이 게시글은 윤성우 선생님의 자료구조 강의를 수강 후 나름대로의 내용 정리를 한 것임을 미리 밝힙니다.
스스로의 복습을 위해 작성한 글이므로 심층있는 학습을 위해서는 책의 구매 및 강의수강을 권장합니다.
1. 퀵 정렬
(1) 이론


(2) 이론 공부 후 구현해본 코드
퀵 정렬을 공부 후
https://www.acmicpc.net/problem/2750 를 해결한 코드이다.
수 정렬하기 2 ~ 5는 이미 정렬된 수열은 시간복잡도가 n^2이므로 해결하지 못하기에 퀵 정렬로 풀 수 없는 문제이다.
#include <stdio.h>
int array[1000];
void qsort(int left, int right)
{
if (left >= right) return;
int pivot = array[left];
int low = left + 1; // low가 low인 이유 : 우선 순위가 낮기 때문, 다 오른편으로 던질 것들
int high = right; // high가 high인 이유 : 우선 순위가 높기 때문, 다 왼편으로 던질 것들
int temp;
while (pivot >= array[low]&&low<=right) low++;
while (pivot <= array[high]&&high>left) high--;
if (low > right)// 5 4 3 2 1같이 우선순위가 모두 높은 경우, 4 3 2 1 5와 같이 바꿔주면 된다.
{
array[left] = array[right];
array[right] = pivot;
qsort(left, right - 1);
return;
}
if (high <= left)// 1 2 3 4 5 같이 우선 순위가 모두 낲은 경우
{
qsort(left + 1, right);
return;
}
while (low <= high)//안이 참인동안 동작, low > high인 순간 동작 중지
{
temp = array[low];
array[low] = array[high];
array[high] = temp;
while (pivot >= array[low]) low++;//pivot의 우선순위가 낮은 동안 동작, 즉 멈췄을 때는 pivot보다 array[low]의 우선순위가 더 높을 때
while (pivot <= array[high]) high--;
}
array[left] = array[high];//위의 과정을 거친 후 나온 high는 low와 high가 교차한 후 최초의 high 즉, 우선순위가 피버보다 높은 성분 중 가장 오른쪽의 성분이다.
array[high] = pivot;
qsort(left, high - 1);
qsort(high + 1, right);
return;
}
int main()
{
int i, N;
scanf("%d", &N);
for (i = 0; i < N; i++)
{
scanf("%d", &array[i]);
}
qsort(0, N - 1);
for (i = 0; i < N; i++)
{
printf("%d\n", array[i]);
}
return 0;
}
느낀 점 - 함수를 호출하면 F10과 조사식을 이용한 디버깅이 좀 힘들어진다.
함수의 중간과정에서 일어나는 일이 궁금하면 printf를 적극활용하자
손으로 직접 써가면서 과정을 살펴보는 방법도 있으나, 이는 꽤 힘든 과정이다.
차라리 어디서 문제가 생기는지 printf를 통해 확인한 후 그 부분만 손으로 써가며 고민해보는게 좋을 것이다.
(3) 강의는 아니고 좀 더 세련된 코드// 강의의 코드에 의문이 생겨 강의는 수강치 않기로 결정.
void qsort(int left, int right)
{
if (left >= right) return;
int pivot = array[left];
int low = left + 1; // low가 low인 이유 : 우선 순위가 낮기 때문, 다 오른편으로 던질 것들
int high = right; // high가 high인 이유 : 우선 순위가 높기 때문, 다 왼편으로 던질 것들
int temp;
while (low <= high)//이러면 low<=high이면 바로 검사 종료!
{
if (pivot >= array[low]) low++;//array[low]의 우선순위가 높은동안 low움직이고 낮으면 여기 진입 X
else if (pivot <= array[high]) high--;
else {//low가 우선순위가 낮은 성분, high가 높은 성분을 가리킬 때 진입
temp = array[low];
array[low++] = array[high];
array[high--] = temp;
}
}
array[left] = array[high];
array[high] = pivot;
qsort(left, high - 1);
qsort(high + 1, right);
}(4) 피벗 선택에 대한 논의
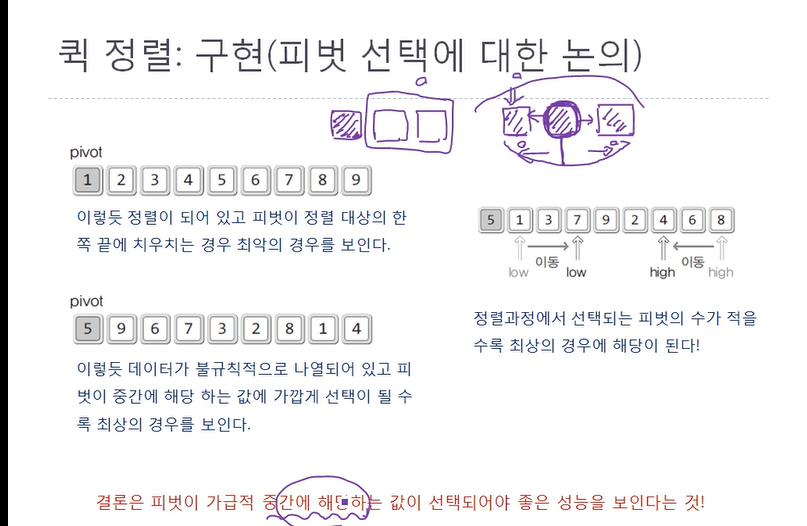
정렬이 되어 있고 피벗이 정렬대상의 한 쪽 끝에 치우치는 경우 최악의 경우를 보이므로 피벗은 가급적 중간에 해당하는 값이 선택되어야 좋은 성능을 보인다.
-> 중간에 해당하는 값이면 나머지 값들이 모두 피벗 기준으로 좌우로 정렬되기 때문.
-> 최대 혹은 최소가 피봇으로 선택되면 정렬이 전혀 되지 않는다.
그럼 어떤 식으로 pivot을 선택할 것인가? ->
배열이 무질서하다면 pivot을 어떻게 선택하든 상관이 없으나, 그렇지 않다면?
예시
1. 배열의 left, mid, right 중 중간값을 pivot으로 선택
2. 배열의 앞의 세개를 선택해서 이 중의 중간값을 pivot으로 선택한다.
다시 한번 결론을 이야기하자면 피벗이 가급적 중간에 해당하는 값이 선택되어야 좋은 성능을 보인다는 것.
(5) 퀵 정렬 성능 평가
최선의 경우 ->
Best case는 가급적 중간값이 선택될 때인데,
이를 위해 우리가 left, right, mid중 중간값을 선택하는 등의 노력을 기하기 때문에
사실상 이를 일반적인 경우로 보아도 무방하기 때문에 최선의 경우지만 사실상 일반적인 경우로 취급한다.
n개의 데이터가 퀵 정렬의 경우
8개를 예로 들면 8 -> 4/4 -> 2/2/2/2 -> 1 이 된다 가정하면 3번이면 된다.
(한번에 절반씩 공간이 나누어진다)
이런 식이면 퀵 정렬은 log_2 n 회 나누어지면 정렬이 끝난다.
그리고 한번 나누어질 때마다 (나누어진 구간의 데이터 개수 - 1)번의 연산이 진행되므로 대락 n번의 연산이 진행된다고 가정할 수 있다.
즉, 퀵 정렬은 O(n log_2 n)의 시간 복잡도를 가진다.
하지만 최악의 경우도 생각해야 한다. (최악의 경우 Big O 는 n^2이기 때문)
-> 중간값을 선택하려는 노력을 조금만 하더라도 퀵 정렬은 최악의 경우는 만들지 않는다.
퀵 정렬은 O(nlogn)의 성능을 보이는 정렬 알고리즘 중에서 편균적으로 가장 졸은 성능을 보이는 알고리즘이다.
다른 알고리즘에 비해서 데이터의 이동이 적고 -> 힙 정렬은 삽입과 출력 모두에서 계속해서 데이터가 이동, 병합 정렬 역시 한번 함수가 호출될 때마다 데이터가 굉장히 많이 이동
별도의 메모리 공간을 요구하지도 않는다. -> 힙 정렬도 힙을 따로 만들어야 하고, 병합정렬도 정렬을 해서 옮길 다른 배열 하나를 만들어야 한다.
