✏️병렬프로그래밍
과거에는 슈퍼컴퓨터에만 적용되어 왔던 병렬컴퓨터 아키텍처가 현재 일반 PC에도 범용적으로 채택되어 컴퓨터의 성능 향상에 많은 기여를 한다.
현재 멀티코어 시대에서는 프로세서 간의 협력을 최상으로 끌어내기 위해 소프트웨어 설계를 어떻게 하는 것이 중요하게 되었다.
- 순차처리
- 문제가 일련의 개별 명령어로 나누어져있다.
- 명령어들은 순차적으로 하나씩 단일 프로세서에 실행이 된다.- 병렬처리
- 문제가 동시에 해결할 수 있는 독립적인 부분들로 나눌 수 있다.
- 부분화된 작업들은 서로 다른 프로세서에서 동시에 실행된다.
- 동시에 작업하는 과정은 항상 제어와 조정의 알고리즘이 필요하다.
✔️병렬화
순차적인 직렬 프로그램을 분할하고 분할된 단위를 동시에 병렬로 수행함으로써 성능을 향상시키는 프로그래밍 기술이라한다.
하나의 큰 문제를 해결하기 위해 문제들을 분할하여 동시에 처리함으로써, 문제 해결에 드는 시간 및 비용을 절약하기 위해 이러한 방식을 사용한다.
그러나, 병렬 처리를 하는 과정에서 큰 문제를 작은 문제들로 분할하는 과정이 어렵다. 분할을 하더라도 다시 부분 문제의 답을 모아 전체 문제의 답을 재구성하는 과정 또한 어려움이 따른다. 늘 병렬 처리하는 과정에서 발생하는 문제인 데이터 간의 의존성과 동기화의 문제도 고려해야한다.
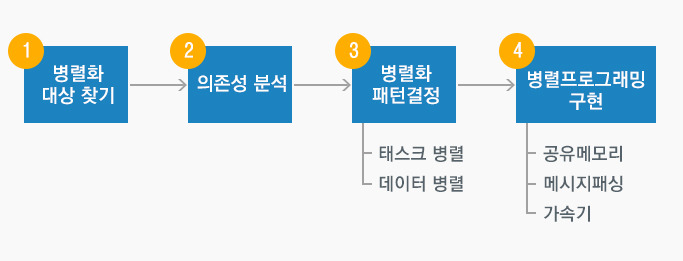
✔️병렬화 과정
-
병렬프로그래밍을 구현하기 위해서는 가장 먼저 성능의 병목지점인 병렬화 대상을 찾아야한다.
-
실제 병렬화가 가능한지에 대한 의존성 분석과 병렬화를 어떤 방식으로 진행할 건지 패턴 결정이 필요하다.
✔️ 병렬화 패턴 결정
데이터 병렬화(벡터화)
어떠한 데이터 집합을 분해한 뒤, 각 프로세서에 할당하여 동일한 연산을 수행하는 기술이다.

A[n]+B[n] = C[n]이라는 연산을 처리할 때, 순차처리 방식에서는 For문 내의 각 데이터 연산이 순서대로 수행되기 때문에 시간이 많이 소요된다. 하지만 연산을 처리하는 Core가 n개이고 각 연산이 서로 의존성이 없는 경우, 동시에 병렬처리가 가능하게 됩니다.
태스크 병렬화
수행해야 할 작업들을 기능 별로 분해한 뒤, 각 프로세서에 할당하여 서로 다른 기능들을 동시에 수행하는 기술이다.
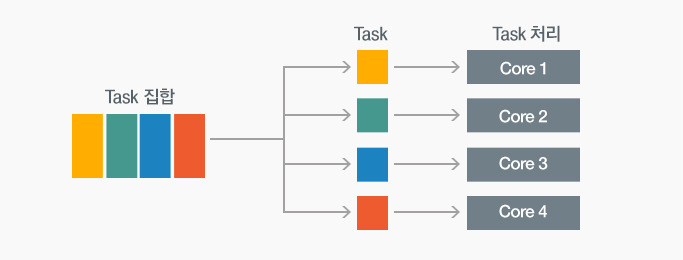
Task1에는 I/O 작업, Task2에는 연산 작업 등을 맡겨 서로 다른 기능들이 동시에 수행할 수 있게끔 하는 기술이 바로 태스크 병렬화라고 한다. 보통 기능적 단위로 수행되기 때문에 범용 CPU를 활용한 병렬컴퓨터 구조에서 주로 구현이 가능하며, 멀티스레드 방식에서는 하나의 스레드가 하나의 Task를 맡아 수행하는 구조로 동작된다.
✔️ 병렬프로그래밍 구현
공유 메모리 병렬프로그래밍 모델
공유 메모리 시스템 구조에 적합한 방식으로써 다수의 코어의 협력을 통해 병렬화를 수행하는 모델이다.
여러 개의 스레드를 생성한 후 다수의 코어로 분배하여 병렬처리를 수행한다.메세지 패싱 프로그래밍 모델
분산 메모리 시스템 구조에 적합한 병렬 프로그래밍 모델이다.
메모리 공유 방식이 아니기 때문에 노드 간에 서로 네트워크를 통해 메시지를 주고받는 형태로 정보를 공유한다.
네트워크 상의 통신 속도가 성능의 매우 중요한 요소로, 고속의 연산처리를 필요로하는 슈퍼컴퓨터에 많이 사용된다.가속기 프로그래밍 모델
위 두 모델과 달리 범용 CPU가 아닌 특정 연산에 특화된 가속기를 활용하여 병렬화하는 모델이다.
수치계산에 최적화된 CPU,DSP,GPU등을 활용한 프로그래밍 모델로 데이터 병렬화에 주로 사용한다.
✔️ 동기화
프로그램의 성능을 향상시키기 위해 병렬화를 할 때 늘 고려해야하는 것이 동기화이다.
여러 개의 Task들이 병렬로 실행될 때, 동일한 자원을 공유해야 하는 경우가 발생한다.
이러한 자원을 공유자원이라고 하는데 다수의 Task가 공유자원을 동시에 변경하고자 하는 경우 공유자원은 우리가 예상치 못한 값이 되어버릴 수가 있다.
따라서 하나의 Task가 공유자원을 변경하는 동안 다른 Task가 해당 자원을 변경하지 못하도록 원자성을 보장해야 할 필요가 있으며, 이를 해결하기 위한 방법이 바로 동기화입니다.
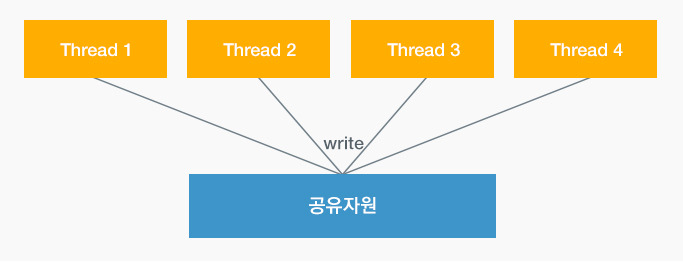
데이터 레이스(DATA RACE)
다수의 스레드들이 공유자원에 동시에 접근하는 상황을 뜻한다.
스레드들이 단순히 값을 Read하는 것은 문제가 되지 않지만, Write작업(값 변경)의 경우 예측하지 못한(=엉뚱한 값)을 참조하게 되어 결과값이 다르게 된다.
이러한 문제를 해결하기 위해서 하나의 스레드가 작업을 진행하는 동안 다른 스레드는 작업을 멈추고 대기하는 메커니즘이 필요하다.
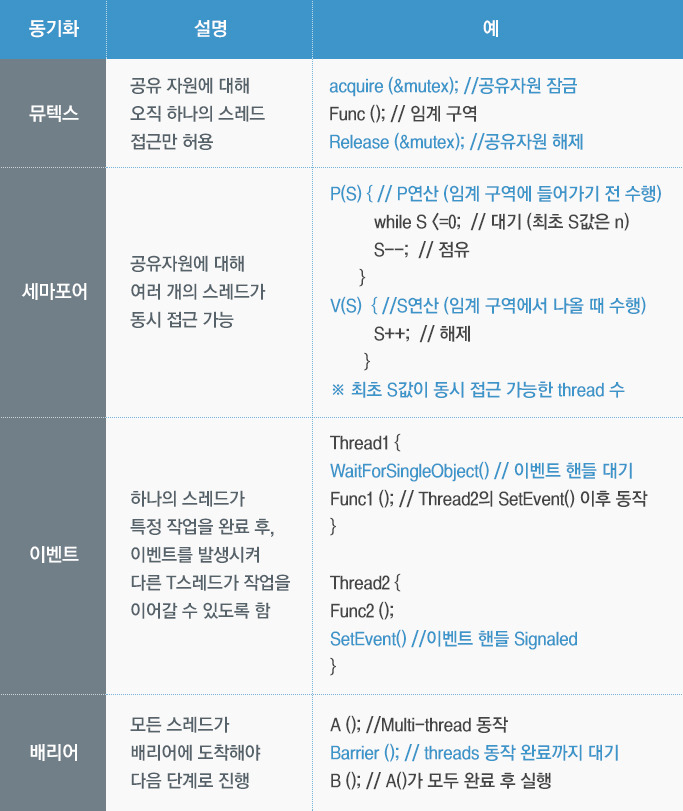
동기화 알고리즘
기본적으로 작업을 진행 중인 스레드는 Lock을 통해서 작업에 대한 독립성을 확보하고 나머지 스레드들은 Wait을 통해 대기하는 메커니즘을 가진다.
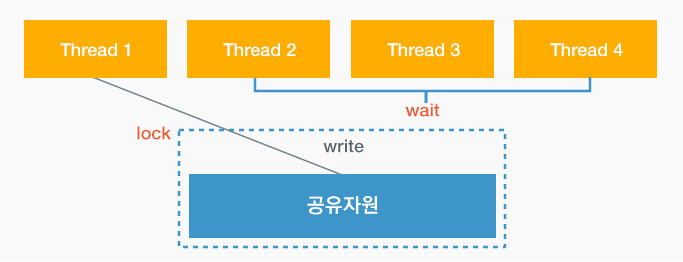
소프트웨어적으로 동기화 알고리즘을 구현할 수 있지만 OS에서도 동기화를 위한 장치들을 제공하고 있으므로 이를 활용하면 된다.
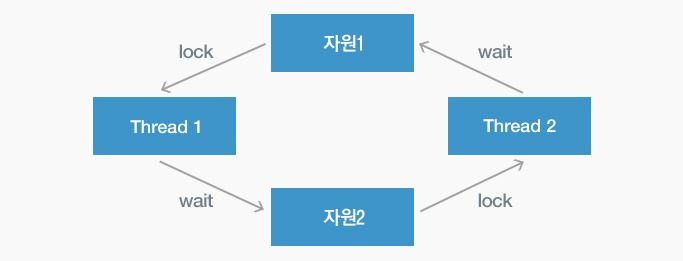
데드락
다수의 스레드들이 서로 다른 스레드가 점유하고 있는 자원이 해제(lock상태 해제)될 때까지 무한정으로 대기하는 상태를 말한다.
하나의 스레드가 특정자원을 독점하고 lock상태로 해제되지 않아 다른 스레드들이 무한히 wait상태에 빠지게 되는 상황이다.
1. 스레드가 공유자원을 unlock하지 않은 경우
코드를 작성할때 공유자원을 해제하는 코드를 넣지 않아서 발생한다
2. 스레드가 공유자원을 lock한 이후, 해당 스레드가 종료되는 경우
스레드가 어떤 오류로 강제 종료되는 경우 발생한다. 이러한 경우 예외 처리를 해서 공유자원을 해제 시키는 구문을 작성해야한다.
3. 스레드 간에 서로 자원을 요청하면서 대기 상태에 빠지게 되는 경우
자원을 점유하는 순서를 조정하여 이러한 상황이 발생하지 않게 예방해야한다.
[참고] https://www.samsungsds.com/kr/story/1233713_4655.html?referrer=https://ibocon.tistory.com/118
