
SQL 함수종류
숫자형 함수
abs(-3) -> 3
ceil(3.3) -> 4
floor(3.5) -> 3
exp(x) : e(자연상수)**x exp(2) -> 7.3890...
ln(2) : 밑이 e인 x의 로그 ln(2) -> 0.693134...
log(3,9) -> 2
log10(100) ->2
log2(8) -> 3
mod(6,4) -> 2 (6%4)
pow(2,3) -> 8 (2**3)
rand(n) : 0과 1 사이의 난수 반환, 함수 실행시 반환 값은 매번 다르지만 n에 같은 수 넣으면 같은 난수 반환
round(a,b) : a를 소수점 이하 b자리까지 반올림,
d 생략 시 0을 적용해 정수 반환,
d 음수이면 소수점 기준 왼쪽으로 기준점 이동
round(2.345,1) -> 2.3sign() : 매개변수가 0보다 크면 1, 0이면 0, 0보다 작으면 -1
sign(-5) -> -1sqrt(4) -> 2.0000... (제곱근)
truncate(a,b) : a를 소수점 이하 b자리에서 자름
truncate(2.345,1) -> 2.3
문자형 함수
-
char_length('정호준') -> 3 (문자열 길이)
-
length('정호준') -> 9 (문자열 바이트 수)
length('ab')=2 -
concat('a','b') -> ab
-
concat_ws('/','a','b') -> a/b
-
format(a,b) : 정수부분 3자리 마다 콤마를 추가해 문자열로 반환, 소수점 이하 b자리 까지 반올림
format(1234.12345,3) -> 1,234.123 -
instr('ABC','C') -> 3 ('ABC'에서 'C'위치를 찾아 시작위치 반환, python 인덱싱과 다름 유의!!)
-
locate(substr, str, pos) : str에서 substr문자열 찾아 시작위치 반환, pos에 값이 있을때 해당 위치부터 검색
-
replace('HoHoHo','o','O') -> HOHOHO
-
reverse('abcde') -> edcba
-
space(n) : n개의 공백 문자 반환
space(3)->' ' -
substr(str,pos,len) : str문자열의 pos위치에서 len만큼 문자를 잘라서 반환
substr('abcdef',2,2) -> 'bc' -
trim(both '#' from '##bc##')->bc
trim(leading '#' from '##bc##')->'bc##'
trim(trailing '#' from '##bc##')->'##bc' -
strcmp(str1,str2) : str1과 str2를 비교해 같으면 0, str1>str2 이면1, str1<str2 이면-1
날짜형 함수
-
curdate() -> 2022-04-12
-
curtime() -> 24:29:05 (시:분:초)
-
now() -> 2022-04-12 24:29:05
-
dayname('2022-04-12') -> Tuesday
-
dayofmonth('2022-04-12') -> 12
-
dayofweek('2022-04-12') -> 3 (1:일요일, 7:토요일)
-
dayofyear('2022-04-12') -> 102 (1년 기준 날짜를 일수로 반환)
-
last_day('2022-04-12') -> 2022-04-30 (date의 월의 마지막 날짜 반환)
-
year('2022-04-12') -> 2022
-
month('2022-04-12') -> 4
-
quarter('2022-04-12') -> 2 (분기 반환)
-
weekofyear('2022-04-12') -> 15 (date가 몇 주차인지 반환)
-
adddate('2022-04-12',10) -> 2022-04-22
-
extract(year_month from '2022-04-12') -> 202204 (year_month 자리에는 내가 추출하고 싶은 다른 unit도 사용가능)
-
sysdate() -> 2022-04-12 12:54:20
형 변환 함수
-
cast(expr as type)
-
convert(expr, type)
흐름제어 함수
if(expr, a, b) : expr이 참 -> a, 거짓 -> b
ifnull(expr1,expr2) : expr1 != null -> expr1, null -> expr2
nullif(expr1,expr2) : expr1 = expr2 -> null , expr1!=expr2 -> expr1
case
구문1
case value when compare_value1 then result1
when compare_value2 then result2
...
else result
end (name);구문2
case when 조건1 then result1
when 조건2 then result2
...
else result
end (name);
집계함수
-
count([distinct] expr): 전체 row수 -> group by를 한 후에 많이 사용
-
max([distinct] expr): 최댓값
-
min([distinct] expr): 최솟값
-
avg([distinct] expr): 평균
-
sum([distinct] expr): 합계
-
var_pop(expr): 분산
-
stdddev_pop(expr): 표준편차
-
+@
with rollup -> 총계 구하기
grouping() : 해당 값이 총계 -> 1, 나머지 -> 0
having절 : 집계함수에 대하여 where과 같이 조건을 붙일 때 사용
집계쿼리에서만 사용
having 다음에 집계함수만 옴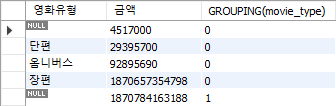
윈도우 함수
-
윈도우(window) : 특정 칼럼 값을 기준으로 지정한 로우 그룹
-
윈도우 함수 : 윈도우를 대상으로 연산하는 함수
FUNCTION NAME() over (PARTITION BY column1,column2 ORDER BY)
-
PARTITION BY : 윈도우 지정
-
ORDER BY : 윈도우로 지정된 로우의 순서
-
종류
row_number() : 로우의 순번
rank() : 순위
dense_rank() : 누적 순위
percent_rank() : 비율 순위
lag(expression,n) : 현재 로우의 n 앞 로우 값
lead(expression,n) : 현재 로우의 n 뒤의 로우 값
cume_dist() : 누적 분포 값
ntile() : 분할 버킷 수
first_value() : 지정된 범위에서 첫 번째 로우 값
last_value() : 지정된 범위에서 마지막 로우 값
nth_value() : 지정된 범위에서 n 번째 로우 값

Student , Junior Developer