이 글은 https://www.youtube.com/watch?v=yQ20jZwDjTE를 듣고 공부한 내용을 정리한 글입니다.
스크래핑 - 필요한 부분만 가져오는 것
크롤링 - 허용하는 범위 내의 데이터를 마구잡이로 가져오는 것
웹은 크게 세가지로 구성: html, css, js
집을 예로 들면 html이 구조, css가 인테리어, js가 기능
웹 스크래핑은 html만 이해하면 됨
웹 강의는 웹페이지가 변경될 수 있으므로 강의를 무작정 따라하지 말고 왜 그러냐 이해를 하고 안 될 경우 웹페이지가 어느 부분이 변경된지 생각하고 직접 수정해야 함.
1. HTML
html은 Hyper Text Markup Language 이다.
<html/> # 안에 아무것도 없어서 '/'으로 닫은 것
<html></html> # 여는 태그와 닫는 태그로 이루어짐<html>
<head>
<title>나도 html시작</title>
</head> <!__ head는 홈페이지의 제목 또는 선행작업 __>
<body>
<h1>웹 공부 본격 시작</h1> <!__ h1을 쓰면 글자가 좀 크게 나옴 __>
글자 크기 비교용
</body> <!__body는 본문 내용 정의__>
</html> <!__html안에 head와 body 부분이 생김__>html의 주석은 <!__ __>로 단다.
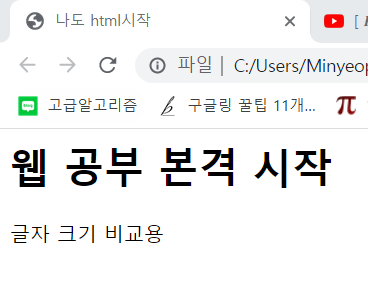
이렇게 만들어진다.
이제 조금 더 들어가서 로그인 페이지를 만들어보자.
type과 value는 attribute라 하져 element의 세부 속성을 의미한다.
<html>
<head>
<meta charset="UTF-8">
<title>나도 html시작</title>
</head> <!__ head는 홈페이지의 제목 또는 선행작업 __>
<body>
<!__안에 어떤 요소가 들어갈 일 없으므로 input은 /input으로 닫는 등의 문법 필요 X__>
<input type = "text" value = "아이디를 입력하세요"> <!__type = text의 의미는 text를 받아올 것이라는 뜻__>
<input type = "password" value = "아이디를 입력하세요"> <!__type = password를 쓰면 실재로 문자,숫자등이 가려져서 출력됨__>
<input type = "button" value = "로그인">
<a href="http://google.com">구글로 이동하기</a>
</body> <!__body는 본문 내용 정의__>
</html> <!__html안에 head와 body 부분이 생김__>type 은 입력을 어떻게 받을지를 의미, value는 출력
href는 링크를 의미한다.
html, head 등은 태그 이름이라 하고
태그 이름 안의 type, value등은 속성이다. 이런 것들이 하나의 element를 이룬다.
더 자세한 내용은 w3school에서 공부할 수 있다.
2.Xpath
html문서를 갔을 때 보통 굉장히 많은 element로 구성되어 있는데, 그 경로를 의미하는 것이 xpath이다.
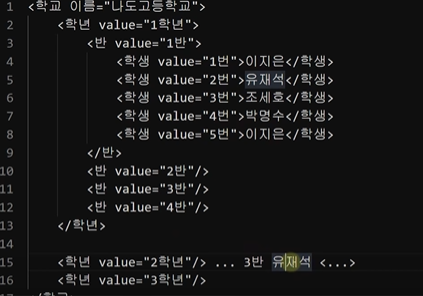
실재 html문법이 이런 식은 아니지만 위와 같다고 가정해보자.
이 때 1학년 1반의 이지은 학생을 부른다면 누가 가야할까?
또한 나도고등학교의 유재석 학생을 부른다면 1학년 1반과 2학년 3반 중 누가 가야할까?
이러한 상황에서 어떤 엘리먼트를 지칭하는지 명확하게 하기 위하여 xpath를 사용한다.
ex.
/학교/학년/반/학생[2] -> 중복되는 학생들 중 2번째를 고를 때
만약 이가 복잡해질 때는?
학교에는 학번 같은게 있다는 것을 생각해보자.
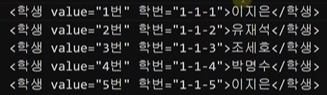
이렇게 설정해보자. 그러면
//*[@학번="1-1-5"] 라고 하면 된다.
실재 html에서는 굉장히 줄어든다.
실재 xpath에서는

위의 경로 대신 아래와 같이 "모든 문서에서 id가 "login"인 엘리먼트를 찾아주세요" 라고 할 수 있다.
즉, 유니크한 id가 있는 경우 훨씬 간단하게 찾을 수 있다.
이 때 /는 바로 아래의 경로를 의미하고 //는 해당 경로 아래의 모든 엘리먼트를 의미한다. *도 원래는

이런 식으로 학생 태그의 학번 속성이 "1-1-5"인 엘리먼트를 찾는 것인데
학생을 *로 하면 태그 상관없이 모든 엘리먼트 중 학번 속성이 "1-1-5"인 엘리먼트를 찾는 것이다.
머리가 아플 수 있으나 xpath는 이런 식으로 적을 수 있고, 전체 경로 또는 특정 요소를 통해 길이를 줄일 수 있구나 정도만 알아두면 된다.
왜냐하면 xpath는 브라우저에서 알아서 찾아줄 것이기 때문이다.
ex.
네이버의 로그인 버튼을 xpath 복사하기를 통해 복사하면
//*[@id="account"]/a 해당 내용이 복사된다.
모든 문서의 모든 태그 중 id속성이 "account"인 녀석 바로 밑의 a태그를 찾으라는 의미이다.
그럼 그냥 경로를 직접 찾으려면?
copy full xpath 를 하면 된다.
/html/body/div[2]/div[3]/div[3]/div/div[2]/a
xpath의 관계
상위 엘리먼트 : 부모 노드
하위 엘리먼트 : 자식 노드
가장 위 엘리먼트 : 루트 노드
같은 경로에서 다음으로 표현되는 엘리먼트 : 형제 노드
(트리와 완벽히 같다)
3.Requests
스크래핑은 웹에서 필요한 정보를 가져오는 것
이를 위해 웹에서 html문서 정보를 가져오려면 requests 라이브러비를 설치해야한다.
import requests
res = requests.get("https://www.naver.com/")
# 원하는 정보가 있는 url을 문자열 형식으로 넘겨주면 requests.get으로 url에서 정보를 get해온다.
print("응답 코드:", res.status_code) # 200이면 정상위의 코드를 실행하면 200이 출력되는 것을 확인할 수 있다.
만약 다른 숫자가 출력되면 이 페이지에 접근할 권한이 없다는 것을 의미하고 이 경우는 다른 방법을 사용해야 한다.
처리방법은 다음과 같다.
import requests
import sys
res = requests.get("https://www.naver.com/")
# 원하는 정보가 있는 url을 문자열 형식으로 넘겨주면 requests.get으로 url에서 정보를 get해온다.
if res.status_code == requests.codes.ok:
print("정상입니다")
else:
sys.exit(f"문제가 생겼습니다. [에러코드 {res.status_code} ] ")sys.exit()에 대해서는 이 링크를 참고하자.
https://www.delftstack.com/ko/howto/python/python-exit-program/
그리고 이를 if문 없이 처리할 수도 있다.
import requests
res = requests.get("https://www.naver.com/")
res.raise_for_status()raise는 영어사전의 뜻으로 '발생하다'가 있고
for는 '때문에' 라는 의미가 있다.
즉, res.raise_for_status()는 상태에 따라 실행될 수 있는 메소드이다.
이 메소드는 get메소드를 통해 받아온 응답을 통해 페이지에 접근할 권한이 없다는 것을 확인할 경우 프로그램을 바로 종료시킨다.
이 코드는 언제나 습관적으로 get메소드와 함께 쓴다고 생각하자.
이제 한번 실행을 해보도록 하자.
import requests
res = requests.get("https://www.naver.com/")
res.raise_for_status()
# 원하는 정보가 있는 url을 문자열 형식으로 넘겨주면 requests.get으로 url에서 정보를 get해온다.
print(res.text)res.text를 실행하면 해당 페이지의 html 코드를 모두 가져오게 된다.
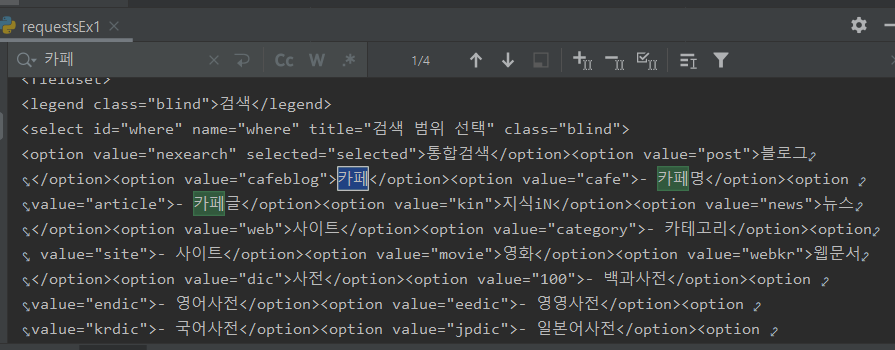
이런 식으로 말이다.
import requests
res = requests.get("https://www.google.co.kr/")
res.raise_for_status()
# 원하는 정보가 있는 url을 문자열 형식으로 넘겨주면 requests.get으로 url에서 정보를 get해온다.
print(res.text)
with open("mygoogle.html", "w", encoding="utf8") as f:
f.write(res.text)이렇게 한번 해보면 파일로 내용을 확인할 수 있는데
아래의 내용을 한번 자세히 보자.
- with:
https://pythondocs.net/uncategorized/%ED%8C%8C%EC%9D%B4%EC%8D%AC-with-%EC%A0%95%EB%A6%AC/ 의 내용을 참고하였다.
보통 프로그램은 파일에 접근해서 파일 내용 들을 읽고 쓰고 삭제하고 수정하는 등 무언가의 일을 수행한 뒤 그 파일을 해제(close)하는 패턴을 따른다. 예를 들어 우리가 엑셀 파일을 열었는데 그 엑셀 파일을 열고 있는 동안에는 다른 프로그램에서 엑셀파일을 접근할 수 없게 된다. 거두절미하고 파일을 열었으면 닫아주는 일을 빼먹지 말아야 한다는 것이다.
보통은 close() 등과 같은 메소드를 사용하지만 여기에는 숨은 문제점이 있다.
파일 처리를 수행하는 도중에 오류가 발생하게 되면 close()문을 실행할 수 없고 그렇게 되면 이 파일은 영원히 닫을 수가 없게 된다. with문은 그 구문을 실행했을 때 오류가 발생하든 안 하든 마지막에 close를 하도록 하는 것이다.
파이썬은 특수 메소드를 사용한다.
(특수 메소드란?
클래스문을 배울 때 파이썬 메서드 이름으로 __init__을 사용하면 이 메서드가 생성자가 된다는 것을 배웠다.
특수 메서드는 클래스 내부에서 선언할 수 있는 특수한 메서드를 의미하는데 파이썬에서 사용되고 있는 연산자나 함수를 오버로딩할 수 있다.
특수 메서드는 위의 init과 같이 메서드명 전후로 이중 언더바를 가지고 있고 이미 파이썬에서 정의되어 사용되고 있는 연산자나 함수를 클래스 내부에 오버로딩한다.)
여기서 with문은
enter와 exit 특수메소드를 가진 객체에 쓸 수 있는 것이다.
with문 내 표현식은 한 객체로 평가된다.
이어서 이 객체의 enter메소드가 호출되고 끝으로 호출 결과가 변수에 할당되는 것이다.
블록을 모두 실행하면 블록에서 오류가 발생했더라도 파이썬은 그 객체에 exit메소드를 호출한다.
이제 위 내용을 보자
with open("mygoogle.html", "w", encoding="utf8") as f:
f.write(res.text)with 문내의 표현식 open()는 한 객체로 평가된다.
우리도 알다시피 이는 mygoogle.html을 쓰기 모드, UTF8 인코딩으로 연 파일 객체의 레퍼런스를 리턴하는 메소드이다.
그리고 이는 as f 문을 통해 f라는 변수에 할당된다.
여기에 res.text를 쓰는 것이 위의 구문의 내용이다.
이를 실행해보면
이렇게 폴더에 mygoogle.html이 생성된다.
이를 열어보면
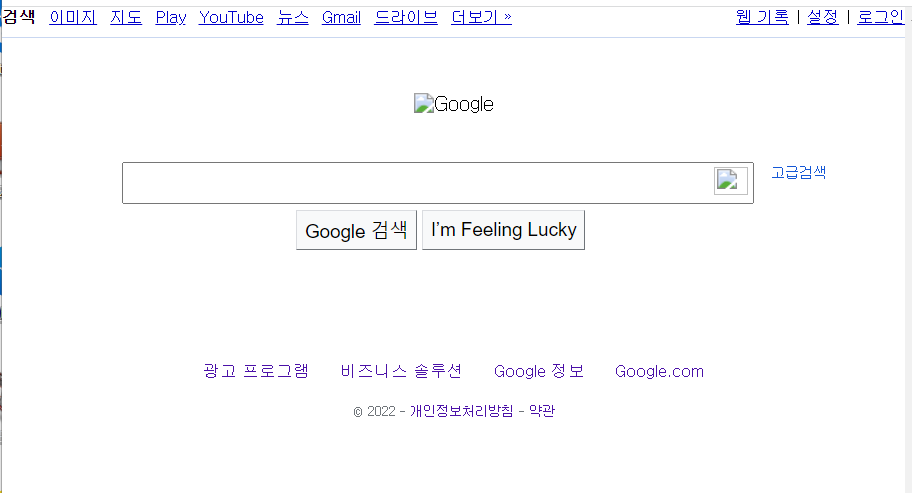
위와 같은 페이지가 열림을 확인할 수 있다.
이 때 이 페이지는 검색 등의 기능이 정확히 작동하지는 않는데
원인 중 하나는 원래 google.com에 작동하여 google.com뒤에 특정 링크가 붙어 그 링크로 이동해야 하는 것이 html파일의 경로 뒤에 그 링크가 붙으므로 정상적으로 작동하지 않는 것이다.
정규식 기본
정규식(reqular expression)
어떤 문자열이 형식에 부합하는지를 확인할 때 우리는 정규식을 쓴다.
import re
def print_match(m):
if m:
print(m.group())
else:
print("매칭되지 않음")
# 차량번호판은 네자리 문자라고 가정
# ca?e
# care, cafe, cave, case...
# 이런걸 검색할 때 어떻게 하면 좋을까?
# caae, cabe....
# 이런 방식이 너무 복잡하므로 정규식을 사용한다.
p = re.compile("ca.e") # p는 패턴이라는 뜻
# re 내장 모듈내 compile메소드 사용, compile메소드는 패턴 객체를 리턴한다
# . : 하나의 문자를 의미 > care, cafe... 는 O caffe는 X
# ^ : 문자열을 시작 (^de): desk, destination (O) | fade (x)
# $ (se$) : 문자열의 끝 > case, base (O) | face (X)
m = p.match("caffe") # match는 문자열의 처음부터 정규식과 매치되는지 조사한다.
# 그룹은 매치된 문자열을 돌려준다
# 매치되지 않으면 None 객체를 리턴한다.
print_match(m)이 때 careless 를 p.match()의 인자로 넣으면 care가 출력된다
왜냐하면 match의 동작이 주어진 문자열의 처음부터 일치하는지 확인하는 것이기 때문이다.
처음부터 일치하니 뒷부분은 다른게 있어도 상관을 하지 않고 일치되는 부분만 리턴된다.
저기서
m = p.match("caffe")를 p.search("good care")로 바꾸면 care가 출력된다.
왜냐하면 search는 문자열에 매칭되는 문자열이 있는지를 검사하는 메소드이기 때문이다.
"good care cave"를 넣어도 care가 리턴되는 것을 보아 문자열 앞에서부터 검사되어 가장 먼저 매칭되는 문자열만 리턴하는 메소드임을 알 수 있다.
이번에는 다른 메소드 및 필드들도 한번 알아보자.
import re
def print_match(m):
if m:
print(m.string) # 입력받은 입자열
print(m.start()) # 일치하는 문자열의 시작 인덱스
print(m.end()) # 일치하는 문자열의 마지막 인덱스
print(m.span()) #일치하는 문자열의 시작/끝 인덱스
else:
print("매칭되지 않음")
p = re.compile("ca.e")
m = p.match("careless")
print_match(m)careless
0
4
(0, 4) 가 출력된다.
import re
def print_match(m):
if m:
print(m.string) # 입력받은 입자열
print(m.start()) # 일치하는 문자열의 시작 인덱스
print(m.end()) # 일치하는 문자열의 마지막 인덱스
print(m.span()) #일치하는 문자열의 시작/끝 인덱스
else:
print("매칭되지 않음")
p = re.compile("ca.e")
m = p.search("good care")
print_match(m)good care
5
9
(5, 9) 가 출력된다.
그리고 지금까지 match나 search는 맨처음에 일치되는 하나의 값만 리턴했는데 이번엔 일치하는 모든 것을 리스트 형태로 리턴
match, search 메소드는 match객체를 리턴했으나
findall은 리스트 객체를 리턴하므로 print_match 메소드를 사용할 수 없다.
import re
p = re.compile("ca.e")
m = p.findall("good care cave") # 매칭되는 문자열을 리스트 형태로 리턴
print(m)['care', 'cave'] 가 출력된다.
정규식을 쓸 때
- re.compile("원하는 형태")
- m = p.match() 또는 search() 또는 lst = p.findall()
원하는 형태는 . 일 때는 하나의 문자
^는 문자열의 시작, $는 문자열의 끝
이도 더 자세한 공부를 하고 싶으면 w3school의 Learn python 또는 점프투파이썬 등을 통해 할 수 있다.
User Agent
웹사이트에서는 접속을 하는 사용자들의 정보를 알 수 있다.
이를 헤더 정보라고 하는데 이를 활용하는 예시 중 하나가 폰으로 접속했을 때 모바일 페이지, pc로 접속했을 때 데스크탑 페이지가 뜨는 것이다.
그런데 헤더를 통해 크롤링을 한다는 것을 읽게 되면 이를 차단할 수 있다.
이를 user agent를 통해 해결할 수 있다.
import requests
res = requests.get("http://nadocoding.tistory.com")
res.raise_for_status()
with open("nadocoding.html", "w", encoding="utf8") as f:
f.write(res.text)일단 티스토리가 헤더를 변경하지 않아도 정상적으로 html을 받아오게 되었지만 강의에서 티스토리를 통해 강의를 진행하므로 그대로 이 링크의 html을 받아오는 것을 헤더를 변경하여 해보겠다.
https://www.whatismybrowser.com/detect/what-is-my-user-agent/
여깃 접속하면 뜨는 파란 내용이 나의 UserAgent인데 크롬이 아닌 Edge로 접속하면 내용이 달라진다.
즉, 접속하는 브라우저에 따라 UserAgent의 내용은 달라진다.
import requests
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"}
url = "http://nadocoding.tistory.com"
res = requests.get(url, headers=headers)
res.raise_for_status()
with open("nadocoding.html", "w", encoding="utf8") as f:
f.write(res.text)이렇게 하면 헤더에 담기는 UserAgent의 정보가 변경된다.
참고로 헤더는 없을 수도 없다.
UserAgent도 막는 데도 아닌 데도 있고, referer도 막는 데도 아닌 데도 있다.
Tip.
https://goddaehee.tistory.com/169를 참고하여 쓴 글이다.
Request : 요청
따라서 리퀘스트 헤더는 요청에 대한 정보를 담는다.
Response : 응답
리스폰스 헤더는 응답에 대한 정보를 담는다
- 공통 헤더 (요청과 응답에 모두 사용되는 헤더)


여기서 언어는 한국어, 일본어 같은 실재 의사소통에 사용하는 언어를 의미한다.
- 요청 헤더

즉, 호스트 헤더는 어디로 요청을 보내느냐는 것이다.

이 Referer를 보고 접근 권한을 주는 경우도 있다.
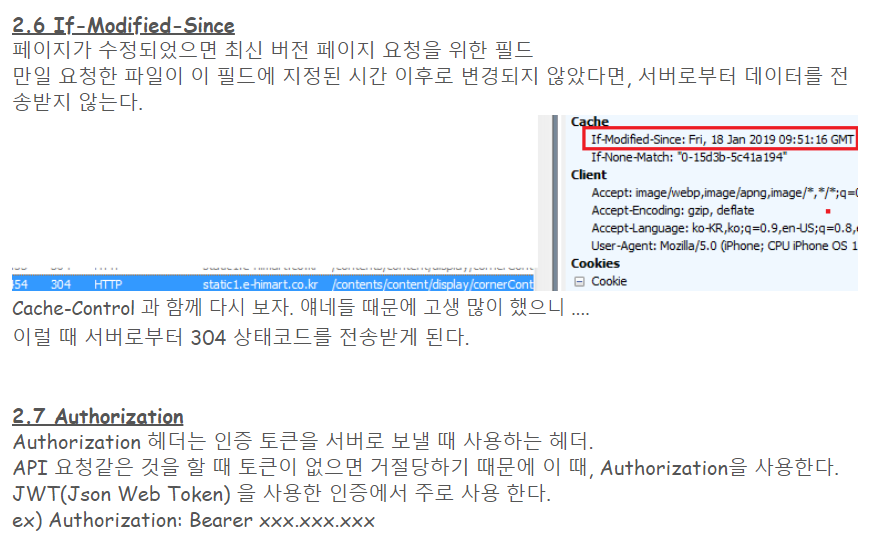
- 응답 헤더

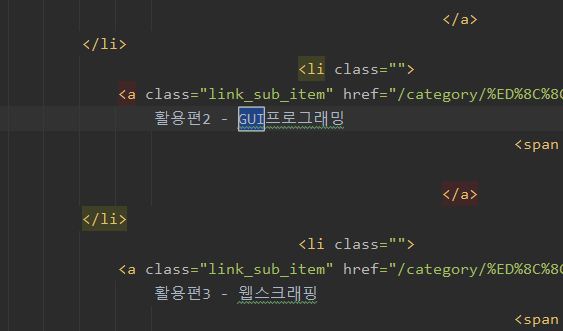
여하튼 위의 코드를 실행하여 얻은 html파일을 파이참으로 열어보고 나도코딩 티스토리 페이지에서 볼 수 있는 특정 키워드를 검색하면
위와 같은 결과를 얻을 수 있음을 볼 수 있다.
