https://www.acmicpc.net/problem/11725
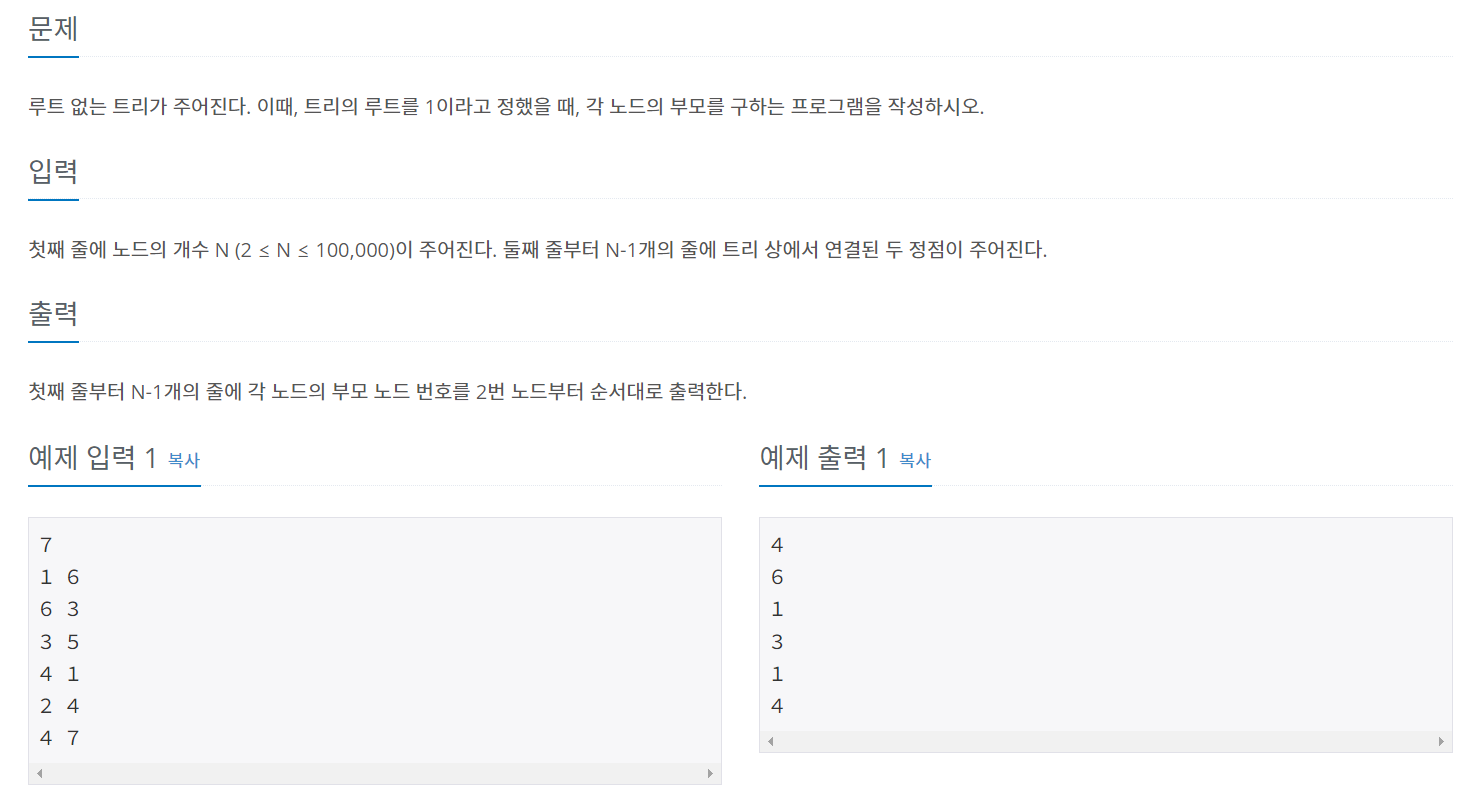
1. 알고리즘
예제1에 따라 구현되는 그래프

탐색에 따라 정답배열에 저장되는 숫자
정답배열의 n번째 칸에는 노드 n의 부모 노드를 입력할 것이다.
예를 들어
1과 연결된 것은 모두 1의 자식노드이므로 정답배열에 1을 입력한다.
그리고 자식 노드들에 대해 다음과 같은 과정을 반복한다.
어떤 수 y의 자식 노드가 x이면 이후 x에 연결된 노드들을 탐색한다.
이 중 이미 부모 노드를 기록한 노드를 제외한 모든 노드의 부모 노드를 x로 기록한다.
트리의 위쪽이 먼저 탐색되므로 순서가 틀릴 이유는 없다.
2. 나의 첫번째 코드
DFS를 활용하였다.
시간이 204ms가 걸렸다. 170명중 160등대...
다른 방법을 찾아보기로 하였다.
#include <stdio.h>
#include <stdlib.h>
int array[100001];// array[n]에는 n이랑 연결된 노드 개수 추가
int brray[100001];
typedef struct node
{
int data;
struct node* next;
}Node;
Node* Array[100001];
void Find(int n)
{
int i;
Node* cur;
cur = Array[n];
for (i = 1; i <= array[n]; i++)
{
cur = cur->next;
if (brray[cur->data] == 0)//brray에 저장된게 없으면 처음 만난게 부모 노드
{
brray[cur->data] = n;//array[n][i]의 부모노드로 n을 추가
Find(cur->data);//자식 노드를 찾으러 떠난다.
}
}
return;
}
int main()
{
int i, j, N;
int x, y;
int count = 0;
Node* cur;
scanf("%d", &N);
for (i = 1; i <= N; i++)
{
Array[i] = (Node*)malloc(sizeof(Node));
Array[i]->next = NULL;
}
for (i = 0; i < N - 1; i++)
{
scanf("%d %d", &x, &y);
array[x]++;//array[x]에는 그 성분과 연결된 노드의 개수를 저장
cur = Array[x];
for (j = 0; j < array[x] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = y;
cur->next->next = NULL;
array[y]++;
cur = Array[y];
for (j = 0; j < array[y] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = x;
cur->next->next = NULL;
}
Find(1);
for (i = 2; i <= N; i++)
{
printf("%d\n", brray[i]);
}
return 0;
}
3. 두번째 코드, 세번째 코드
모두 BFS로 풀었다.
하나는 이미 Queue에 들어오는 것의 개수를 아므로 Queue에 있는 수를 빼서 탐색하는 과정을 정점의 개수 N회만큼 하기로 하였고
하나는 정석적으로 Queue가 다 비면 BFS의 탐색을 종료하게 하였다.
후자는 반복문에서 비교연산을 하기 때문에 좀 더 시간이 오래 걸렸다.
걸린 시간은 각가 200ms와 208ms
대책을 강구하는 것이 필요했다.
두번째 코드
#include <stdio.h>
#include <stdlib.h>
int array[100001];// array[n]에는 n이랑 연결된 노드 개수 추가
int brray[100001];
int Queue[100000] = { 1 };
int entrance = 1;
typedef struct node
{
int data;
struct node* next;
}Node;
Node* Array[100001];
void Find(int n)//찾아갈 숫자
{
int i;
Node* cur;
cur = Array[n];
for (i = 1; i <= array[n]; i++)
{
cur = cur->next;
if (brray[cur->data] == 0)//brray에 저장된게 없으면 처음 만난게 부모 노드
{
brray[cur->data] = n;//array[n][i]의 부모노드로 n을 추가
Queue[entrance++] = cur->data;
}
}
return;
}
int main()
{
int i, j, N;
int x, y;
int count = 0;
Node* cur;
scanf("%d", &N);
for (i = 1; i <= N; i++)
{
Array[i] = (Node*)malloc(sizeof(Node));
Array[i]->next = NULL;
}
for (i = 0; i < N - 1; i++)
{
scanf("%d %d", &x, &y);
array[x]++;//array[x]에는 그 성분과 연결된 노드의 개수를 저장
cur = Array[x];
for (j = 0; j < array[x] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = y;
cur->next->next = NULL;
array[y]++;
cur = Array[y];
for (j = 0; j < array[y] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = x;
cur->next->next = NULL;
}
for (i = 0; i < N; i++)
{
Find(Queue[i]);//Queue는 계속 차고 N개의 노드가 모두 Queue에 한번씩 들어갈 것을 알기 때문에
}
for (i = 2; i <= N; i++)
{
printf("%d\n", brray[i]);
}
return 0;
}
세번째 코드
#include <stdio.h>
#include <stdlib.h>
int array[100001];// array[n]에는 n이랑 연결된 노드 개수 추가
int brray[100001];
int Queue[100000] = { 1 };
int entrance = 1;
typedef struct node
{
int data;
struct node* next;
}Node;
Node* Array[100001];
void Find(int n)//찾아갈 숫자
{
int i;
Node* cur;
cur = Array[n];
for (i = 1; i <= array[n]; i++)
{
cur = cur->next;
if (brray[cur->data] == 0)//brray에 저장된게 없으면 처음 만난게 부모 노드
{
brray[cur->data] = n;//array[n][i]의 부모노드로 n을 추가
Queue[entrance++] = cur->data;
}
}
return;
}
int main()
{
int i, j, N;
int x, y;
int count = 0;
Node* cur;
scanf("%d", &N);
for (i = 1; i <= N; i++)
{
Array[i] = (Node*)malloc(sizeof(Node));
Array[i]->next = NULL;
}
for (i = 0; i < N - 1; i++)
{
scanf("%d %d", &x, &y);
array[x]++;//array[x]에는 그 성분과 연결된 노드의 개수를 저장
cur = Array[x];
for (j = 0; j < array[x] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = y;
cur->next->next = NULL;
array[y]++;
cur = Array[y];
for (j = 0; j < array[y] - 1; j++)
{
cur = cur->next;
}
cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = x;
cur->next->next = NULL;
}
for (i = 0; i != entrance; i++)//i는 출구, i가 entrance라는 것은 큐가 비었다는 것
{
Find(Queue[i]);
}
for (i = 2; i <= N; i++)
{
printf("%d\n", brray[i]);
}
return 0;
}
네번째 코드
많은 수정을 가했다.
걸린 시간부터 말하자면 88ms
일단 array에 원래는 각 배열의 헤드 노드에 연결된 노드의 개수를 저장했는데
Find함수안의 for문을 while문으로 바꾸고 연결된 노드의 개수가 필요없게 만들었다.
사실 마지막은 늘 next가 NULL이므로 그렇게 만드는게 더 쉽기도 했고
대신 새로운 노드를 저장할 때, 현재의 마지막 노드를 찾는 연산이 꽤 걸렸는데
현재의 마지막 노드를 찾는 연산을 하지 않기 위해 array[n]에 숫자 n과 연결된 정점을 저장한 배열의 마지막 노드의 주소를 저장했다.
이렇게 수정하니 시간이 획기적으로 줄었다.
하지만 아직 170명 중 100등대
중간을 가지 못했다.
다른 방법을 강구해보았다.
이후 Queue에서 숫자를 빼내서 다시 BFS를 수행하는 과정에서 비교연산을 빼서 76ms로 줄였다.
#include <stdio.h>
#include <stdlib.h>
int brray[100001];
int Queue[100000] = { 1 };
int entrance = 1;
typedef struct node
{
int data;
struct node* next;
}Node;
Node* array[100001];// array에는 각 숫자의 마지막으로 연결된 정점의 주소를 저장
Node* Array[100001];
void Find(int n)//찾아갈 숫자
{
int i;
Node* cur;
cur = Array[n];
while(cur->next != NULL)//cur->next == NULL인 순간 종료
{
cur = cur->next;
if (brray[cur->data] == 0)//brray에 저장된게 없으면 처음 만난게 부모 노드
{
brray[cur->data] = n;//array[n][i]의 부모노드로 n을 추가
Queue[entrance++] = cur->data;
}
}
return;
}
int main()
{
int i, j, N;
int x, y;
int count = 0;
Node* cur;
scanf("%d", &N);
for (i = 1; i <= N; i++)
{
array[i] = Array[i] = (Node*)malloc(sizeof(Node));//대입연산자 여러개 한줄에 써도 된다.
Array[i]->next = NULL;
}
for (i = 0; i < N - 1; i++)
{
scanf("%d %d", &x, &y);
cur = array[x];
array[x] = cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = y;
cur->next->next = NULL;
cur = array[y];
array[y] = cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = x;
cur->next->next = NULL;
}
for (i = 0; i != entrance; i++)//i는 출구, i가 entrance라는 것은 큐가 비었다는 것, 비교연산 때문에 시간이 좀 더 길어졌다.
{
Find(Queue[i]);
}
for (i = 2; i <= N; i++)
{
printf("%d\n", brray[i]);
}
return 0;
}
마지막 코드
10만 + 1칸짜리 Node형 배열을 하나 더 만들어서 그 배열의 주소 한칸 한칸을 각각 헤드 노드로 사용하여 malloc을 10만번 하던 것을 없앴다.
시간은 64ms로 처음에 비해 굉장히 많이 줄였다고 생각한다.
170명 중 57등으로, 입출력시간을 줄이거나 하면 훨씬 줄일 자신이 있었으나 지금이 가장 깔끔한 것 같아서 여기까지 하기로 하였다.
시간을 줄이기 위해 이렇게 노력해본 것이 오랜만인듯 하였다.
스스로 만족할만한 결과를 얻어 기쁘다.
#include <stdio.h>
#include <stdlib.h>
int brray[100001];
int Queue[100000] = { 1 };
int entrance = 1;
typedef struct node
{
int data;
struct node* next;
}Node;
Node* array[100001];// array에는 각 숫자의 마지막으로 연결된 정점의 주소를 저장
Node* Array[100001];
Node arr[100001];
void Find(int n)//찾아갈 숫자
{
int i;
Node* cur;
cur = Array[n];
while(cur->next != NULL)//cur->next == NULL인 순간 종료
{
cur = cur->next;
if (brray[cur->data] == 0)//brray에 저장된게 없으면 처음 만난게 부모 노드
{
brray[cur->data] = n;//array[n][i]의 부모노드로 n을 추가
Queue[entrance++] = cur->data;
}
}
return;
}
int main()
{
int i, j, N;
int x, y;
int count = 0;
Node* cur;
scanf("%d", &N);
for (i = 1; i <= N; i++)//대입연산자 여러개 한줄에 써도 된다.
{
array[i] = Array[i] = arr + i;//arr + i를 하면 자동으로 arr[i]의 주소를 가져온다.
Array[i]->next = NULL;
}
for (i = 0; i < N - 1; i++)
{
scanf("%d %d", &x, &y);
cur = array[x];
array[x] = cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = y;
cur->next->next = NULL;
cur = array[y];
array[y] = cur->next = (Node*)malloc(sizeof(Node));
cur->next->data = x;
cur->next->next = NULL;
}
for (i = 0; i < N; i++)//큐에 들어올 데이터의 개수를 알기에 할 수 있는 연산, 원래는 비교연산을 통해 큐가 비었는지 확인해야 한다.
{
Find(Queue[i]);
}
for (i = 2; i <= N; i++)
{
printf("%d\n", brray[i]);
}
return 0;
}
얻은 것 정리
-
cur = cur -> next를 많이 반복하면 시간이 오래 걸린다.
저장의 경우 마지막 노드의 주소를 저장하는 배열을 만드는 것이 훨씬 성능이 좋다. -
한 줄에 대입 연산자를 여러개 쓸 수 있다.
[실험]
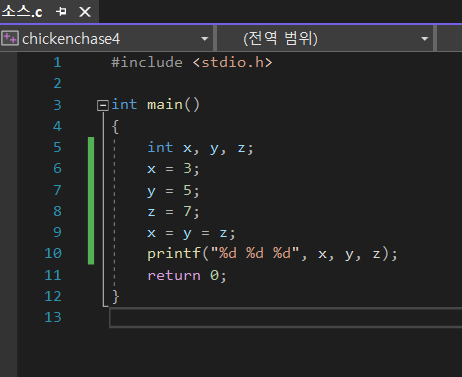
[결과]

-
malloc은 생각보다 시간이 걸린다.
한번은 괜찮으나 반복해서 사용할 시 줄일 수 있는 방법을 생각하는 것이 좋다. -
이건 얻은 지식은 아니나 평소에 DFS에 익숙했는데 BFS를 한번 더 연습할 수 있어서 좋았다. 앞으로도 계속 이런 그래프 문제를 풀어나가며 시간복잡도를 고려하여 DFS와 BFS 중 적절한 걸 골라 풀어보는 연습을 해야겠다.
