
🍀 범주형 변수를 어떻게 다루어야 하는지 알아보자.
사전지식
- 범주형 변수: 수치로 나타낼 수 없는 변수
예를 들어혈액형(A형, B형 ..), 성별(여자, 남자) 또는 국가(한국, 미국, 일본, ...)와 같이 텍스트로 주어지는 것- 범주형 변수에는 명목형 변수와 순위형 변수가 있음
예를 들어달리기 순위라는 변수가 1위, 2위, 3위 와 같은 값으로 주어졌을 때, 순위형 변수로 볼 수 있음
- 각 값들 사이에 순위가 있는 것 순위형 변수
사용 데이터
웹 로그 기반 조회수 예측 해커톤
- 각 세션 별 조회수를 예측하기 위한 데이터로, 아래 ~~ 데이터 대상으로 범주형 데이터의 인코딩 방법을 알아보자.
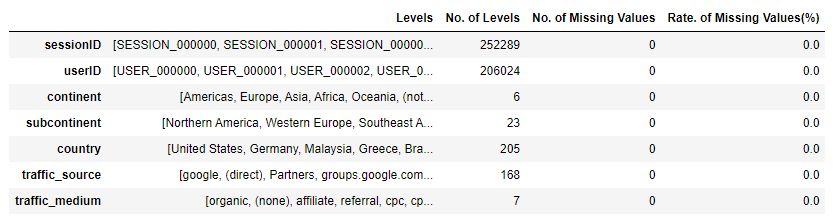
import pandas as pd import numpy as np import warnings train_df = pd.read_csv('data/train.csv', encoding = 'utf8')[['sessionID', 'userID', 'continent', 'subcontinent', 'country', 'traffic_source','traffic_medium']]
01. One-Hot Encoding
대상 컬럼: continent
1 ) get_dummies
- 가장 간단하게 One-Hot Encoding을 할 수 있음
❌ 대회에서 사용할 경우, Data Leakage로 판단될 위험이 있음
Test Dataset은 Train 시점에서 볼 수 없음을 가정하는데, get_dummies를 사용하면 Test Dataset에 Train Dataset에는 존재하지 않는 column이 추가될 수 있음
pd.get_dummies(train_df['continent'])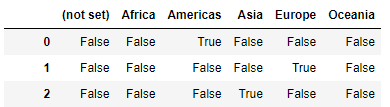
2 ) Sklearn One-Hot Encoding
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
train_df_onehot = train_df.copy()
# sparse_output의 default 값이 True일 경우, 희소 행렬을 사용하여 메모리나 수행 시간을 절약할 수 있음
# 희소 행렬이 아닐 경우에는 성능면에서 큰 차이 없음
# encoder = OneHotEncoder(sparse_output = True, handle_unknown ='ignore')
# encoder = encoder.toarray()
# Train Dataset에 없는 데이터를 처리할 수 있도록 handle_unknown parameter 값을 'ignore'로 전ㄴ달
encoder = OneHotEncoder(sparse_output = False, handle_unknown ='ignore')
train_encoded = encoder.fit_transform(train_df_onehot[['continent']])
encoded_columns = encoder.get_feature_names_out(['Brand'])
train_encoded_df = pd.DataFrame(train_encoded, columns=encoded_columns)
train_df_onehot = pd.concat([train_df_onehot, train_encoded_df], axis=1).drop(['continent'], axis=1)
display(encoded_columns)
display(train_df_onehot.head())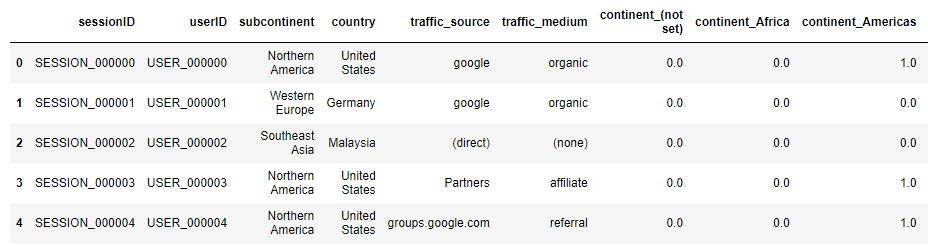
🍀 OneHotEncoder의
dropparameter 활용하기
- 위 결과에서 continent_Africa의 값이 1이면 나머지 continent들의 값은 0이 됨
- 반대로 continent_Africa의 값이 0이면 나머지 continent들 중 하나의 값이 0이 됨
데이터의 특성을 살려 첫 번째 column 제거 (drop=first)
👍 column이 binary 값인 경우에만 해당 처리를 하는if_binary옵션도 있음
🌼 One-Hot Encoding으로 인해 발생할 수 있는 다중공선성으로 인한 문제에 효과적인 방법이지만, 데이터의 대칭성이 깨져 모델에 영향을 줄 수 있으므로 주의
- 원문: Specifies a methodology to use to drop one of the categories per feature. This is useful in situations where perfectly collinear features cause problems, such as when feeding the resulting data into an unregularized linear regression model.
02. Label Encoding
sklearn Label Encoder
🌼 Label Encoding은 범주형 변수를 숫자로 치환해주는 함수
각 Label들이 순위나 크기의 의미를 가지지 않는 명목형 변수에 적합한 방식
from sklearn.preprocessing import LabelEncoder
import numpy as np
train_df_le = train_df.copy()
le_train = LabelEncoder()
train_df_le['continent'] = le_train.fit_transform(train_df['continent'])
display(train_df_le.head())
# Label Encoding된 값 확인하기
for i in range(len(le_train.classes_)):
display(f"{le_train.classes_[i]} ({i})")Test Dataset 처리하기
- Train Dataset에 없는 값이 존재할 수 있으므로 기타 값인 Other로 치환
test_df_le = test_df.copy()
# train_used_car 데이터셋의 라벨 인코더 클래스에 '기타' 범주를 다시 추가
le_train.classes_ = np.append(le_train.classes_, 'Other')
# 새로운 값들을 '기타'로 매핑
test_df_le['continent'] = test_df_le['continent'].apply(lambda x: x if x in le_train.classes_ else 'Other')
# 라벨 인코더 적용
test_df_le['continent'] = label_encoders[col].transform(test_df_le['continent'])👀 Label Encoding은 순서형 변수인 경우, 그 의미를 제대로 나타낼 수 없는 문제가 있음
Mapping 또는 Ordinal Encoding으로 값이 가지는 순서나 크기를 표현해줌
03. Mapping
continent를 기준으로 TARGET(조회수) 총 합계가 높은 순으로 순위를 매김
Continent Target Americas 561460.0 Asia 158027.0 Europe 149129.0 Africa 23919.0 Oceania 12752.0 (not set) 1093.0
train_df_mapping = train_df.copy()
continent_map = {'(not set)' : 0,
'Oceania' : 1,
'Africa' : 2,
'Europe' : 3,
'Asia' : 4,
'Americas' : 5 }
train_df_mapping['continent'] = train_df_mapping['continent'].replace(continent_map)
display(train_df_mapping.head())
display(train_df_mapping['continent'].dtype)
display(train_df_mapping['continent'].unique())04. Ordinal Encoding
from sklearn.preprocessing import OrdinalEncoder
train_ordinal = train_income.copy()
# OrdinalEncoder 초기화 및 범주 순서 지정
encoder_train = OrdinalEncoder(categories=[['(not set)', 'Oceania', 'Africa', 'Europe', 'Asia', 'Americas']])
# 'continent' 컬럼에 OrdinalEncoder 적용
train_ordinal['continent'] = encoder_train.fit_transform(train_ordinal[['continent']]).astype(int)
# 인코딩 순서 확인하기
display(encoder_train.categories_)
# 인코딩된 결과 확인
display(train_ordinal.head())
display(train_ordinal['continent'].dtype)
display(train_ordinal['continent'].unique())
05. Target Encoding
🍀 TARGET에 대한 기대값으로 대체 과적합의 우려가 있음
- Categorical Target인 경우: 주어진 특정 categorical 값과 training data 전반 Target의 사전 확률 Target의 사후확률을 조합한 값으로 대체
원문For the case of categorical target: features are replaced with a blend of posterior probability of the target given particular categorical value and the prior probability of the target over all the training data.
- Continuous Target인 경우: 주어진 특정 categorical 값과 training data 전반에 걸친 target의 기대값을 조합한 값으로 대체
원문For the case of continuous target: features are replaced with a blend of the expected value of the target given particular categorical value and the expected value of the target over all the training data.
from category_encoders import *
train_target = train_df.copy()
te = TargetEncoder()
train_target['continent'] = te.fit_transform(train_target[['continent']], y= train_target['TARGET'])
# 인코딩된 결과 확인
display(train_target.head())
display(train_target['continent'].dtype)
display(train_target['continent'].unique())06. 전략 수립
1 ) 범주형 변수 범위 축소하기
- 통계적으로 의미있는 변수 통합하기
- kruskal willis test 등..
비모수 검정인 kruskal-willis test로 continent가
non-set인 것과 아닌 것의 TARGET값의 중앙값이 다름을 확인
continent가 non-set이면 1, 아니면 0로 mappingfrom scipy import stats notset_target = train_df[train_df['continent'] == '(not set)'][['TARGET']] nonnotset_target = train_df[train_df['continent'] != '(not set)'][['TARGET']] result = stats.kruskal(nonnotset_target, ocen_target) # KruskalResult(statistic=array([49.40623925]), pvalue=array([2.08082797e-12]))
2 ) 도메인 지식을 활용하기
예를 들어화장품 파운데이션 호수 21호, 22호, 23호가 있을 경우 어둡기 단계로 1, 2, 3으로 맵핑할 수 있음
3 ) Boosting Model 사용하기
- CatBoost, XGBoost, LGBM 모델은 Categorical 변수 처리를 지원
