의미합니다.

Discussion
The effect of training on real data
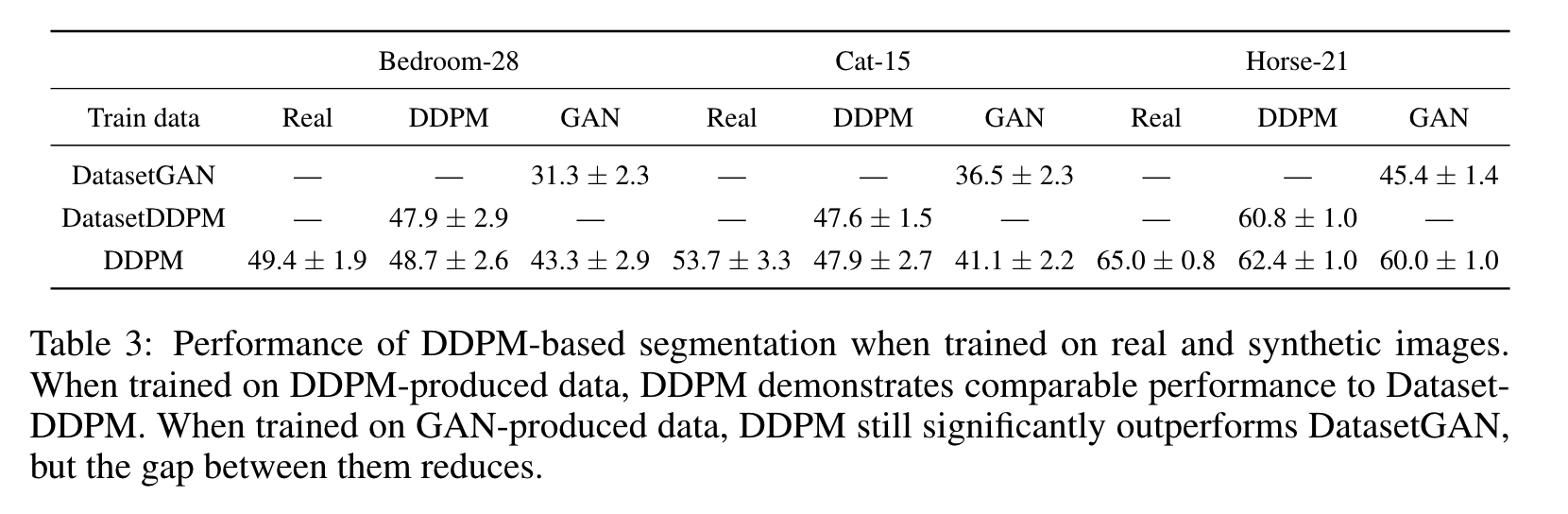
이번 내용은 실험에서 real 또는 synthetic 데이터에 대한 학습으로 인한 성능 저하를 quantify합니다.
일반적으로 Synthetic 이미지를 학습 이미지로 사용한다는 것은 real 이미지보다 less natural, diverse, lack objects of particular 할 수 있다.
또한 Synthetic 이미지는 사람이 annotation하는 것도 object가 왜곡될 수 있고 특정 class에 할당하기에 더 어려울 수 있습니다.
Table. 3은 real, DDPM-produced 및 GAN-produced 생성 Annotationed 이미지에 대해 훈련된 DDPM 접근 방식의 성능을 이야기합니다.
- real 이미지에 대한 training은 generative 모델의 정확도가 여전히 상대적으로 낮은 도메인(예: LSUN-Cat)에서 매우 유익합니다.
- DDPM 방법을 합성 이미지로 학습하면 성능이 DatasetDDPM과 동등해집니다.
- 반면에 GAN으로 생성된 샘플을 학습할 때 DDPM은 DatasetGAN보다 훨씬 뛰어난 성능을 보입니다. 이것이 DDPM이 GAN에 비해 더 의미론적으로 가치 있는 pixel-wise representation을 제공한다는 사실 때문이라고 본 저자들이 생각한다고 합니다.
Sample-efficiency

이 실험에서는 주석이 적은 데이터를 사용할 때 방법의 성능을 평가합니다. 우리는 표 4의 4개 데이터 세트에 대한 mIoU를 제공합니다. 중요한 것은 DDPM이 여전히 훨씬 적은 감독을 사용하여 Table 2의 대부분의 기준선을 능가할 수 있다는 것입니다.
\<!--
The effect of stochastic feature extraction
여기서는 우리의 방법이 섹션 3.2에서 설명한 확률적 특징 추출의 이점을 얻을 수 있는지 조사합니다. 노이즈 ~N(0, I)이 한 번 샘플링되고 훈련 및 평가 동안 모든 시간 단계 t에 대해 xt를 얻기 위해 (2)에서 사용되는 결정적 사례를 고려합니다. 그런 다음 이를 다음과 같은 확률적 옵션과 비교합니다. 첫째, 서로 다른 시간 단계 t에 대해 서로 다른 t가 샘플링되고 교육 및 평가 중에 공유됩니다. 둘째, 각 교육 반복에서 모든 타임스텝에 대해 서로 다른 노이즈를 샘플링합니다. 평가하는 동안 이 방법은 보이지 않는 노이즈 샘플도 사용합니다.
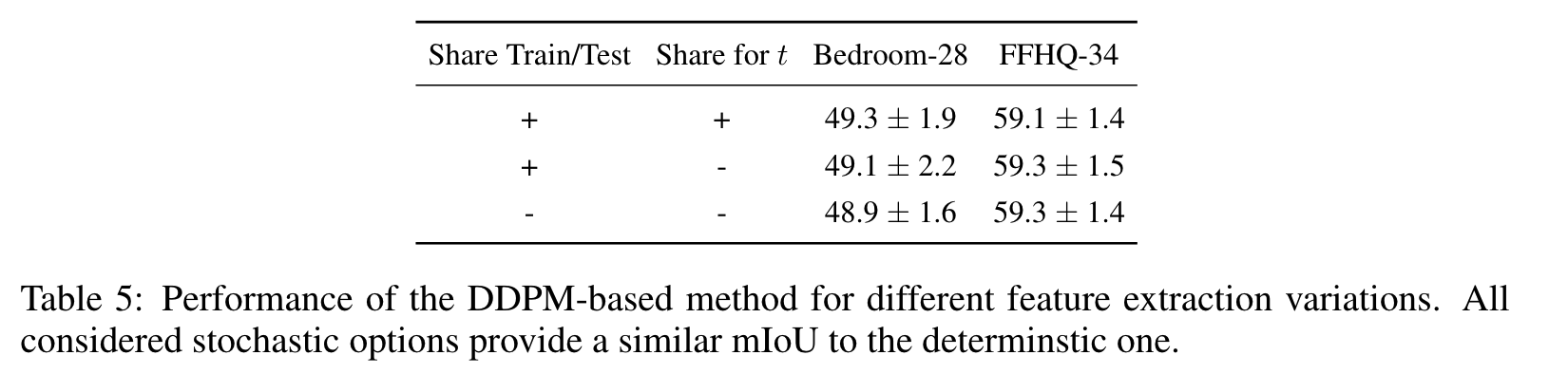
결과는 표 5에 나와 있습니다. 보시다시피 성능 차이는 미미합니다. 다음과 같은 이유로 이러한 동작이 발생합니다.
• 우리의 방법은 노이즈 크기가 낮은 역확산 프로세스의 후반 t를 사용합니다.
• UNet 모델의 심층 레이어를 활용하기 때문에 노이즈가 이러한 레이어의 활성화에 큰 영향을 미치지 않을 수 있습니다.
-->
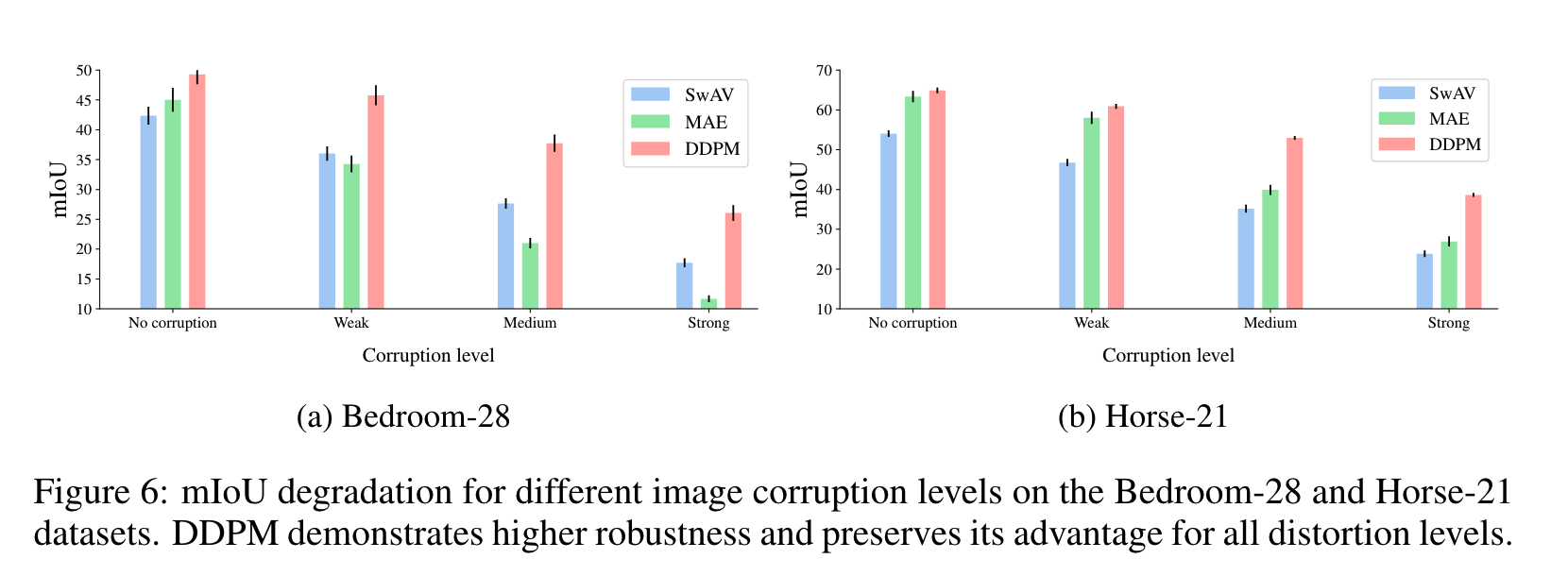
Robustness to input corruptions
이 실험에서는 DDPM 기반 representations의 견고성을 조사합니다. 먼저 Bedroom-28 및 Horse-21 데이터 세트에서 DDPM, SwAV 및 MAE 표현을 사용하여 깨끗한 이미지에서 pixel classifiers를 학습합니다. 그런 다음 (Hendrycks & Dietterich, 2019)에서 채택한 18가지 다양한 corruption types을 테스트 이미지에 적용합니다. 각 손상에는 5단계의 심각도가 있습니다. Figure. 6에서 우리는 각각 "약함", "중간" 및 "강함"으로 표시된 1, 3, 5 수준의 심각도에 대해 모든 손상 유형에 대해 계산된 평균 IoU를 제공합니다. 제안된 DDPM 기반 방법은 심한 이미지 왜곡에도 SwAV 및 MAE 모델보다 더 높은 견고성과 이점을 유지함을 관찰할 수 있습니다.
