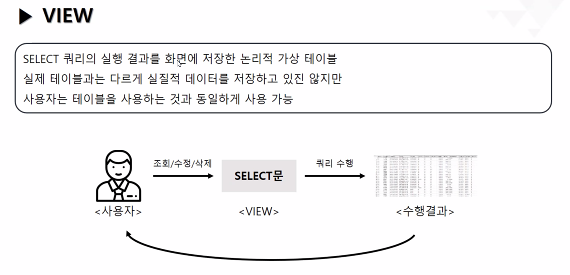
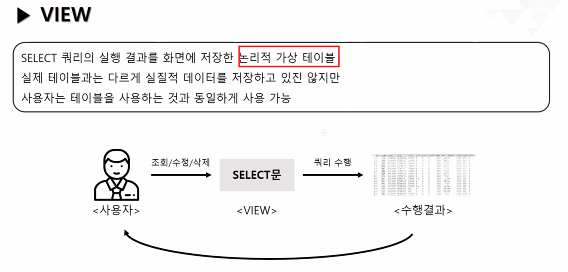
테이블과 똑같이 사용할 수 있지만 DB에 데이터가 저장되지 않는 거라고 보면 됨
테이블과는 다르게 데이터 덮어쓰기가 가능
VIEW:
SELECT문을 저장해둘 수 있는 객체
(자주 쓰는 긴 SELECT문을 저장해두면 매번 기술할 필요 없음)
임시테이블 같은 존재(실제 데이터가 담겨있지 않음 => 논리적 테이블)
[표현식]
CEATE VIEW 뷰명
AS 서브쿼리;
--한국에서 근무하는 사원들의 사번, 이름, 부서명, 급여, 근무국가명 조회
SELECT EMP_ID, EMP_NAME, DEPT_TITLE, SALARY, NATIONAL_NAME
FROM EMPLOYEE
JOIN DEPARTMENT ON (DEPT_ID = DEPT_CODE)
JOIN LOCATION ON (LOCATION_ID = LOCAL_CODE)
JOIN NATIONAL USING (NATIONAL_CODE)
WHERE NATIONAL_NAME = '한국';
--이걸 국가마다 반복해야된다면 VIEW를 사용---------------
CREATE VIEW VW_EMP
AS SELECT EMP_ID, EMP_NAME, DEPT_TITLE, SALARY, NATIONAL_NAME
FROM EMPLOYEE
JOIN DEPARTMENT ON (DEPT_ID = DEPT_CODE)
JOIN LOCATION ON (LOCATION_ID = LOCAL_CODE)
JOIN NATIONAL USING (NATIONAL_CODE);
--한국, 러시아, 중국
SELECT *
FROM VW_EMP
WHERE NATIONAL_NAME IN ('한국' ,'중국' ,'러시아');
--사용자가 원하는 컬럼만 조회
SELECT EMP_NAME, NATIONAL_NAME
FROM VW_EMP
WHERE NATIONAL_NAME IN ('한국' ,'중국' ,'러시아');
--사용자가 갖고 있는 모든 뷰 보기
SELECT * FROM USER_VIEWS;뷰 컬럼에 별칭 부여:
서브쿼리의 SELECT절에 함수식이나 산술연산이 있을 경우 반드시 별칭 지정
VIEW는 기존의 동명의 VIEW가 존재할 경우 덮어쓸 수 있음
CREATE OR REPLACE VIEW 뷰명
-- 모든 사원의 사번, 이름, 직급명, 성별(남/여), 근무년수를 조회하여 VIEW(VW_EMP_JOB)생성
CREATE OR REPLACE VIEW VW_EMP_JOB
AS SELECT EMP_ID
, EMP_NAME
, JOB_NAME
, DECODE(SUBSTR(EMP_NO,8,1),'1','남','2','여') 성별
, EXTRACT(YEAR FROM SYSDATE) - EXTRACT(YEAR FROM HIRE_DATE) 근무년수
FROM EMPLOYEE
JOIN JOB USING (JOB_CODE);
SELECT * FROM VW_EMP_JOB;
-- 아래와 같은 방식으로도 별칭 부여 가능
CREATE OR REPLACE VIEW VW_EMP_JOB(사번, 이름, 직급명, 성별, 근무년수) --조회할 컬럼 개수와 동일해야 됨
AS SELECT EMP_ID
, EMP_NAME
, JOB_NAME
, DECODE(SUBSTR(EMP_NO,8,1),'1','남','2','여')
, EXTRACT(YEAR FROM SYSDATE) - EXTRACT(YEAR FROM HIRE_DATE)
FROM EMPLOYEE
JOIN JOB USING (JOB_CODE);
--성별이 여자인 사람만
SELECT 이름, 직급명, 성별 --컬럼명 설정한대로 넣어줘야됨
FROM VW_EMP_JOB
WHERE 성별 = '여';
--근무년수가 20년 이상인 사람
SELECT *
FROM VW_EMP_JOB
WHERE 근무년수 >= 20;
--VIEW 삭제
DROP VIEW VW_EMP_JOB;생성된 뷰를 이용하여 DML(INSERT, UPDATE, DELETE) 사용 가능:
-뷰를 통해서 조작하면 실제 데이터가 담겨있는 테이블에 반영됨
CREATE OR REPLACE VIEW VW_JOB
AS SELECT *
FROM JOB;
--VIEW를 통한 INSERT
INSERT INTO VW_JOB VALUES('J8','인턴');
--VIEW를 통한 UPDATE
UPDATE VW_JOB
SET JOB_NAME = '알바'
WHERE JOB_CODE = 'J8';
--VIEW를 통한 DELETE
DELETE FROM VW_JOB WHERE JOB_CODE = 'J8';- 단, DML 명령어로 조작이 불가능한 경우가 더 많음
1) 뷰에 정의되어 있지 않은 컬럼을 조작하려고 할 때
2) 뷰에 정의되어 있지 않은 컬럼이더라도 원본 테이블 상에 NOT, NULL 제약조건이 있을 때
3) 산술연산식, 함수식으로 정의되어 있을 때
4) 그룹함수나 GROUP BY절이 포함된 경우
5) DISTINCT 구문이 포함되어 있는 경우
6) JOIN을 이용하여 여러 테이블을 연결시켜놓은 경우
-- 1) 뷰에 정의되어있지 않은 컬럼을 조작할 때
CREATE OR REPLACE VIEW VW_JOB
AS SELECT JOB_CODE
FROM JOB;
-- INSERT,UPDATE, DELETE (컬럼이 없어서 모두 오류)
INSERT INTO VW_JOB(JOB_CODE, JOB_NAME) VALUES('J8','인턴');
UPDATE VW_JOB
SET JOB_NAME = '인턴'
WHERE JOB_CODE = 'J7';
DELETE
FROM VW_JOB
WHERE JOB_NAME = '사원';
--2) 뷰에 정의되어 있지 않은 컬럼이더라도 원본 테이블 상에 NOT, NULL 제약조건이 있을 때
CREATE OR REPLACE VIEW VW_JOB
AS SELECT JOB_NAME
FROM JOB;
-- INSERT 오류
INSERT INTO VW_JOB VALUES('인턴');
--원본 테이블에도 데이터가 추가 되어야하는데 이름만 들어가고 JOB_CODE(기본키: NOT NULL이어야함)는 NULL이어서 오류
--UPDATE 가능
UPDATE VW_JOB
SET JOB_NAME = '알바'
WHERE JOB_NAME = '사원';
ROLLBACK;
--DELETE(외래키로 제약조건이 있으면 자식테이블이 쓰고 있는 값은 삭제 불가)
DELETE
FROM VW_JOB
WHERE JOB_NAME = '사원';--(외래키가 걸려있고 자식에서 쓰는 데이터라 삭제 불가)
DELETE
FROM VW_JOB
WHERE JOB_NAME = '대표'; --자식테이블에서 안 쓰고 있는 데이터면 삭제 가능
ROLLBACK;
--3) 산술연산식, 함수식으로 정의되어 있을 때
CREATE OR REPLACE VIEW VW_EMP_SAL
AS SELECT EMP_ID, EMP_NAME, SALARY, SALARY*12 연봉
FROM EMPLOYEE;
--INSERT 오류
INSERT INTO VW_EMP_SAL VALUES(400, '김상진', 3000000, 36000000);
--원본 테이블에는 연봉 컬럼이 없어서 오류
-- UPDATE 오류(이유는 위와 같음)
UPDATE VW_EMP_SAL
SET 연봉 = 80000000
WHERE EMP_ID = 200;
--UPDATE(존재하는 컬럼 수정은 가능)
UPDATE VW_EMP_SAL
SET SALARY = 5000000
WHERE EMP_ID = 211;
-- DELETE(행 전체를 삭제하기 때문에 컬럼유무 제약 없음)
DELETE
FROM VW_EMP_SAL
WHERE 연봉 = 44400000;
ROLLBACK;
-- 4) 그룹함수나 GROUP BY절이 포함된 경우
CREATE OR REPLACE VIEW VW_GROUPEMP
AS SELECT DEPT_CODE, SUM(SALARY) 합계, CEIL(AVG(SALARY)) 평균
FROM EMPLOYEE
GROUP BY DEPT_CODE;
--INSERT, UPDATE 오류(합계, 평균 컬럼 없어서)
INSERT INTO VW_GROUPEMP VALUES('D3',80000000,7500000);
UPDATE VW_GROUPEMP
SET 합계 = 8000000
WHERE DEPT_CODE = 'D1';
--DELETE 오류(그룹으로 되어있어서 낱개가 아니기 때문에)
DELETE
FROM VW_GROUPEMP
WHERE 합계 = 3500000;
-- 5) DISTINCT 구문이 포함되어 있는 경우
CREATE OR REPLACE VIEW VW_DT_JOB
AS SELECT DISTINCT JOB_CODE
FROM EMPLOYEE;
-- INSERT, UPDATE, DELETE 오류
INSERT INTO VW_DT_JOB VALUES('J8');
UPDATE VW_DT_JOB
SET JOB_CODE = 'J8'
WHERE JOB_CODE = 'J7';
DELETE FROM VW_DT_JOB WHERE JOB_CODE = 'J3';
--6) JOIN을 이용하여 여러 테이블을 연결시켜놓은 경우
CREATE OR REPLACE VIEW VW_JOIN
AS SELECT EMP_ID, EMP_NAME, DEPT_TITLE
FROM EMPLOYEE, DEPARTMENT
WHERE DEPT_CODE = DEPT_ID;
--INSERT 오류(두 원본 테이블을 동시에 수정 불가)
INSERT INTO VW_JOIN VALUES(300, '황미해', '총무부');
--UPDATE 가능
UPDATE VW_JOIN
SET EMP_NAME = '김새로'
WHERE EMP_ID = 200;
--UPDATE 가능 그러나 D9는 마케팅부라 총무부로 바뀌면 안 됨
UPDATE VW_JOIN
SET DEPT_TITLE = '총무부'
WHERE EMP_ID = 200;
ROLLBACK;VIEW옵션:
[상세표현식]
CREATE [OR REPLACE][FORCE | NOFORCE] VIEW 뷰명
AS 서브쿼리
[WITH CHECK OPTION][WITH READ ONLY];
1) OR REPLACE : 기존에 동일한 뷰가 있을 경우 갱신시키고, 존재하지 않으면 새로 생성
2) FORCE | NOFORCE
> FORCE: 서브쿼리에 기술된 테이블이 존재하지 않아도 뷰가 생성되게 함
> NOFORCE: 서브쿼리에 기술된 테이블이 존재하는 테이블이어야만 뷰가 생성됨(생략시 기본값)
3) WITH CHECK OPTION: DML시 서브쿼리에 기술된 조건에 부합한 값으로만 DML가능하도록 함
4) WITH READ ONLY: 뷰에 대해 조회만 가능(DML문 수행 불가)--2) FORCE | NOFORCE
-- >> NOFORCE(기본값)
CREATE OR REPLACE /*NOFORCE*/ VIEW VM_EMP
AS SELECT NCODE, NNAME, MCONTENT
FROM NN; --테이블 또는 뷰가 존재하지 않는다는 오류남
-- >> FORCE
CREATE OR REPLACE FORCE VIEW VW_EMP
AS SELECT NCODE, NNAME, MCONTENT
FROM NN; -- 오류가 났지만 뷰가 생성됨
-- NN테이블을 생성해야만 그 때부터 뷰 활용 가능
CREATE TABLE NN(
NCODE NUMBER
, NNAME VARCHAR2(20)
, MCONTENT VARCHAR2(50)
);
SELECT * FROM VW_EMP;
-- 3) WITH CHECK OPTION
--WITH CHECK OPTION 안 쓰고
CREATE OR REPLACE VIEW VW_EMP
AS SELECT *
FROM EMPLOYEE
WHERE SALARY >= 30000000; --맞는 값이 없기 때문에 ↓
-- 200번 사원의 급여를 2000000으로 변경
UPDATE VW_EMP
SET SALARY = 20000000
WHERE EMP_ID = 200; -- 가상 테이블에서 아예 안 보임
-- 9명 -> 8명으로 VIEW의 행이 변경됨
ROLLBACK;
--WITH CHECK OPTION을 쓰고
CREATE OR REPLACE VIEW VW_EMP
AS SELECT *
FROM EMPLOYEE
WHERE SALARY >= 3000000
WITH CHECK OPTION;
-- 200번 사원의 급여를 2000000으로 변경
UPDATE VW_EMP
SET SALARY = 2000000 --4000000은 가능
WHERE EMP_ID = 200;
--오류: 서브쿼리에 기술한 조건에 부합하지 않기 때문에 변경 불가
--4) WITH READ ONLY
CREATE OR REPLACE VIEW VW_EMP
AS SELECT EMP_ID, EMP_NAME, BONUS
FROM EMPLOYEE
WHERE BONUS IS NOT NULL
WITH READ ONLY;
-- INSERT, UPDATE, DELETE 모두 오류
DELETE FROM VW_EMP WHERE EMP_ID = 200;SEQUENCE:
자동으로 번호 발생시켜주는 역할을 하는 객체
점수값을 순차적으로 일정값씩 증가시키면서 생성해줌
EX) 회원번호, 사원번호, 게시글번호(답글과 순서가 안 맞아서 잘 안씀), ...

이런식으로 밑에 사용자에게 보여줄 때는 순서가 바뀐채로 보임 그래서 게시글 번호를 시퀀스로 잘 안 씀
시퀀스 객체 생성:
[표현식]
- CREATE SEQUENCE 시퀀스명
- [START WITH 시작숫자] --> 처음 발생시킬 시작값 지정(기본값 1)
- [INCREMENT BY 숫자] --> 몇씩 증가시킬 건지(기본값 1)
- [MAXVALUE 숫자] --> 최대값 지정 (기본값 큼), 최대값 지정되지 않는 이상 잘 안씀
- [MINVALUE 숫자] --> 최소값 지정 (기존값 1), 기본값인 1보다 작은 값을 넣을 수 없음
- [CYCLE | NOCYCLE] --> 값 순환 여부 지정 (기본값 NOCYCLE)
- [NOCACHE | CASHE] --> 캐시 메모리 할당(기본값 CACHE 20)
* 캐시메모리: 미리 발생될 값들을 생성해서 저장해두는 공간
매번 호출될 때마다 새롭게 번호를 생성하는 것이 아니라
캐시메모리 공간에 미리 생성된 값들을 가져다 쓸 수 있음(속도 향상)
접속이 해제되면 캐시메모리에 미리 만들어둔 값들은 사라짐
요즘은 하드웨어 성능이 좋아서 다 빠름 그래서 잘 안 쓰긴 함

네모 박스 안에 있는 것들을 주로 많이 씀
CREATE SEQUENCE SEQ_TEST;하면 이렇게 나옴
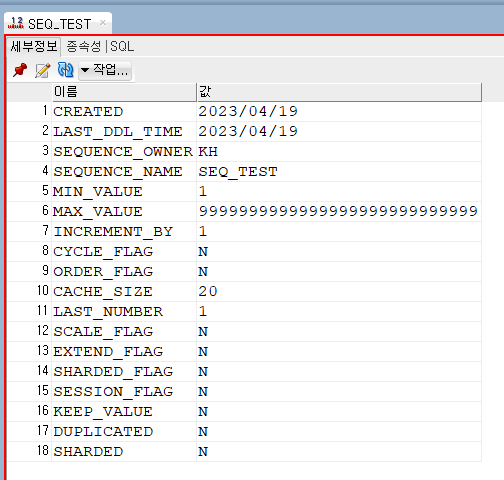
시퀀스 사용:
시퀀스명.CURRVAL: 현재 시퀀스의 값(마지막으로 성공한 NEXTVAL의 값)
시퀀스명.NEXTVAL: 시퀀스값에 일정값을 증가시켜서 발생된 값
현재 시퀀스 값에서 INCREMENT BY값 만큼 증가된 값
== 시퀀스명.CURRVAL + INCREMENT BY값
SELECT SEQ_EMPNO.NEXTVAL FROM DUAL;
SELECT SEQ_EMPNO.CURRVAL FROM DUAL; -- 300을 사용했기 때문에 300
SELECT SEQ_EMPNO.NEXTVAL FROM DUAL; -- 300에 5(INCREMANT값)를 더하여 305
SELECT SEQ_EMPNO.NEXTVAL FROM DUAL; -- 305에 5 더하여 310(MAXVALUE)
SELECT SEQ_EMPNO.NEXTVAL FROM DUAL; -- MAXVALUE 초과하여 사용 불가
SELECT SEQ_EMPNO.CURRVAL FROM DUAL; -- 310
CREATE SEQUENCE SEQ_EMPNO2
START WITH 300
INCREMENT BY 5
MAXVALUE 310
CYCLE
NOCACHE;
SELECT SEQ_EMPNO2.NEXTVAL FROM DUAL; --300
SELECT SEQ_EMPNO2.NEXTVAL FROM DUAL;
SELECT SEQ_EMPNO2.NEXTVAL FROM DUAL; --310
SELECT SEQ_EMPNO2.NEXTVAL FROM DUAL; -- 다시 순환하여 MINVALUE인 1로 돌아옴
SELECT SEQ_EMPNO2.NEXTVAL FROM DUAL; -- 5 더해서 6
--MINVALUE 추가
CREATE SEQUENCE SEQ_EMPNO3
START WITH 300
INCREMENT BY 5
MINVALUE 300
MAXVALUE 310
CYCLE
NOCACHE;
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --300
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --305
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --310
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --MINVALUE값인 300으로 순환
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --305
SELECT SEQ_EMPNO3.NEXTVAL FROM DUAL; --310시퀀스 구조 변경:
ALTER SEQUENCE 시퀀스명
- [INCREMENT BY 숫자] --> 몇씩 증가시킬 건지(기본값 1)
- [MAXVALUE 숫자] --> 최대값 지정 (기본값 큼), 최대값 지정되지 않는 이상 잘 안씀
- [MINVALUE 숫자] --> 최소값 지정 (기존값 1), 기본값인 1보다 작은 값을 넣을 수 없음
- [CYCLE | NOCYCLE] --> 값 순환 여부 지정 (기본값 NOCYCLE)
- [NOCACHE | CASHE] --> 캐시 메모리 할당(기본값 CACHE 20)
ALTER SEQUENCE SEQ_EMPNO
INCREMENT BY 10 --10씩 증가하니까 310에서 320으로 LAST_NUMBER
MAXVALUE 400;
SELECT SEQ_EMPNO.NEXTVAL FROM DUAL; -- 310 + 10 = 320시퀀스 삭제:
DROP SEQUENCE SEQ_EMPNO;--사원번호로 활용할 시퀀스 생성
CREATE SEQUENCE SEQ_EID
START WITH 300;
INSERT INTO EMPLOYEE(EMP_ID, EMP_NAME, EMP_NO, JOB_CODE, HIRE_DATE)
VALUES(SEQ_EID.NEXTVAL, '차은우', '200312-3123456', 'J5', SYSDATE);
--EMP_ID = 300
INSERT INTO EMPLOYEE(EMP_ID, EMP_NAME, EMP_NO, JOB_CODE, HIRE_DATE)
VALUES(SEQ_EID.NEXTVAL, '최정훈', '211123-3234567', 'J3', '21/03/12');
-- EMP_ID = 301로 자동으로 카운트해서 들어감PL/SQL(PROCEDURAL LANGUAGE EXTENSION TO SQL):
-오라클 자체에 내장돼 있는 절차적언어(순서대로 수행)
-SQL문장 내에서 변수의 정의, 조건처리(IF), 반복처리(LOOP, FOR, WHILE) 등을 지원하여 SQL의 단점 보완
-다수의 SQL문을 한 번에 실행 가능(BLOCK구조)
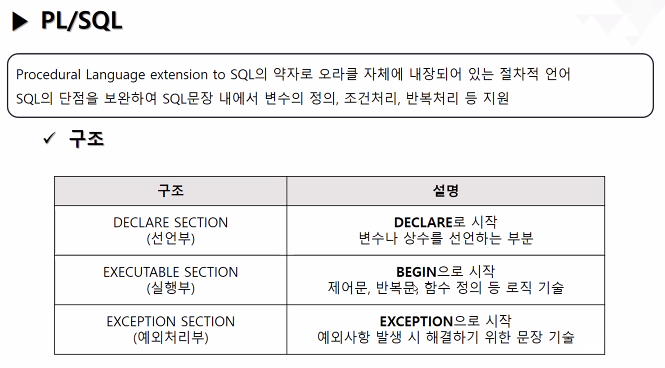
PL/SQL 구조
-[선언부 (DECLARE SECTION)]: DECLARE로 시작, 변수나 상수를 선언 및 초기화하는 부분
-[실행부 (EXECUTABLE SECTION): BEGIN으로 시작, SQL문 또는 제어문(조건문,반복문)등의 로직을 기술하는 부분
-[예외처리부 (EXCEPTION SECTION)]: EXCEPTION으로 시작, 예외 발생시 해결하기 위한 구문을 미리 기술하는 부분
-- 화면에 HELLO ORACLE출력
SET SERVEROUTPUT ON;
--서버의 OUTPUT이 꺼져있기 때문에 스크립트에 보이지 않음. 그래서 ON으로 켜줘야 함
BEGIN
DBMS_OUTPUT.PUT_LINE('HELLO ORACLE');
END;
/ 
BEGIN부터 시작, ;가 구문 끝 /가 블럭 끝
END; 와 / 옆에 주석 넣으면 오류 발생함!!

1. DECLARE 선언부:
변수 및 상수 선언하는 공간(선언과 동시에 초기화도 가능)
일반타입 변수, 레퍼런스타입 변수, ROW타입 변수
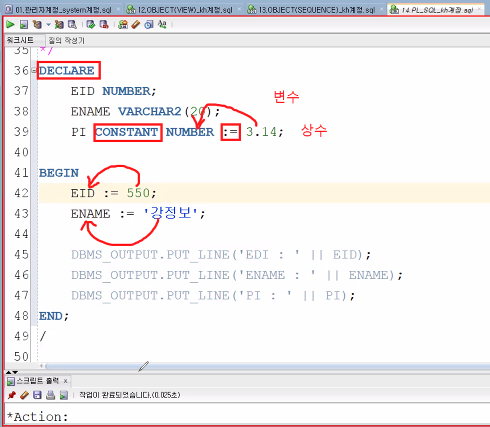
1.1 일반타입 변수 선언 및 초기화:
[표현식]
변수명 [CONSTANT(상수)] 자료형 [:=값];
1.2 레퍼런스 타입 변수 선언 및 초기화:
어떤 테이블의 어떤 컬럼의 데이터타입을 참조하여 그 타입으로 지정
[표현식]
변수명 테이블명. 컬럼명%TYPE;
DECLARE
EID EMPLOYEE.EMP_ID%TYPE;
ENAME EMPLOYEE.EMP_NAME%TYPE;
SAL EMPLOYEE.SALARY%TYPE;
BEGIN
EID := '300';
ENAME := '유재석';
SAL := 3400000;
DBMS_OUTPUT.PUT_LINE('EID: ' || EID);
DBMS_OUTPUT.PUT_LINE('ENAME: ' || ENAME);
DBMS_OUTPUT.PUT_LINE('SALARY: ' || SAL);
END;
/
DECLARE
EID EMPLOYEE.EMP_ID%TYPE;
ENAME EMPLOYEE.EMP_NAME%TYPE;
SAL EMPLOYEE.SALARY%TYPE;
BEGIN
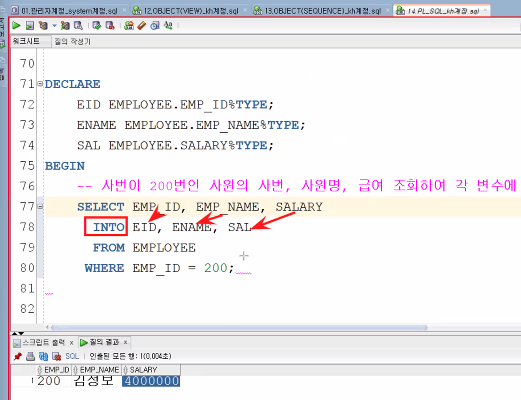
--사번이 200번인 사원의 사번, 사원명, 급여 조회하여 각 변수에 대입
SELECT EMP_ID, EMP_NAME, SALARY
INTO EID, ENAME, SAL
FROM EMPLOYEE
WHERE EMP_ID = &사번;
-- 사용자가 입력하여 원하는 것만 조회할 때 대화창 & 사용, "사번"운 대화창 제목에 출력되는 글씨
DBMS_OUTPUT.PUT_LINE('EID: ' || EID);
DBMS_OUTPUT.PUT_LINE('ENAME: ' || ENAME);
DBMS_OUTPUT.PUT_LINE('SALARY: ' || SAL);
END;
/
*실습문제*
레퍼런스타입 변수로 EID, ENAME, JCODE, SAL, DTITLE을 선언하고 각 자료형을 참조하여 자료형 정의
사용자가 입력한 사번의 사번, 이름, 직급코드, 급여, 부서명을 각 변수에 저장하여 출력
DECLARE
EID EMPLOYEE.EMP_ID%TYPE;
ENAME EMPLOYEE.EMP_NAME%TYPE;
JCODE EMPLOYEE.JOB_CODE%TYPE;
SAL EMPLOYEE.SALARY%TYPE;
DTITLE DEPARTMENT.DEPT_TITLE%TYPE;
BEGIN
SELECT EMP_ID, EMP_NAME, JOB_CODE, SALARY, DEPT_TITLE
INTO EID, ENAME, JCODE, SAL, DTITLE
FROM EMPLOYEE
JOIN DEPARTMENT ON (DEPT_CODE = DEPT_ID)
WHERE EMP_ID = &사번;
--DBMS_OUTPUT.PUT_LINE(EID || ',' || ENAME || ',' || ... );
DBMS_OUTPUT.PUT_LINE('EID: ' || EID);
DBMS_OUTPUT.PUT_LINE('ENAME: ' || ENAME);
DBMS_OUTPUT.PUT_LINE('JCODE: ' || JCODE);
DBMS_OUTPUT.PUT_LINE('SALARY: ' || SAL);
DBMS_OUTPUT.PUT_LINE('DTITLE: ' || DTITLE);
END;
/1.3 ROW타입 변수:
테이블의 한 행에 대한 모든 컬럼값을 한꺼번에 담을 수 있는 변수
[표현식]
변수명 테이블명%ROWTYPE;
DECLARE
E EMPLOYEE%ROWTYPE;
BEGIN
SELECT *
INTO E --한 행 자체를 이 변수에 넣음
FROM EMPLOYEE
WHERE EMP_ID = &사번;
DBMS_OUTPUT.PUT_LINE(E.EMP_NAME); -- 컬럼명을 지정해줘야됨
DBMS_OUTPUT.PUT_LINE('급여: ' || E.SALARY);
--DBMS_OUTPUT.PUT_LINE('보너스: ' || NVL(E.BONUS, '없음')); 오류: NVL이 NUMBER인데 '없음'문자형을 넣음
DBMS_OUTPUT.PUT_LINE('보너스: ' || NVL(E.BONUS,0));
END;
/
DECLARE
E EMPLOYEE%ROWTYPE;
BEGIN
SELECT EMP_NAME, SALARY, BONUS
--오류: SELECT한 컬럼의 수와 변수의 개수가 맞아야 되므로 무조건 *를 사용해야됨.
INTO E
FROM EMPLOYEE
WHERE EMP_ID = &사번;
DBMS_OUTPUT.PUT_LINE(E.EMP_NAME);
DBMS_OUTPUT.PUT_LINE('급여: ' || E.SALARY);
DBMS_OUTPUT.PUT_LINE('보너스: ' || NVL(E.BONUS,0));
END;
/