이 글은 https://velog.io/@mjhuh263/TIL-23-HTML-XPATH-%EB%AC%B8%EB%B2%95%EA%B3%BC-selenium%EC%97%90-XPATH-%EC%9D%B4%EC%9A%A9%ED%95%98%EA%B8%B0 를 공부하며 쓴 글임을 명시합니다.
XPATH : Extensible Markup Language
(extensible : 펼 수 있는)
마크업 언어란 : 태그 등을 이용하여 문서나 데이터의 구조를 명기하는 언어의 한가지이다.
태그는 원래 텍스트와는 별도로 원고의 교정부호와 주석을 표현하기 위한 것이었으나 용도가 점차 확장되어 문서의 구조를 표현하는 역할을 하게 되었다. 이러한 태그 방법의 체계를 마크업 언어라 한다.
일반적으로 데이터를 기술하는 정도로만 사용되기에 프로그래밍 언어와는 구별된다.
단, MXML이나 XAML처럼 특정 프로그래밍 언어와 강하게 연관되어 기능하거나 제한적으로 프로그래밍 언어의 기능을 갖춘 것도 일부 있는데 이런 경우에는 구별이 명확하지 않다.
컴퓨터에서 디렉토리에 접근하는 방식과 마찬가지로 xml도 원하는 태그나 속성을 찾기 위해 path문법이 나왔다.
xml : W3C에서 개발된, 다른 특수한 목적을 갖는 마크업 언어를 만드는데 사용하도록 권장하는 다목적 마크업 언어이다. XML은 SGML의 단순화된 부분집합으로, 다른 많은 종류의 데이터를 기술하는 데 사용할 수 있다.
sgml은 문서용 마크업 언어를 정의하기 위한 메타 언어이다.
(메타언어란 다른 언어를 기술하거나 분석하기 위하여 사용되는 언어이다. 가령 영어 문법을 한국어로 논할 때 한국어는 메타언어가 된다.)
xml은 주로 다른 종류의 시스템, 특히 인터넷에 연결된 시스템끼리 데이터를 쉽게 주고 받을 수 있게 하여 HTML의 한계를 극복할 목적으로 만들어졌다.
XPATH는 웹이 기록된 정보들에 접근하는 방식을 다룬 문법이며 XPATH는 다루고 싶은 모든 element들을 node단위로 처리한다.
노드 종류
element node 태그
(컴퓨터 용어에서 태그란 어떠한 항목을 보충 설명하는 낱말 혹은 키워드이다.
HTML태그는 HTML문서를 이루는 문법적 표시이다.
즉, 데이터가 어떤 정보로 이루어져있는지 알려주는 데이터(메타데이터)이다.)
attribute node 속성
text node 태그의 내용
namespace node 각 tag의 identify를 위해 붙이는 xmlns:prefix="URL"형식의 attribute
(identify : 확인하다)
processing-instruction node 어떤 instruction을 수행함(<? 태그로 시작)
comment node 주석문
root node xml 자체를 표현하는 가상 노드
이 중 가장 많이 사용되는 node는 element, attribute, 그리고 text이다.
element node
컴퓨터 디렉토리는 중복을 허용하지 않지만 웹 특성상 중복 태그가 흔하며, XPATH는 중복 태그 및 특정 노드에 대한 접근이 가능하다. 만약 li 태그로 가고 싶다고 가정하자. 컴퓨터 디렉토리라면 body/ul/li라고 적을 것이다. 그러나 XPATH에서는 중복태그가 허용되며 이 코드에는 지금 li태그가 두개이다. 여기서 특정 노드를 지정하고 싶다면 배열을 사용한다.
배열 사용
중복되는 태그는 배열 개념을 이용해 [1],[2] 이런 식으로 특정 노드를 고른다 물론 수식을 사용할 수 있다.
예을 들어 num처럼 num의 값 이하, 또는 이상인 모든 항목도 리턴할 수 있다.
ex) /body/ul/li[num > 2]를 사용하면 num의 값이 2보다 큰 모든 li를 리턴한다.
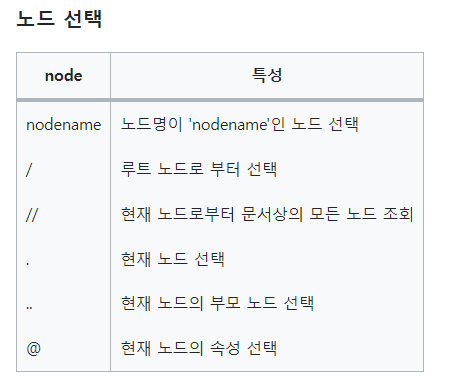
여기서 만약 nodename만 사용하면 nodename에 해당되는 모든 태그를 불러올 수 있다.
ex) /body/ul/li로 '넘버원' '넘버투'가 들어있는 태그 둘 다 가져올 수 있다.
모든 태그
//를 사용해 하위 태그를 모두 찾을 수 있다.
//ul 이라고 쓸 경우 모든 ul을 찾아주며, ul//li라고 적을 경우 ul안에 있는 모든 li를 찾아준다.
여기서 주의해야 할 점은 li는 ul태크 안에 있기 때문에 그냥 li라고 쓰면 아무 것도 못 찾는다.
element 노드는 가장 많이 쓰는 노드이기 때문에 별도의 표기 없이 사용 가능하다.
attribute node
attribute node는 앞에 @를 붙인다. 속성을 가진 element를 찾고 싶다면
element_node[@attribute_node]를 사용하면 된다.
ex) //span[@style]:styleattribute 를 가지고 있는 span 태그의 모든 element 노드를 가져온다.
text node
text()를 사용한다. element node 안에 존재하기 때문에 element node를 먼저 써야 한다.
//span/text() : 모든 span 태그 안에 있는 text node 추출
//text() : 모든 태그 안의 text추출