3단계: pymssql을 사용하여 SQL에 연결하는 개념 증명
웹크롤링
웹 크롤링(Web Crawling)
웹 크롤링이란 웹상에 존재하는 정보들을 수집하는 작업을 말한다.
서블렛 급 컨트롤러 비지니스 로직을 집어 넣는다.
뷰는 JSP
모델 >> 파이프 라인
파이썬으로 고니시와 아벤의 정보를 빼오는 것이 과제
request , beautifulsoup, bs4? 가 필요하다
아나콘다에서
conda install request beautifulsoup bs4
(명령안되면 pip명령)으로 설치한다.
import requests
from bs4 import BeautifulSoup
def crawler():
url = 'https://www.google.com'
html = requests.get(url)
print(html.text)
crawler()하면 나온다. !
참고 : https://medium.com/@hckcksrl/python-crawling-%ED%81%AC%EB%A1%A4%EB%A7%81-94fe210af0a2
- HTTP Client : Requests (내부 라이브러리 urllib 제공하나 requsets 문법이 간결함)
- HTML / XML Parser : BeautifulSoup4
사이트 웹 스크래핑
import requests
from bs4 import BeautifulSoup
URL = 'http://localhost/HELLOWEB/myservlet'
response = requests.get(URL)
print(response.status_code)
print(response.text)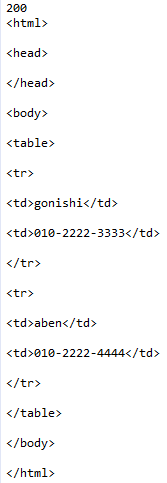
사이트 스크래핑 2
태그안 내용 값 스크래핑
post로 바꿈 서버단에서도 확인
이름과 번호 가져오기
import requests
from bs4 import BeautifulSoup
params = {'myname' : '김구', 'myphone' : '01044558888'}
URL = 'http://localhost/HELLOWEB/myservlet'
response = requests.post(URL,params=params)
# print(response.status_code)
# print(response.text)
soup = BeautifulSoup(response.text, 'html.parser')
my_tr = soup.select('tr')
token = True
for tr in my_tr:
tds = tr.select("td")
print(tds[0].text, tds[1].text)

참고 : https://m.blog.naver.com/kiddwannabe/221177292446 select사용법
네이버 영화 검색 스크래핑
import os
import sys
import urllib.request
import requests
from bs4 import BeautifulSoup
# client_id = "YOUR_CLIENT_ID"
# client_secret = "YOUR_CLIENT_SECRET"
client_id = "B3J4PHDBs2G50rxwkSGW"
client_secret = "OXKxvLOk0O"
# encText = urllib.parse.quote("검색할 단어")
encText = urllib.parse.quote("공유")
# url = "https://openapi.naver.com/v1/search/movie?query=" + encText # json 결과
url = "https://openapi.naver.com/v1/search/movie.xml?query=" + encText # xml 결과
# url += "display="
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
print()
else:
print("Error Code:" + rescode)카카오 이미지 검색 스크래핑
참고 : https://oopaque.tistory.com/120
import os
import sys
import urllib.request
import requests
from bs4 import BeautifulSoup
KakaoAK = "9e715e874101494bca17388e6e9c9acd"
encText = urllib.parse.quote("김새론")
url = "https://dapi.kakao.com/v2/search/image?query=" + encText
# header = {'Authorization : 'Ka}
request = urllib.request.Request(url)
# request.add_header("Authorization",'KaKaoAK '+ KakaoAK)
request.add_header("Authorization",'KakaoAK 9e715e874101494bca17388e6e9c9acd')
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)숙제
카카오 성공
네이버 영화 DB에 넣기
테이블명은 MOVIE로
네이버 MOVIE 검색 데이터 XML 파싱하기
외장모듈 이용 : conda install xmltodict
# conda install xmltodict # 안되면 pip명령으로 한다.

끄적끄적 쓰는곳