
문제 접근 관련
- 문제 이해에 시간을 신경써서 많이 투자하자. 코드 먼저 작성 시작하는 것보다 훨씬 시간을 아끼는 방법이다.
- 이때, 예시가 주어진 경우 반드시 완벽하게 이해하고 넘어가야 한다.
- 조금이라도 복잡한 로직이면 손코딩을 먼저하자. 놓칠 수 있는 예외케이스를 찾기 쉬워진다.
- 코드를 다 작성한 후 내가 작성한 코드를 처음부터 끝까지 쭉 훑으면서 잘못된 부분이 없는지 스스로 체크한 후 테스트 케이스를 넣자. 아니면 매번 반례를 찾게 된다.
- 제일 먼저 생각해야 할 건 브루트포스(완전탐색)이다! 놓치지 말자.
Built-in Functions
zip
>>> for item in zip([1, 2, 3], ['sugar', 'spice', 'everything nice']):
... print(item)
(1, 'sugar')
(2, 'spice')
(3, 'everything nice')기본적으로 길이가 다를 때, 가장 짧은 길이까지만 수행하고 끝난다.
>>> list(zip(range(3), ['fee', 'fi', 'fo', 'fum']))
[(0, 'fee'), (1, 'fi'), (2, 'fo')]자료형
set
remove(x): 원소 삭제
add(x): 원소 추가
| union - 합집합
& intersection - 교집합
- difference - 차집합
^ symmetric_difference : 대칭차집합 연산자(합집합 - 교집합)
우선순위 큐
파이썬에서 우선순위 큐는 heapq를 이용하면 된다.
heapq는 내장 모듈로 별도의 설치 작업 없이 바로 사용할 수 있다.
queue모듈의 PriorityQueue클래스라는게 존재하는데 내부적으로 heapq를 이용하고 오버헤드가 커서 특별한 이유가 아니면 쓸 이유가 없다.
cf. 힙은 상/하 관계를 보장하고 이진탐색트리는 좌/우 관계를 보장한다.
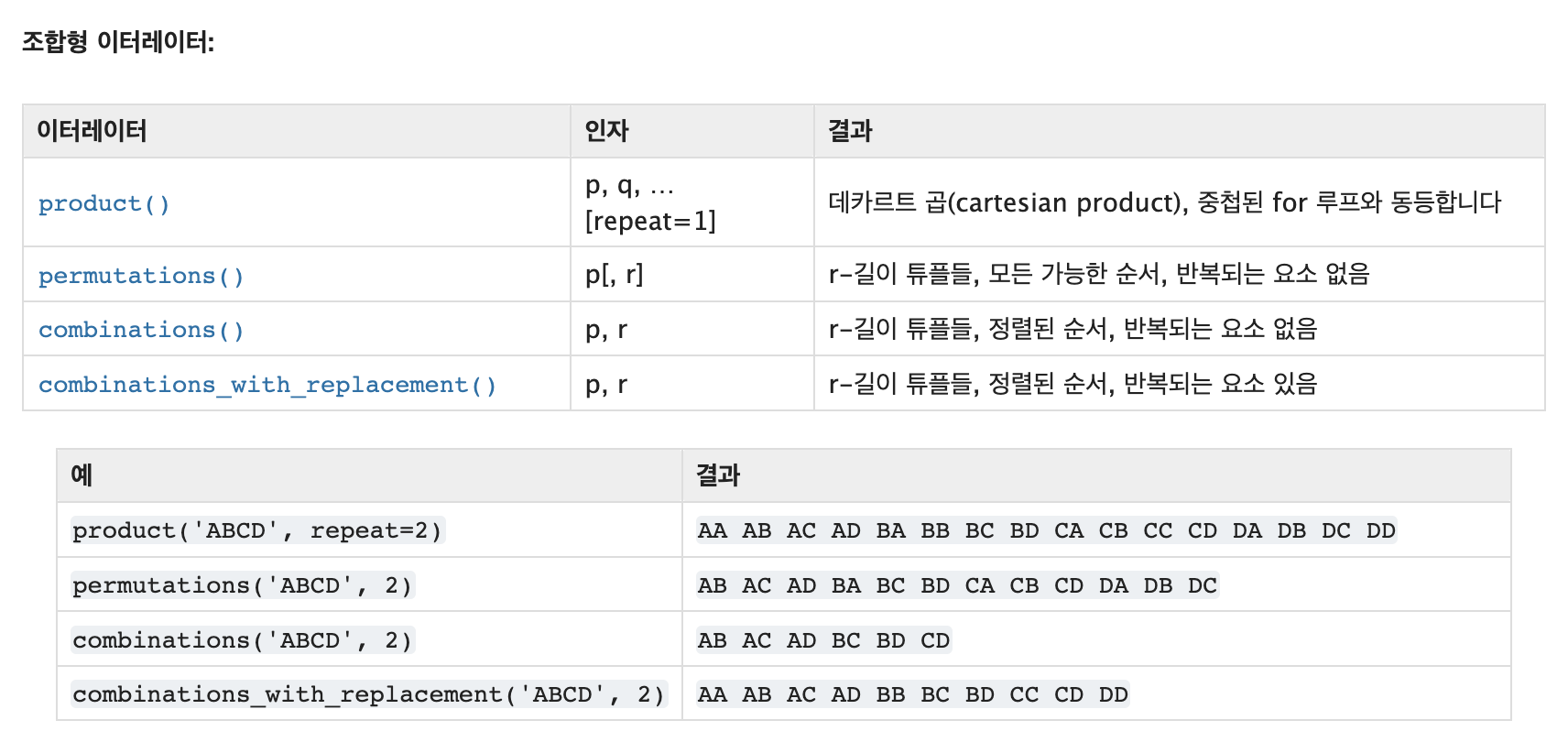
itertools - 효율적인 루핑을 위한 이터레이터를 만드는 함수
iter에 대한 tool로 효율적인 반복을 위한 도구를 제공한다.
주로 순열, 조합, 중복순열, 중복조합을 쉽게 사용하기 위해 쓴다.
- 순열: itertools.permutations(iterable, r=None)
- 조합: itertools.combinations(iterable, r)
- 중복순열: itertools.product(*iterables, repeat=1)
- 중복조합: itertools.combinations_with_replacement(iterable, r)
이에 대한 Documetation에서의 예시는 다음과 같다.
만약 itertools를 이용할 수 없다면 이를 직접 구현해야 할 수도 있다. 삼성 역량테스트에서 못쓴다는 이야기가 있다. 이에 대해 N과 M 시리즈 문제를 통해 연습할 필요가 있다.
collections - 컨테이너 데이터형
이 모듈은 파이썬의 범용 내장 컨테이너 dict, list, set 및 tuple에 대한 대안을 제공하는 특수 컨테이너 데이터형을 구현합니다.
여기서 주로 deque, Counter, OrderedDict, defaultdict를 이용합니다.
deque
class collections.deque([iterable[, maxlen]])
iterable의 데이터로 왼쪽에서 오른쪽으로 (append()를 사용해서) 초기화된 새 데크(deque) 객체를 반환합니다. iterable을 지정하지 않으면, 새 데크는 비어 있습니다.
cf. maxlen이 지정되지 않거나 None이면, 데크는 임의의 길이로 커질 수 있습니다. 그렇지 않으면, 데크는 지정된 최대 길이로 제한됩니다. 일단 제한된 길이의 데크가 가득 차면, 새 항목이 추가될 때, 해당하는 수의 항목이 반대쪽 끝에서 삭제됩니다.
deque에서 다음 메소드들을 이용 가능합니다.
append(x): 데크의 오른쪽에 x를 추가합니다.
appendleft(x): 데크의 왼쪽에 x를 추가합니다.
pop(x): 데크의 오른쪽에서 요소를 제거하고 반환합니다. 요소가 없으면, IndexError를 발생시킵니다.
popleft(x): 데크의 왼쪽에서 요소를 제거하고 반환합니다. 요소가 없으면, IndexError를 발생시킵니다.
rotate(n=1): 데크를 n 단계 오른쪽으로 회전합니다. n이 음수이면, 왼쪽으로 회전합니다. 데크가 비어 있지 않으면, 오른쪽으로 한 단계 회전하는 것은 d.appendleft(d.pop())과 동등하고, 왼쪽으로 한 단계 회전하는 것은 d.append(d.popleft())와 동등합니다.
Counter
class collections.Counter([iterable-or-mapping])
Counter는 해시 가능한 객체를 세기 위한 dict 서브 클래스입니다.
c = Counter() # a new, empty counter
c = Counter('gallahad') # a new counter from an iterable
c = Counter({'red': 4, 'blue': 2}) # a new counter from a mapping
c = Counter(cats=4, dogs=8) # a new counter from keyword argsCounter에서 다음 메소드들을 이용 가능합니다.
most_common([n]): n 개의 가장 흔한 요소와 그 개수를 가장 흔한 것부터 가장 적은 것 순으로 나열한 리스트를 반환합니다. n이 생략되거나 None이면, most_common()은 계수기의 모든 요소를 반환합니다. 개수가 같은 요소는 처음 발견된 순서를 유지합니다.
>> c = Counter(a=4, b=2, c=0, d=-2) >> sorted(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b']
OrderedDict
class collections.OrderedDict([items])
딕셔너리 순서 재배치에 특화된 메서드가 있는 dict 서브 클래스의 인스턴스를 반환합니다.
파이썬 3.7 부터는 일반적인 딕셔너리에서도 입력 순서가 유지되도록 개선되었으나,
파이썬 3.6 이전 버전에서는 딕셔너리의 순서가 보장된다는 조건이 없으므로 딕셔너리의 순서를 이용할때 하위호완을 위해 이용합니다.
defaultdict
collections.defaultdict(default_factory=None, /[, ...])
Return a new dictionary-like object. defaultdict is a subclass of the built-in dict class.
이를 이용하면 다음과 같은 코드 작성이 가능해진다.
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
s = 'mississippi'
d = defaultdict(int)
for k in s:
d[k] += 1
defaultdict에서 for문으로 순회할때 순회중 딕셔너리 사이즈가 변경되었다는 오류 메시지가 생길 수 있는데, default값을 조회할때 생성하게 되므로 그렇다. 이 경우 복사본을 만들어서 for문을 순회하도록 해야 한다.
입,출력 관련
input() 시간 단축
여러 줄의 입력을 많이 받아야 한다면 sys.stdin.readline을 사용하는게 시간, 메모리 측면에서 모두 좋다.
import sys
input = sys.stdin.readline
N = input()주의
- input은 한 줄을 입력 받은 후, 발생한 개행문자(\n)을 제거하여 문자열로 return 하는 반면, sys.stdin.readline은 개행문자를 제거하지 않고 return한다는 특징이 있다.
- strip 함수를 readline 뒤에 붙여주면 앞 뒤의 개행 문자를 없애줄 수 있다.
재귀 깊이 제한
파이썬은 기본으로 재귀 깊이를 1000으로 제한한다.
따라서 재귀를 더 깊게 돌리기 위해서는 이 제한을 풀어줘야 한다.
DFS를 통한 재귀를 사용할때 조심해야 한다.
import sys
sys.setrecursionlimit(10**6)다중 할당
파이썬에서 다중 할당을 하면 값들이 고정된 상태로 한번에 변경된다. 이를 여러 줄에 나눠서 하면 참조에 의해 원하는 결과가 나오지 않는다.
a,b = b,a # 값이 바뀌는 swap아스테리스크(*)
파이썬에서 *는 언팩이다. 시퀀스 언패킹 연산자로 말 그대로 시퀀스를 풀어헤치는 연산자를 뜻하며, 주로 튜플이나 리스트를 unpack하는데 사용한다. 함수 파라미터로 넘기거나, 출력할때 유용하게 사용할 수 있다.
>> my_list2 = [[1,2],[3,4],[5,6]]
>> list(zip(*my_list2))
[(1,3,5),(2,4,5)]
>> my_list = ['11','22','33','44']
>> print(*my_list)
11 22 33 44*는 함수의 파라미터에서 패킹의 역할도 한다.
>>>def f(*params):
... print(params)
>>> f('a','b','c')
('a','b','c')변수 할당에서 활용이 가능하다.
>>> a,*b=[1,2,3,4]
>>> a
1
>>> b
[2,3,4]
>>> *a,b=[1,2,3,4]
>>> a
[1,2,3]
>>> b
4cf.**는 키/값 페어 언패킹을 하는데 사용된다(dictionary)
수학
divmod: 몫과 나머지 동시에 구할 수 있다.
소수
특정 한 수에 대해 소수인지 판별하는 시간복잡도가 가장 짧은 방법은 루트값까지만 조사하는거다. 시간복잡도는
이때, 소수인지 판별해야하는 수가 매우 많으면 에라토스테네스의 체를 이용해야 한다. 배수를 쭉 지워나가는 방식이다. 시간복잡도는 . 시간복잡도 증명은 복잡하다.
2^N인지 판단하기
N&(N-1) 비트연산해서 0이면 2^N이다.
정수인지 판단하기
int(n) == n 으로 판단, n%1 == 0 으로 판단하는 방법도 있으나 가독성 측면에서 좋지 않아 보인다.
순열, 조합 직접 구현
TBU
순열, 조합, 중복순열, 중복조합 직접 DFS로 구현할 줄 알아야 한다.(itertools 못쓸 수 있다)
N진수로 변환하기
divmod를 통해 몫과 나머지를 갱신해나가면 된다.
이때, 마지막에 뒤집어줘야하는 부분이 생길 수 있으니 주의!
binary_str = ""
while number:
number,remainder = divmod(number,2)
binary_str += str(remainder)
binary_str = binary_str[::-1] #!마지막에 뒤집어줘야됨bin(), int()를 통해 이진수와 십진수 변환도 가능하다.
>>> bin(87)
'0b1010111'
>>> int('0b1010111',2)
87
>>> int('1010111',2) # 0b 생략 가능
87누적합
TBU
1차원 누적합, 2차원 누적합 모두 잘 이해하고 있어야 한다.
LCS
기타
global, nonlocal
파이썬 변수 scope 룰을 LEGB라 부른다.(Local Enclosing Global Built-in)

Bulit-in을 제외한 범위에 다음 3가지가 있다.
- 함수 외부를 전역(global/module) 범위
- 함수 내부를 지역(local/function) 범위
- 함수를 중첩했을 때 외부 함수와 내부 함수의 사이에서 생겨나는 비지역(nonlocal/enclosing) 범위
# outer(), inner() 함수 입장에서 전역(global) 범위
def outer():
# outer() 함수 입장에서 지역(local) 범위
# inner() 함수 입장에서 비지역(nonlocal) 범위
def inner():
# inner 함수 입장에서 지역(local) 범위안쪽범위에서 바깥범위 변수를 읽는 것 자체는 따로 해줄 것 없이 가능한데, 변경하려고 할때 고려해야될 요소가 있다.
바깥 범위의 변수를 변경하고 싶을 때,
global: 일반 함수 내에서 전역(global/module) 변수를 대상으로 사용
nonlocal: 중첩 함수 내에서 비지역(nonlocal/closing) 변수를 대상으로 사용
cf. 가변객체(ex. list)에 연산자로 조작하는 경우는 global, nonlocal 없이도 변경 가능(재할당이 아니므로)
locals(), globals()를 통해 로컬변수, 글로벌변수를 확인할 수 있다.
DFS, BFS
- DFS: 스택, 재귀로 구현 / 경로의 특징(제약사항)을 저장해야 할 때 사용
- BFS: 큐로 구현 / 최단경로 구할 때 사용
단순히 모든 정점을 방문하는게 목적이면 DFS, BFS 중 아무거나 이용해도 된다.
DFS는 백트래킹의 골격을 이루는 알고리즘이다.(백트래킹은 기본적으로 DFS의 범주에 속한다)
BFS는 재귀를 사용할 수 없다.
BFS는 최단 경로를 찾는 다익스트라 알고리즘 등에 매우 유용하게 쓰인다.
순열, 조합 만들때 itertools 쓸 수 없으면 DFS로 구현해야 한다.
DFS쓸때 dfs 호출 앞뒤로 제약사항 넣고 빼는 코드를 추가하면 통째로 깊은 복사를 하지 않아도 된다.
복사
얕은 복사가 아닌 깊은 복사를 하려면 단순한 리스트는 [:]로 충분하고, 복잡한 리스트는 copy.deepcopy()로 처리해야 한다. 이때 단순 숫자로 이뤄진 2차원 리스트는 list comprehension을 통해 deepcopy를 쓰지 않을 수 있다.
list1 = [1,2,3]
list2 = [[1,2],[3,4],[5,6]]
deep_copied_list1 = list1[:]
deep_copied_list2 = [l[:] for l in range(len(list2))]deepcopy는 무거우므로 최대한 지양하자.
for loop
set 자료형을 for loop 돌때 도는 와중에 set에 원소가 추가, 삭제되면 for loop에 영향을 끼친다.(참조)
2차원 배열 Transpose, 회전
[Transpose]
transpose는 행과 열을 바꾸는 연산으로 회전과는 다른 결과를 나타낸다.
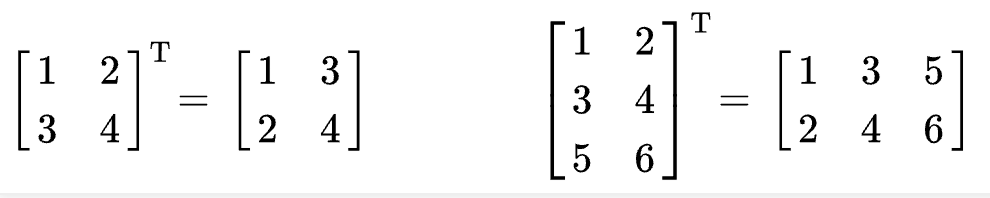
>>> A = [[1, 2], [3, 4], [5, 6]]
>>> list(zip(*A))
[(1, 3, 5), (2, 4, 6)]
>>>list(map(list, zip(*A)))
[[1, 3, 5], [2, 4, 6]]가로, 세로 각각 다른 연산이 필요할때, 가로 연산만 구현하고 세로 연산은 Transpose => 연산 => Transpose를 통해 가로 연산을 이용하도록 하면 문제를 편하게 풀 수 있다.
회전의 경우 시계방향 3번 = 반시계방향 1번, 반시계방향 3번 = 시계방향 1번임을 통해 한가지만 구현하는 방식을 이용할 수 있다.
[반시계방향 회전]
Transpose 이후에 리스트 행순서를 뒤집으면 된다.
mylist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = list(map(list, zip(*mylist)))[::-1]
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
[3, 6, 9]
[2, 5, 8]
[1, 4, 7][시계방향 회전]
리스트 행순서를 뒤집은 후 Transpose하면 된다.
mylist = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = list(map(list, zip(*mylist[::-1])))
[1, 2, 3]
[4, 5, 6]
[7, 8, 9]
[7, 4, 1]
[8, 5, 2]
[9, 6, 3]최대, 최소 초기값 설정
2가지 방법이 있다. 임의의 수로 지정하면 실수할 여지가 있다.
mx = -sys.maxsize
mn = sys.maxsize
mx = float('inf')
mn = float('inf')float('inf') 방식이 sys를 import할 필요가 없어서 개인적으로 애용하는 것 같다.
추가로, float('inf')는 == 연산을 해도 True로 잘 나온다.
any(), all()
any()는 어느 하나라도 참이면 참 return => OR연산
all()은 모두 참이어야 참 return한다 => AND연산
>>> any([True, False, False])
True
>>> all([True, False, False])
False둘 다 파이썬 내부 함수들이다.
코딩테스트 팁
- https://medium.com/@b9d9/%EC%BD%94%EB%94%A9%ED%85%8C%EC%8A%A4%ED%8A%B8-%ED%8C%81-29233bc832d8
- https://www.acmicpc.net/blog/view/70
참고
- https://takeu.tistory.com/118
- https://seolhee2750.tistory.com/m/162
- https://pottatt0.tistory.com/entry/Python-%EC%BD%94%EB%94%A9-%ED%85%8C%EC%8A%A4%ED%8A%B8%EC%97%90-%EA%BC%AD-%ED%95%84%EC%9A%94%ED%95%9C-%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%AC%B8%EB%B2%95#%F-%-F%--%-A%--%EC%-B%A-%EC%A-%--%EC%--%--%EC%--%-C%--%EC%-C%A-%EC%-A%A-%ED%--%-C%--%ED%--%-C%EC%A-%--%--%EB%-D%BC%EC%-D%B-%EB%B-%-C%EB%-F%AC%EB%A-%AC
- https://velog.io/@jmjmjames/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EB%AC%B8%EC%A0%9C-%ED%92%80%EC%9D%B4%EC%8B%9C%EC%97%90-%EC%9C%A0%EC%9A%A9%ED%95%9C-%EC%BD%94%EB%93%9C-%EB%AA%A8%EC%9D%8C%EC%A7%91
- https://www.daleseo.com/python-global-nonlocal/
- http://pyengine.blogspot.com/2016/11/python-zip-transpose.html
- https://velog.io/@mmy789/Python-zip-%EC%9D%B4%EC%9A%A9%ED%95%B4%EC%84%9C-2%EC%B0%A8%EC%9B%90-%EB%A6%AC%EC%8A%A4%ED%8A%B8-%ED%9A%8C%EC%A0%84%ED%95%98%EA%B8%B0
