서론
- 웹에서 위치 정보 기반 데이터를 표현 하기 위해서는 Backend에서 위치 기반의 데이터(ex. GeoJSON, WKT 등) 조회하여 브라우저에서 라이브러리(OpenLayers, Leaflet) 이용하여 랜더링 한다.
- 몇천건의 백터 데이터의 정보들을 웹브라우저에서 랜더링 하는것은 별 문제는 없지만 만건이상의 데이터들을 웹브라우저에서 랜더링하기에는 클라이언트는 대기하는 시간으로 짜증을 유발 할 수도 있다ㅠ
- 전략적으로 모든 데이터들을 다 표현하기 보다는 한 눈에 데이터에 대한 분포 현황 정도만 표현 할 수 있도로록 지도에 가시화 할 수 있도록 만들 필요성이 생겼다.
- 제주 지역의 팜맵(현실적인 농경지정보를 표현하는 지도)을 기준으로 필지의 Land(밭, 과수원, 논 ...등)에 대한 분포맵을 제작하기로 하였다.
준비
- 대상 지역 : 제주도
- 필요 RAW 데이터
- 분포도를 표현 하기 위한 대상 지역의 Index Map 을 다운로드 하여 제주지역만 QGIS를 통하여 추출 한다.
- 팜맵(농경지 지도)는 국가공간정보포털 에서 다운로드하여 제주지역만 QGIS를 통하여 추출한다. - 필요 소프트웨어
- postgresql 10 + PostGIS 2.4
- DBeaver
DBMS 설치나 소프트웨어 설치 과정은 생략한다.
과정
사전 준비
- 1:1000의 인덱스 데이터와 팜맵을 QGIS를 통하여 DBMS(Postgresql)
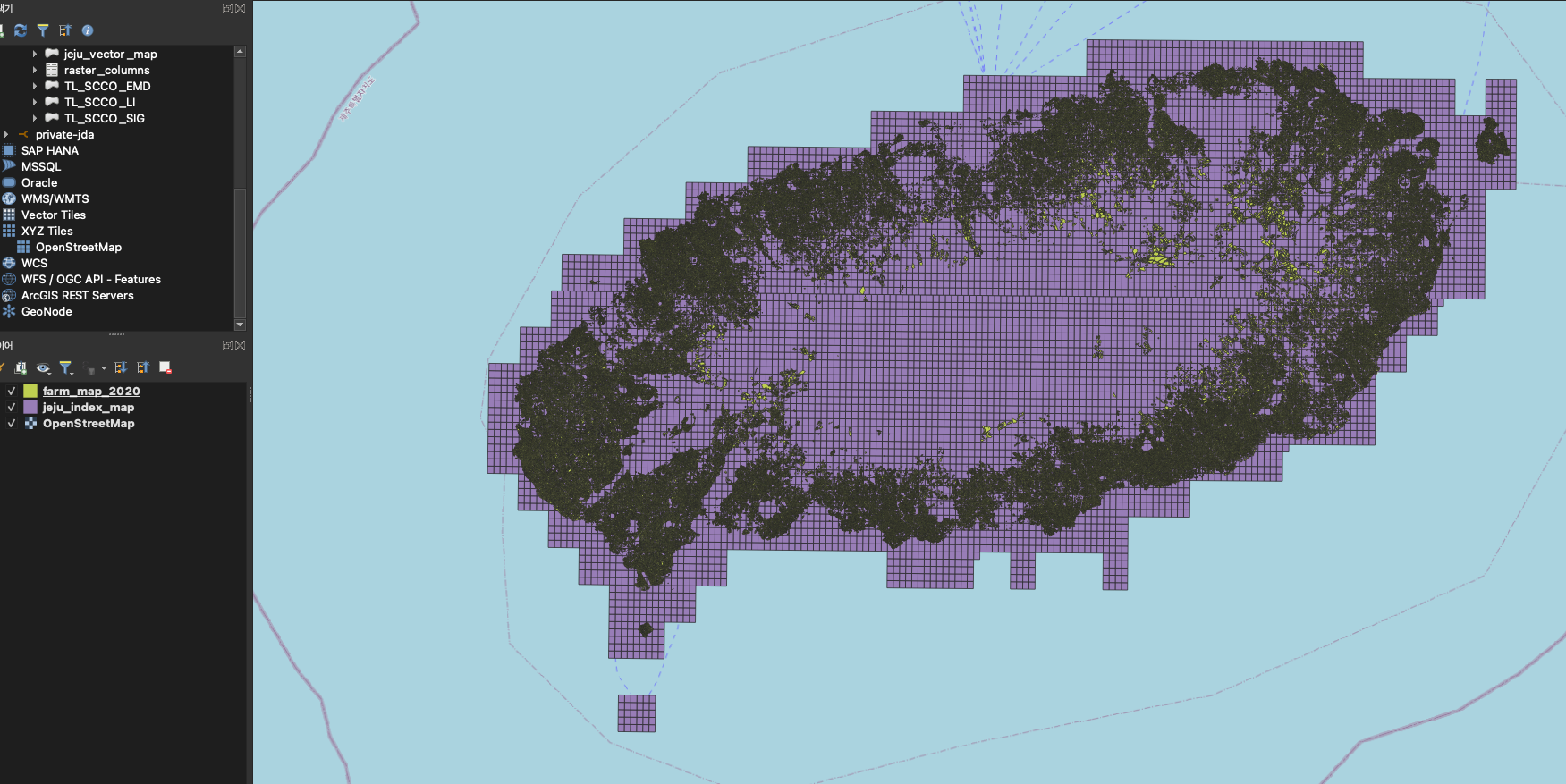
- index 데이터의 테이블명은 jeju_index_map
- 팜맵의 데이터의 테이블명은 farm_map_2020
데이터 가공
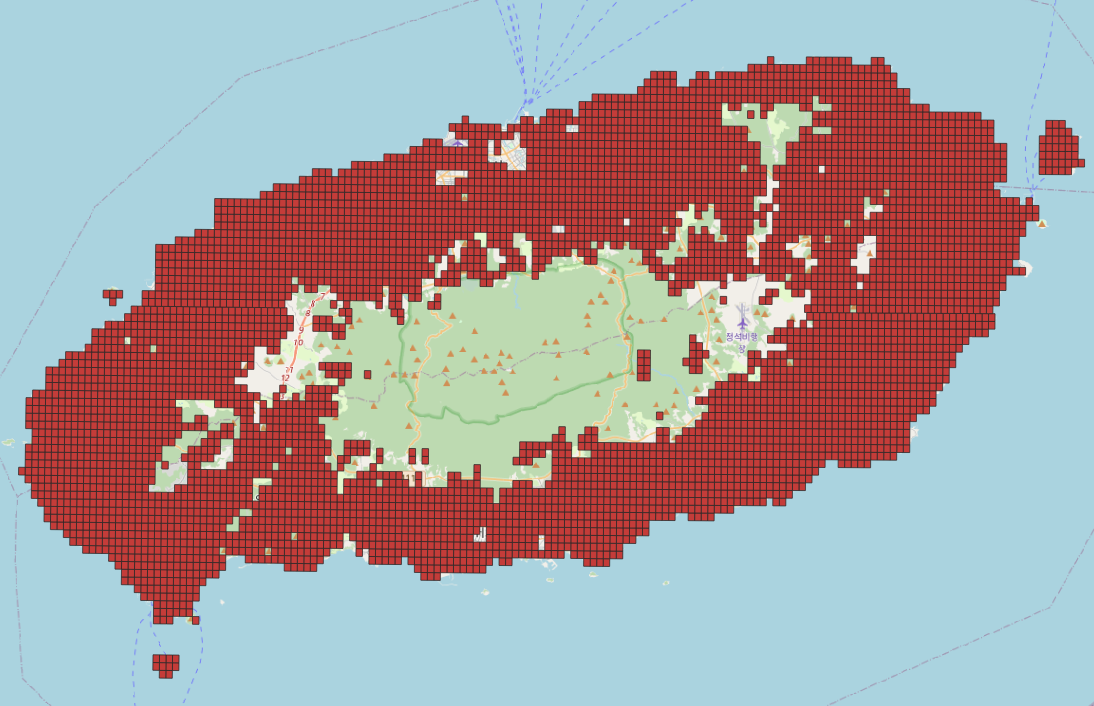
1. Index 데이터와 팜맵이 일치 되는 부분 찾기
- 분포맵을 만들기 위해서는 Index 맵과 팜맵과 겹치는 부분을 먼저 찾아야 한다. PostGIS의 st_intersection 함수로 찾을수 있다.
select
count(jim.id) as "cnt",
jim.geom
from
jeju_index_map jim,
farm_map_2020 fm
where
st_intersects(jim.geom, fm.geom) = true
group by
jim.id쿼리 수행 시간 : 17.586 초
- 팜맵과 Index 맵을 조인하고 중복되는 데이터만 st_intersection으로 처리해주면 아래 그림과 같이 중복되는 데이터만 가져온다.
2. 선택된 Index에 대한 가장 많이 분포된 Land 판별하기
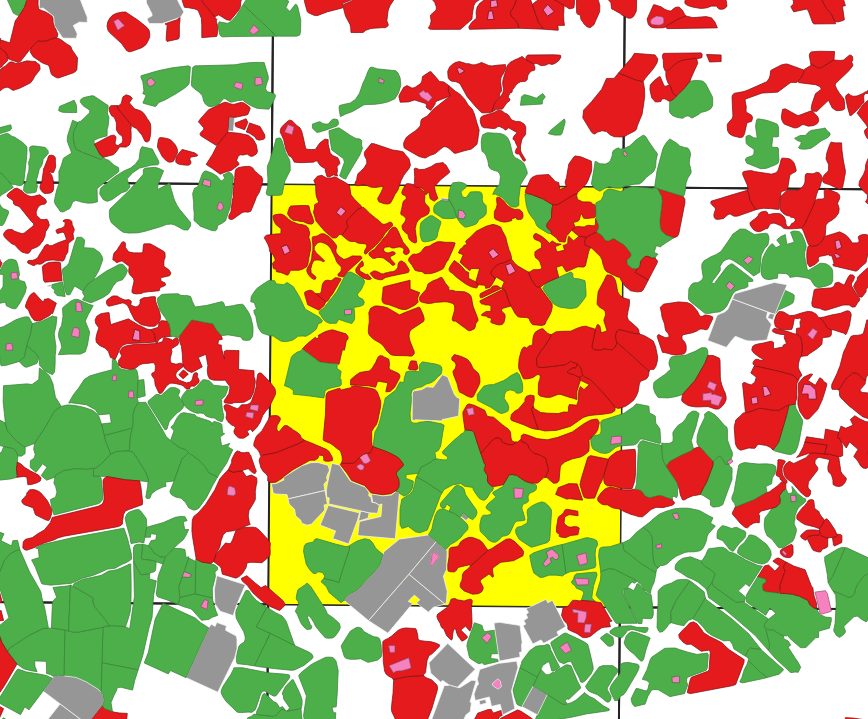
- 뒤에 노란색으로 선택된 객체가 Index 맵이고 나머지는 팜맵에 Geometry이다.
선택된 Index 객체에 안에 가장 많이 존재하는 팜맵의 Land가 어떤 것이 있는지 확인 하는 쿼리를 작성 해보겠다.
select
fm."LAND_CODE",
count(fm.id)
from
farm_map_2020 fm,
(select geom from jeju_index_map where id = 8313) as tile
where st_intersects(tile.geom, fm.geom)
group by fm."LAND_CODE"
order by count(fm.id) desc
limit 1;쿼리 수행 시간 : 0.012초
- 해당 쿼리의 limit를 제외하고 쿼리를 실행 하면 해당 Index에는 밭이 가장 많이 존재하는걸로 판단이 된다.
| LAND_CODE | count |
|---|---|
| 밭 | 58 |
| 과수 | 29 |
| 비경지 | 15 |
| 시설 | 13 |
3. 전체에 대해서 분포된 객체 구하기
- 1번과정과 2번과정 조합해서 이제 분포 맵을 만들어 보자
- 먼저 2번 분포를 판단하기 위한 쿼리를 함수로 생성한다.
CREATE OR REPLACE FUNCTION public.get_farm_distribution_map(tileId INT)
returns varchar
LANGUAGE sql
STABLE STRICT
AS $function$
select
fm."LAND_CODE"
from
farm_map_2020 fm,
(select geom from jeju_index_map where id = tileId) as tile
where st_intersects(tile.geom, fm.geom)
group by fm."LAND_CODE"
order by count(fm.id) desc
limit 1
$function$
;- 이제 완성된 쿼리를 보자. 위에서 만든 get_farm_distribution_map 함수를 이용하여 index map에 분포도를 구한다.
select
jim.geom,
get_farm_distribution_map(jim.id)
from
jeju_index_map jim,
farm_map_2020 fm
where
st_intersects(jim.geom, fm.geom) = true
group by
jim.id쿼리 수행 시간 : 1.399초
- 조회한 결과를 확인해보자.
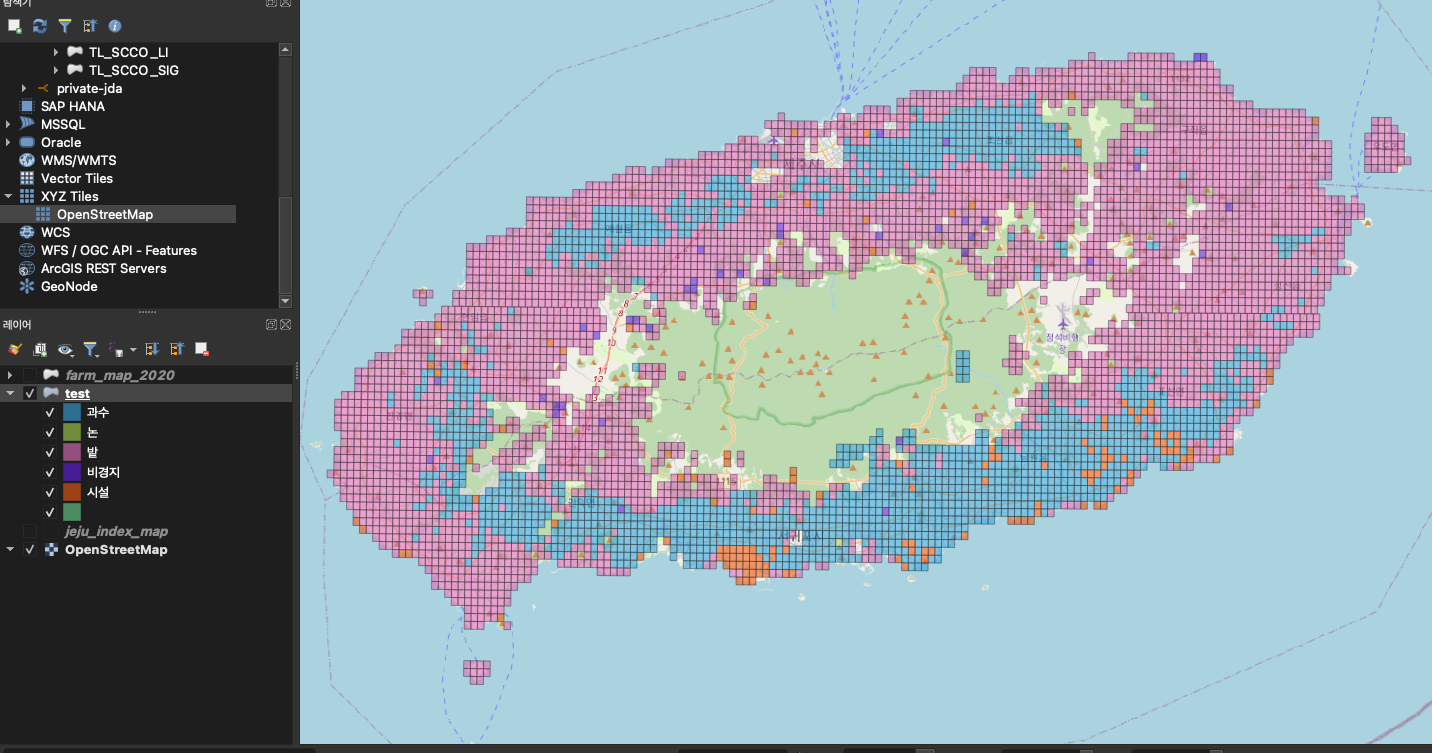
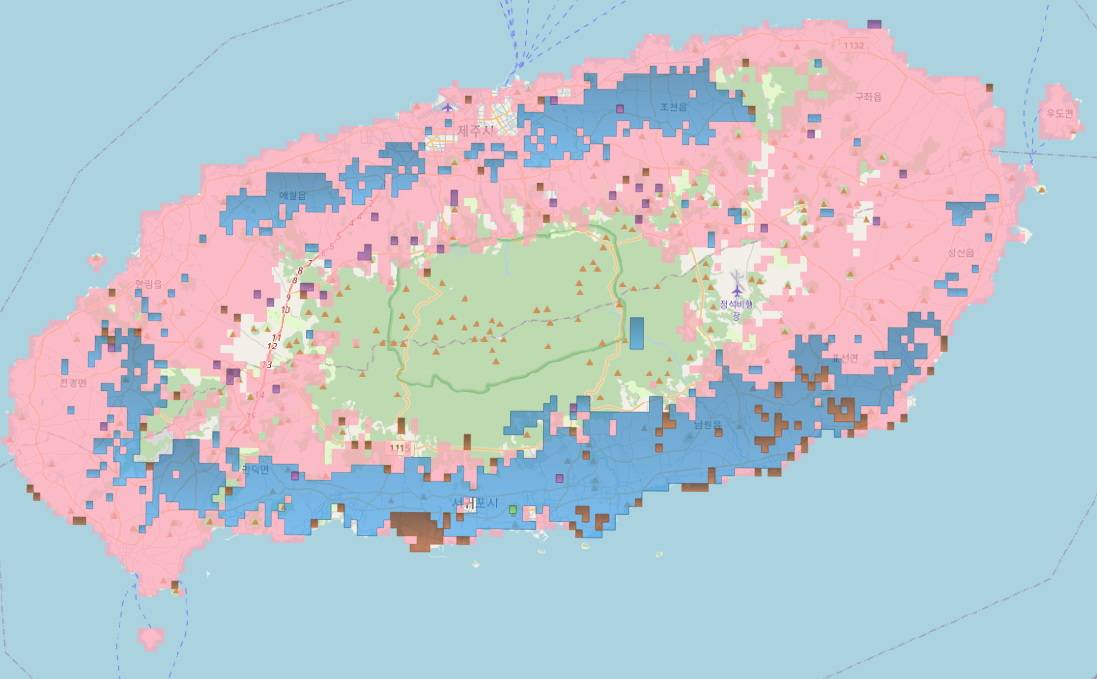
위의 사진을 보면 제주도에는 밭이 가장 많이 분포 되어 있고 다음으로는 과수, 시설 등으로 한눈에 제주도에 Land속성에 대한 분포도를 확인해 볼 수 있다.
조회된 객체 수를 보면 4000건 이상 조회가 되는데 QGIS에서나 Openlayers를 통해 랜더링 하기에는 부담이 될 수도 있다. 쿼리 개선해서 좀더 심플하게 표현해보자.
4. 쿼리 개선
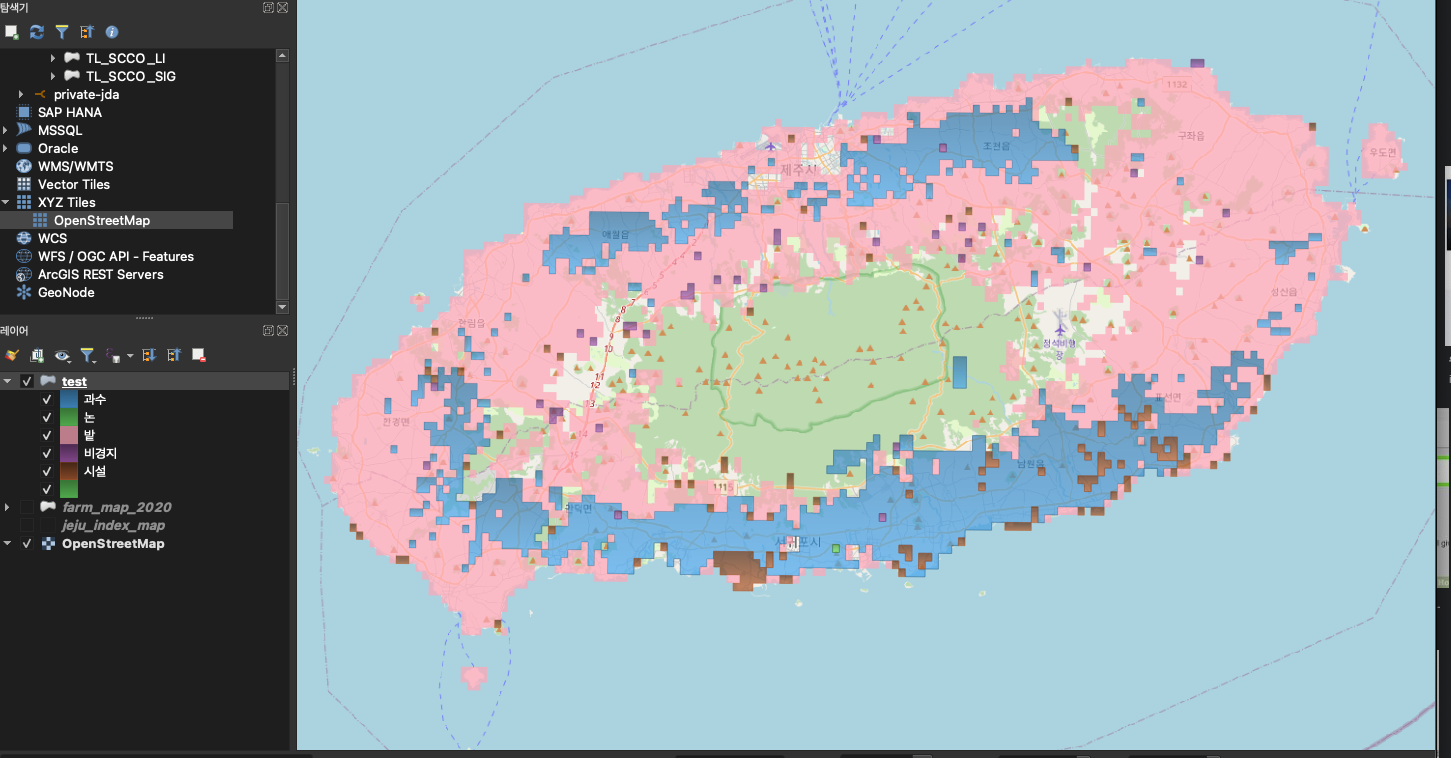
- 같은 객체들을 하나로 합치자.
- 쿼리 결과를 보면 같은 분류라도 분할 되어 표시되는 것을 확인 할 수 있다. st_union 함수를 이용하여 Geometry를 합쳐 보자.- 이전 결과와 비교를 해보면 확실히 Geometry가 깔끔하게 표현되는 확인 할 수 있다.
with t as (
select
jim.geom as "geom",
get_farm_distribution_map(jim.id) as "land"
from
jeju_index_map jim,
farm_map_2020 fm
where
st_intersects(jim.geom, fm.geom) = true
group by
jim.id
)
select st_union(t.geom), t.land from t
group by t.land쿼리 수행 시간 : 26.067초 (확실히. ST_Union으로 객체를 합치기 때문에 시간이 더 오래 걸리는것 같다.)
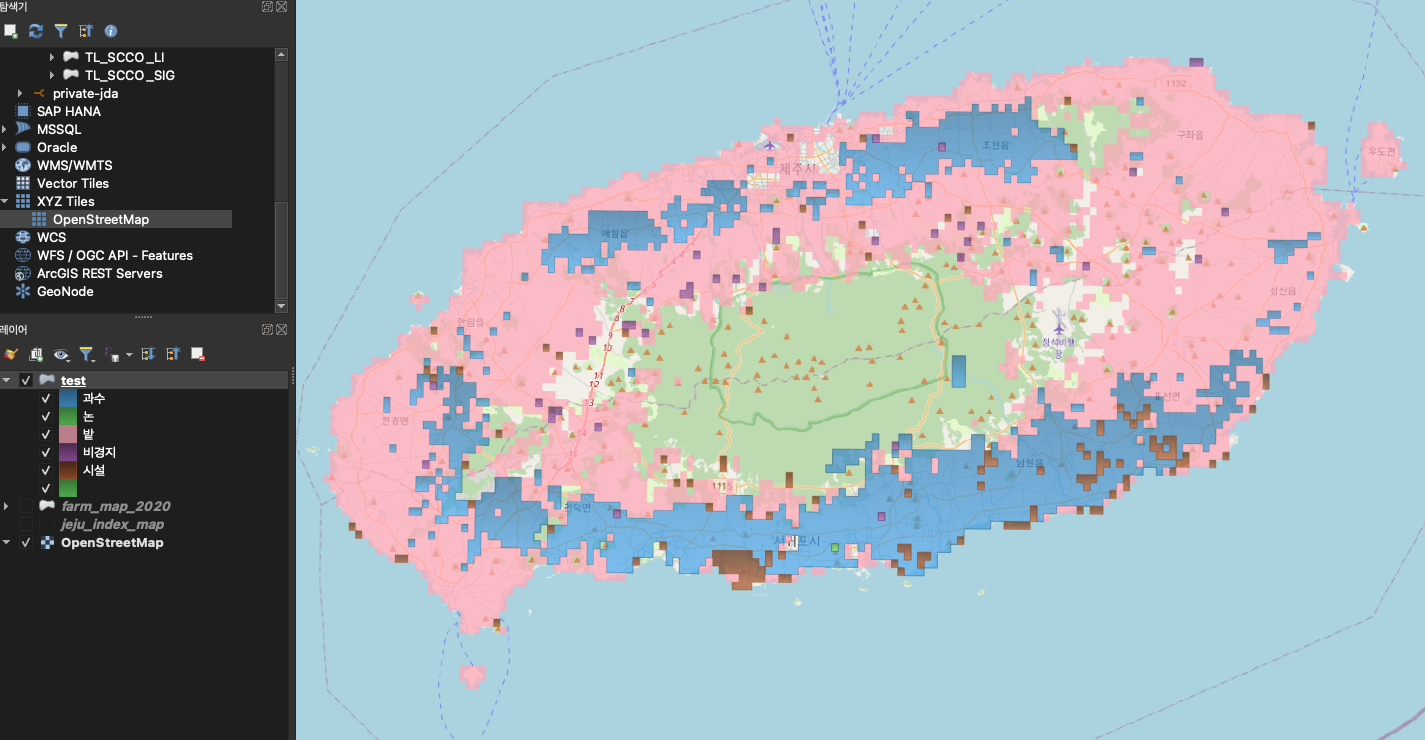
- Geometry를 좀더 심플하게 만들어 보자
- 생성된 분류맵에 Geometry를 st_simplify함수를 이용하여 심플하게 만들어 랜더링 부담이 덜 되도록 만들어 보자- 아래 결과를 보면 그닥 st_simplify 이전과 이후 차이가 없어 보인다.
with t as (
select
jim.geom as "geom",
get_farm_distribution_map(jim.id) as "land"
from
jeju_index_map jim,
farm_map_2020 fm
where
st_intersects(jim.geom, fm.geom) = true
group by
jim.id
)
select
ST_Simplify(st_union(t.geom), 1),
t.land
from t
group by t.land쿼리 수행 시간 : 27.646초
결론
- 웹에서 많은 데이터들을 가시화 하기위해서 대안으로 분포맵을 만들어 보았다.
생각보다 분포맵을 만다는것은 어렵지는 않았는데. 아무래도 Geometry 연산이 있다보니 퍼포먼스가 그렇게 좋아 보이지 않아 실시간으로 서비스 하는것은 어려울 것 같고 특정 테이블에 저장해 놓았다가 업데이트 주기에 맞춰 쿼리를 실행하면될 것 같기도 하다. - 다음에는 이러한 분포맵 보다 Vecter Tile 서비스를 구현해 보겠다.
