
들어가는 말
- ‘변수와 자료형’에선 데이터를 컴퓨터에 저장하고, 컴퓨터는 어떤 방식으로 데이터를 처리하는지에 대해서 알아봤다.
이번 ‘연산자’ 파트에선 저장된 데이터를 갖고 원하는 결과를 얻는 방법을 알아보자.
1. 연산자
: 연산을 수행하는 기호+ - / * 와 같은 사칙연산을 위한 연산자부터, = 과 같은 다양한 연산자가 자바에 존재한다.
연산자와 피연산자
- 연산자 : 연산 수행 기호 ex) +, -, == 등
- 피연산자 : 연산의 대상 ex) 변수, 상수, 리터럴, 수식
위 수식에서 ‘+’는 2개의 피연산자 , 을 더한 결과를 반환한다. 이를 보면 연산자는 피연산자로 연산을 수행하면, 그 후 “결과값을 반환한다”는 것이다.
식(式)과 대입연산자
식 : 연산자와 피연산자의 조합으로 계산하고자 하는 걸 표현하는 것.식을 계산해서 결과를 얻는다는 걸 ‘평가’라고 한다. 그리 중요하지 않으니 그냥 넘어가도 된다.
4 * x * 3;위에서 x=5 일 경우, 23이라는 값이 평가되겠지만 반환된 결과는 사라지고 만다. 그래서 대입연산자 =를 이용해서 값을 변수에 저장해줘야, 평가된 값을 사용할 수 있다.
x = 5;
y = 4 * x * 3;연산자의 종류
- 연산자의 종류는 용도에 따라 크게 ‘산수, 비교, 논리, 대입’로 나눌 수 있다.
물론 피연산자의 수에 따라서도 나눌 수 있다는 것만 알아주자.
꽤 양이 많은 것 같지만, 쓰다보면 알게 되니 달달 외워둘 필요는 없다.
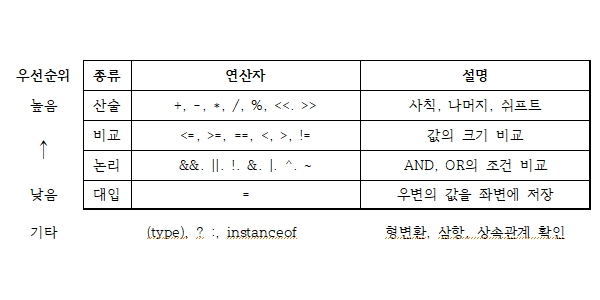
피연산자의 개수로 의한 분류
-
앞서 말했듯 연산자는 피연산자의 개수로도 분류할 수 있다.
피연산자가 1개면 단항, 2개면 이항, 3개면 삼항 연산자라고 한다. -
대부분은 이항이니 외울 필요는 없고, 삼항은 표를 보면 나오듯
? :한 개 뿐이다.
단항은=, ++, --, -등이 있는데 여기서-는 산술 연산 시에는 뺄셈 연산자이지만,
단항으로 쓰이게 된다면 음수를 나타내는 부호 연산자가 되기도 한다.
-3 - 5;연산자 우선순위와 결합규칙
- 연산자 우선 순위는 헷갈리지 않게 알아두는 것이 좋다.
이것도 작업의 순서를 결정하는 것이기 때문에 잘못 알고 있다면 결과 자체가 달라질 수 있기 때문이다.
다행인 건 대부분 기본 상식 안에서 해결되기 때문에 강박적으로 외워둘 필요는 없다.
연산자 우선순위
- 사용 방식 : 산술 > 비교 > 논리 > 대입
- 피연산자의 수 : 단항 > 이항 > 삼항
다음은 예시와 주의해서 볼 부분을 표로 나타낸 것이다.
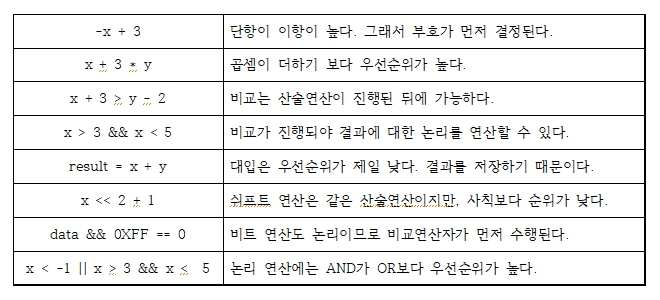
연산자 결합규칙
그렇다면 한 식 안에 같은 우선순위를 지닌 연산자가 있다면 어떻게 해야될까?
→ 결합규칙을 사용한다.
- 결합규칙은 왼쪽에서 오른쪽의 순서로 연산을 수행한다. 대부분 이렇다.
단, 단항 연산자와 대입만 그 반대(오른쪽 → 왼쪽)로 수행한다.
y = 3 + 4 – 5;
// 왼 → 오
y = 7 – 5;
y = 2;
// 오 → 왼
y = 2; // y라는 변수 안에 리터럴 2가 저장됨.산술 변환
산술변환은 이전 파트의 끝에서 설명한 ‘형변환’이다. 먼저 이항 연산자는 두 피연산자의 타입이 일치해야 연산이 가능하다. 이는 저장방식의 차이가 존재하기에 당연한 얘기이다.
- 그래서 컴파일러는 큰 타입과 작은 타입 간의 연산의 형변환을 자동으로 진행해 생략이 가능한데, 이를 산술 변환이라고 한다.
다만 이전에 설명하지 않았던 두 규칙이 존재한다.
① 서로 다른 피연산자의 타입은 보다 큰 타입으로 일치된다.
long + int → long + long → long
이는 작은 타입으로 큰 타입을 넣으면 값 손실이 일어나기 때문이다.
② 피연산자들의 타입이 int보다 작으면 int로 변환된다.
byte + short → int + int → int
작은 타입은 그 결과값이 넘쳐 오버플로우가 일어날 확률이 높다. 그래서 int로 변환된다.
추가로 연산자의 결과 역시, 피연산자의 타입을 따른다는 것을 잊지 말자.
5/2 == 2; // int / int == int
5/2.0f == 2.5; // int / float == float○ 요약
- 연산자는 결과를 반환한다.
- 산술 > 비교 > 논리 > 대입
- 대입은 제일 마지막에 수행된다.
- 단항(1) > 이항(2) > 삼항 (3). 단항 연산자의 우선순위가 이항 연산자보다 높다.
- 단항 연산자와 대입 연산자를 제외한 모든 연산의 진행 방향은 왼쪽에서 오른쪽이다.
- 산술 변환은 작은 타입은 큰 타입으로 자동 형변환된다.
- 다만 int보다 작을 경우 자동으로 int로 변환해서 연산된다.
- 연산자의 결과는 피연산자의 타입을 따른다.
2. 단항 연산자
- 단항 연산자는 우선순위가 가장 높으며, 결합규칙이 오른쪽에서 왼쪽으로 진행된다.

증감 연산자 : ++ --
-
증감 연산자는 피연산자에 저장된 값을 1씩 증가 or 감소시킨다.
정수, 실수 모두 가능하지만 상수(constant)인 경우는 불가능하다. -
보통 연산자는 평가만 할 뿐 피연산자 그 자체를 변경하지 않는다.
오직 증감 연산자와 대입 연산자만 피연산자의 값 자체를 변경시킨다.

증감연산자에서 중요한 것은 전위형인지, 후위형인지이다. 많이들 헷갈려하는 부분인데, 일단 증감 연산자가 홀로 쓰일 경우는 그닥 신경쓰지 않아도 된다.
i++;
++i;위처럼 단독을 쓰일 경우, 변수에 접근해서 값을 불러오는 ‘참조’가 홀로 되기 때문에 딱히 문제가 되지 않는다. 하지만 밑에 코드 일 경우 값이 달라진다.
int i=5, j=0;
j = i++;
System.out.println("j=i++; 실행 후, " + i +", j="+j);
i=5; // 초기화
j=0;
j = ++i;
System.out.println("j++; 실행 후, i=" + +", j="+j);결과는 첫 번째는 i=6, j=5, 두 번째는 i=6, j=6이다. 기본적으로 전위든 후위든 1씩 증가하는 건 맞지만 값이 증가하는 타이밍이 다르다.
- 전위형 : 메모리에 저장된 값을 꺼내기 전에 증가.
- 후위형 : 메모리에 저장된 값을 꺼내서 연산 후, 증가.
부호 연산자 : + -
- 산술연산에도 쓰이는
+ -는 단항으로 쓰면 부호연산자이다. 말 그대로 부호를 바꿔준다.
다만 수학공식처럼 음수에 음수부호(-)면 양수, 양수에 음수부호(-)면 음수를 반환한다.
int i = -10;
i = +i; // -10
i = - 10;
i = -i; // 10○ 요약
- 단항에는 증감과 부호연산자가 있다.
- 증감은 전위형, 후위형이 있으며 값을 참조하는 타이밍이 다르다.
- 증감을 한 식 안에 여러번 쓰는 것 좋지 않다.
- 부호 연산자는 boolean, char를 제외한 기본형에만 사용 가능하다.
3. 산술 연산자
- 산술 연산자는 사칙연산, 나머지 연산자가 있다. 말 그대로 산술 용도로 쓰는 연산자이다.
당연한 얘기니까 주의사항 중심으로 전개하자.
사칙 연산자 : + - * /
-
우선순위는 곱셈, 나눗셈이 높고 그다음으로 덧셈, 뺄셈이다.
-
정수형 나눗셈의 피연산자로 0을 집어넣으면 에러가 발생한다. 컴파일은 된다.
System.out.println(3/0); // 실행하면, 오류 (ArithmeticException)
System.out.println(3/0.0); // 지수부가 -127이라, 0출력- 나누기 연산 시, int타입인 경우 연산 결과도 int라서 소수점 이하는 버려진다. 이때 반올림은 발생하지 않는다.
10 / 4; // → 2소수점 아래값을 얻고 싶다면 float, double과 같이 연산을 해야된다. 반올림을 하고 싶다면 Math.round() 메서드를 사용하거나 로 원하는 자리에서 반올림이 되게 해야한다.
double pi- 3.141592;
double shortPi - (int) (pi * 1000 + 0.5) / 1000.0;
// double shortPi = Math.round(pi * 1000) / 1000.0
// Math.round() 메서드는 파라미터의 소수점 첫 번째 자리에서 반올림한다.- int보다 작은 값은 int형으로 변환되서 int형으로 결과를 반환한다.
byte a = 10:
byte b = 20;
byte c = a + b // 에러발생. 명시적 형변환을 해줘야됨.
byte d = 100:
byte e = 30;
byte f = (byte) d + e //저장은 되지만, 오버플로우가 발생한다.- 오버플로우가 발생한 값은 형변환을 해도, 정상값이 되진 않는다.
int a = 1_000,000; // 1,000,000
int b = 2_000_000; // 2,000,000
long c = a * b;
System.out.println(c); // -1454759936 : 오버플로우된 값이 저장됨.그래서 값이 넘을 것 같으면, 애초에 큰 타입으로 연산을 수행하는 것이 좋다.
- 사칙연산의 피연산자로 문자도 가능하다.
문자는 실제 유니코드에 따라 연속적으로 배치된 부호 없는 정수이다. 그래서 정수 간 연산이 가능하며, 동시에 연속적 배치를 활용해서 다른 값으로 변환할 수 있다.
① 문자 → 숫자 변환법
‘2’ - ‘0’ → 50 – 48 → 2따라서 문자형을 정수형으로 변환하면 되는데, 이는 유니코드의 숫자가 연속적으로 배치되어 있기에 가능하다.
② 대문자 ⟷ 소문자 변환법
char lowerCase = 'a';
char upperCase (char) (lowerCase - 32);이 역시도 유니코드의 연속적 배치를 활용한 것이다. ’a’는 97, ‘A’는 65로 두 코드의 차이는 32이다. 그래서 소문자에서 –32를 한 다음, char에 저장하면 ‘A’가 저장된다.
반대로 대문자에 +32를 하면 소문자로 변환되서 저장된다. 이를 활용해서, 대소문자를 구별할 수 있다.
- 상수, 리터럴 간의 연산은 컴파일 과정에서 컴파일러가 미리 계산한다.
char cl = 'a';
// char c2 = c1+1; // 컴파일 에러
char c2 = 'a'+1;위 코드에서 두 번째 라인은 컴파일 에러가 발생한다. 왜냐면, 변수는 컴파일러가 미리 연산을 할 수 없기 때문이다. 반대로 리터럴 간에는 이미 값이 정해져 있기 때문에 컴파일러가 컴파일 과정에서 미리 처리한다.
나머지 연산자 : %
-
나머지 연산자는 왼쪽의 값을 오른쪽으로 나누고 난 나머지 값을 결과로 반환한다.
이 역시, 나누는 수로 0은 불가능하다. -
나머지 연산을 이용해서 짝수, 홀수, 배수 검사로 활용할 수 있다.
int x = 9;
int y = 3;
z = x % y; // z = 0;
// 3으로 나눴을 때, 나머지가 0이므로 9는 3의 배수이다.
- 나누는 수로 음수도 가능하지만 부호는 무시된다. 다만 왼쪽 피연산자의 부호는 인정된다.
4. 비교 연산자
- 말 그대로 피연산자 간의 값을 비교하는데 사용되는 연산자이다. 다만 연산결과가
true, false이다. - 이 역시 이항 연산자이기에 비교하는 연산자 간 타입이 다를 경우 큰 타입으로 산술변환해서 비교한다.
대소비교 연산자 : < > <= >=
- 대소비교 연산자의 기준은 좌변의 값이다.
- boolean형을 제외한 기본형에만 사용이 가능하다.
등가비교 연산자 : == !=
-
두 연산자의 값이 같은지, 다른지 비교한다.
-
모든 자료형(기본, 참조)에 사용이 가능하다. 다만 기본형일 때는 ‘값’, 참조형일 때는 ‘주소’를 비교한다는 것만 유의하자.
-
실수형에 경우에는 저장과정에서 정밀도 차이가 발생해서, 같은 십진수라도 다를 수가 있다.
float f = 0.1f;
double d = 0.1;
double d2 = (double) f; // 이미 이진수로 변환된 걸, 큰 자료형에 넣는다고 해서 정상값이 되지 않는다.
System.out.println(f == d); // false
System.out.println(d == d2); // false
System.out.println(f == d2); // true문자열 비교
-
문자열 비교를 위해선
.equals()라는 메서드를 사용한다. -
앞서 보았듯이
==은 기본형에서는 값, 참조형에선 주소를 비교한다.
주소 역시 16진법의 형태로 저장되기 때문에 비교는 가능하다.
하지만 비교 대상이 다르기에 같은 문자열이라도false가 반환될 수 있다.
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1 == str 2); // false
System.out.println(str1.equals(str2)); // true일단 문자열은 같지만 서로 다른 객체의 주소를 변수에 저장하고 있다. 여기서 str1에는 JVM의 heap 메모리에 생성된 객체 주소가, str2는 공유풀에 있는 객체 주소가 저장된다.
따라서 equals()를 사용하면 문자열끼리만 비교가 가능하다.
(대소문자 무시 : equalslignoreCase()사용)
5. 논리 연산자
비교 연산자는 이항 연산자이다. 따라서 피연산자 두 개로 하나의 조건을 만든다.
그럼 조건이 두 개 이상일 때는 어떻게 해야할까?
→ 그럴 때 사용하는 것이 논리연산자이다.
논리 연산자 : && || !
- && : AND연산으로 피연산자 양쪽 모두 true여야만 true를 얻는다.
- || : OR연산으로 피연산자 중 한쪽만 true여도 true를 얻는다.
- ! : 부정연산자로 연산결과를 역전시킨다.
예시와 함께 보도록하자.
① x는 1보다 크고 10보다 작다.
x > 1
x < 10
⇒ 1 < x && x < 10
② x는 3의 배수 또는 5의 배수이다.
x%3 == 0
x%5 == 0
⇒ x%3 == 0 || x%5 == 0
③ x는 2의 배수 또는 3의 배수지만 6의 배수는 아니다.
x%2==0
x%3==0
x%6!=0
⇒ ( x%2==0 || x%3==0 ) && x%6!=0
위 경우 앞서 말했듯이 &&의 연산순위가 ||보다 높기 때문에 ()로 묶어줘서 연산순위를 높여줘야 한다.
④ 문자 ch는 소문자’a’-‘z’이다.
97 <= ch
ch <= 122
97 <= ch && ch <= 122
유니코드의 연속적 배치 때문에 가능한 논리식이다. 97은 소문자 a, 122는 소문자 z이다. 같은 방식으로 대문자, 숫자인지 확인하는 논리식을 표현할 수 있다.
효율적인 연산
논리연산자를 사용한 식에 대해서 컴퓨터는 효율적으로 연산을 한다.
- || (OR) : 좌측 피연산자가
true이면 우측 피연산자 평가 X - && (AND) : 좌측 피연산자가
false이면 우측 피연산자 평가 X
이는 OR의 경우 한쪽만 참이어도, true를 반환하고, AND의 경우는 한쪽만 거짓이어도 false를 반환하기 때문이다.
그래서 연산속도를 높이려면, 각 조건에 맞게 효율적인 연산이 되도록 확률이 높은 조건을 좌측에 놓는 것이 좋다.
논리 부정 연산자 : !
!부정연산자를 사용하면, 결과가 반대로 바뀌어서 반환되며 ‘~이 아니다’로 이해할 수 있다.
!true → false
!false → true
○ 요약
- 연산자에 따라 좌측 피연산자를 중심으로 효율적인 연산을 한다.
- 부정 연산자는 논리값을 반전 시킨다.
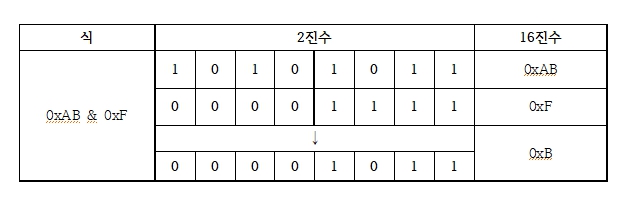
비트 연산자 : | & ^
-
비트 연산자는 말 그대로 피연산자를 비트 단위로 논리 연산한다.
주로 전가산기를 비트 연산자를 사용해서 구현하곤 한다.
이때, 비트 연산자의 피연산자는 정수(문자 포함)만 허용된다.| (OR) : 피연산자 중 한 쪽 값이 1이면 1을 얻는다. & (AND) : 양쪽 피연산자가 1일 때만 1을 얻는다. ^ (XOR) : 피연산자가 서로 다를 때만 1을 얻는다. 같으면 0
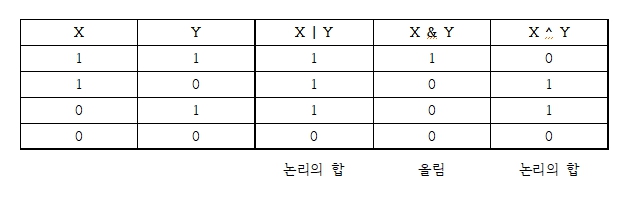
위 표를 보고 대충 어떻게 연산이 되는지는 알 수 있었다. 그럼 실제 사용을 어떤 식으로 할까?
- | : 특정 비트의 값을 변경할 때 사용.
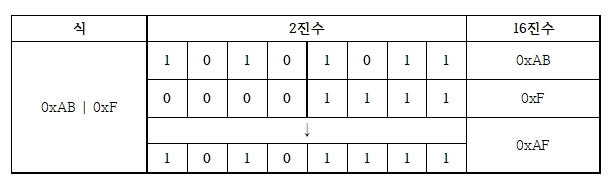
- & : 특정 비트의 값을 추출할 때 사용.
- ^ : 단순 암호화

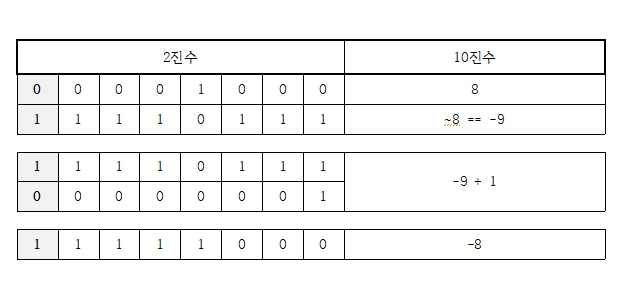
비트 전환연산자 : ~
- 논리 부정연산자처럼 비트를 반전한다.
이를 응용하여 2진수에 대한 1의 보수를 얻어낼 수 이다.
x == 1→~x == 0
쉬프트 연산자 : << >>
- 피연산자를 2진수를 표현했을 때, 오른쪽(>>), 왼쪽(<<)으로 이동시킨다.
쉬프트 연산자는 다음과 같이 동작한다.
① 10진수 6을 2진수로 바꾼다. (00000110)

② 6<<2 는 왼쪽으로 2칸 이동시킨다.

③ 범위를 넘어간 값은 버려지고(초록), 빈자리(노랑)는 0으로 채워진다.
④ 이를 다시 10진수로 바꾸면 24가 된다.
이런 점에서 쉬프트 연산자는 의 곱셈과 나눗셈으로 정리된다.
x << n: xx >> n: /
물론 십진수의 곱셈, 나눗셈과 큰 차이는 없지만 비트만 이동해서 연산이 되기 때문에 빠른 연산 속도를 요할 때 주로 사용한다.
○ 요약
- 자리올림 때문에 OR보단 XOR이 낫다.
- 비트연산에서도 피연산자의 타입 일치를 위한 ‘산술변환’이 일어날 수 있다.
- 비트연산 결과를 2진수로 출력하고 싷다면
toBinaryString()메서드를 사용하자. - 비트 전환 연산자는 피연산자의 타입이 int보다 작으면 int로 산술변환 후 연산한다.
>>는 좌측 피연산자가 음수인 경우, 빈자리를 1로 채운다. (부호)- 쉬프트 연산자는 n의 값이 자료형의 bit수보다 크면 % 로 계산한다.
6. 그 외의 연산자
조건 연산자 ? :
- 조건 연산자는 <조건식, 식1, 식2> 3개의 피연산자를 갖는 삼항 연산자이다.
조건식 ? 식1 : 식2
- 조건식의 값이 true면 (식1)을 false면 (식2)를 반환한다.
result = (x > y) ? x : y; // true → result = x;
result = (x > y) ? x : y; // false → result = y;- 조건 연산자는 중첩해서 사용이 가능하다.
x = -1;
result = (x > 0) ? 1 : ( x == 0 ? 0 : -1);
// 풀이
result = (x > 0) ? 1 : ( -1 == 0 ? 0 : -1);
result = (x > 0) ? 1 : ( false ? 0 : -1);
result = (x > 0) ? 1 : -1;
result = false ? 1 : -1;
result = -1;이처럼 연산자의 결합규칙에 따라서 오른쪽부터 왼쪽으로 실행이 된다.
다만 조건 연산자를 여러 번 중첩해서 사용하면 가독성이 떨어지기 때문에, 조건문 if로 풀어서 쓰는 게 낫다.
대입 연산자 : =
-
대입 연산자는 아마도 가장 많이 사용하게 될 연산자로 기능은 저장공간에 리터럴, 연산 결과를 저장하고, 그 값을 연산 결과로 반환한다.
-
결합 규칙에 따라서 왼쪽에서 오른쪽으로 연산되며, 좌측의 피연산자는 값을 저장할 수 있는 저장공간이어야 한다.
복합 대입 연산자
다른 연산자가 포함된 대입 연산자의 식을 축약한 형태이다. 딱히 대단한 건 아니지만 잘 모르겠다면 그냥 풀어서 쓰는게 낫다.
a += 3; // a = a + 3;
a -= 3; // a = a - 3;
a *= 3; // a = a * 3;
a <<= 3; // a = a << 3; // a * $2^3$
a &= 3; // a = a & 3;
a ^= 3; // a = a ^ 3;
a |= 3; // a = a | 3;
a *= 7+b // a = a * (7+b);○ 요약
- 삼항 연산자도 이항 연산자처럼 산술변환을 한다.
도움이 되셨다면 '좋아요' 부탁드립니다 :)
