GROUP BY:
그룹기준을 제시할 수 있는 구문(해당 구문 기준별로 여러 그룹으로 묶을 수 있음)
여러개의 값들을 하나의 그룹으로 묶어서 처리
부서별 총 급여의 합 조회
SELECT DEPT_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE;
--그룹별로 묶었기 때문에 이름(EMP_NAME)을 조회하면 그룹 안에 여러명이라 오류급별 총사원수, 보너스를 받는 사원수, 급여합, 평균급여, 최저급여, 최고급여
SELECT JOB_CODE 직급, COUNT(*)사원수, COUNT(BONUS)"보너스를 받는 사원수", SUM(SALARY)급여합
, ROUND(AVG(SALARY),2)평균급여, MIN(SALARY)최소급여, MAX(SALARY)최대급여
FROM EMPLOYEE
GROUP BY JOB_CODE
ORDER BY 1; --컬럼의 몇번째인지 써줘도 정렬 가능성별 사원 수
SELECT DECODE(SUBSTR(EMP_NO,8,1),'1','남','2','여','3','남','4','여')성별, COUNT(*)||'명' AS 인원수
FROM EMPLOYEE
GROUP BY SUBSTR(EMP_NO,8,1);GROUP BY절에 여러 컬럼 기술 가능
SELECT DEPT_CODE, JOB_CODE, COUNT(*), SUM(SALARY)
FROM EMPLOYEE
GROUP BY DEPT_CODE, JOB_CODE
ORDER BY DEPT_CODE;HAVING절:
그룹에 대한 조건을 제시할 때 사용되는 구문(주로 그룹함수를 가지고 조건 제시)
-GROUP BY절에서는 WHERE 사용 불가
*실습문제*
1. 직급별 총 급여합(단, 직급별 급여합이 1000만원 이상인 직급만 조회)
SELECT JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY JOB_CODE
HAVING SUM(SALARY) >= 10000000;2. 부서별 보너스를 받는 사원이 없는 부서만 조회....어렵다...
SELECT DEPT_CODE
FROM EMPLOYEE
GROUP BY DEPT_CODE
HAVING COUNT(BONUS)= 0;집계함수 CUBE(),ROLLUP():
그룹별 산출된 결과 값에 중간집계를 계산해주는 함수
--ROUP BY 절에 기술하는 함수
--ROLLUP(컬럼1, 컬럼2): 컬럼1을 기준으로 다시 중간집계를 내는 함수
--CUBE(컬럼1, 컬럼2): 컬럼1을 기준으로 중간집계 후 컬럼2를 기준으로도 중간집계
컬럼이 하나일 때는 중간집계가 곧 SUM
SELECT JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY CUBE(JOB_CODE)
ORDER BY 1;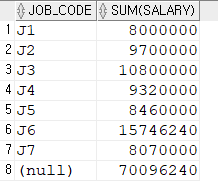
컬럼이 2개일 때
SELECT DEPT_CODE, JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY ROLLUP(DEPT_CODE, JOB_CODE)
ORDER BY 1;
SELECT DEPT_CODE, JOB_CODE, SUM(SALARY)
FROM EMPLOYEE
GROUP BY CUBE(DEPT_CODE, JOB_CODE)
ORDER BY 1;CUBE함수 결과에서
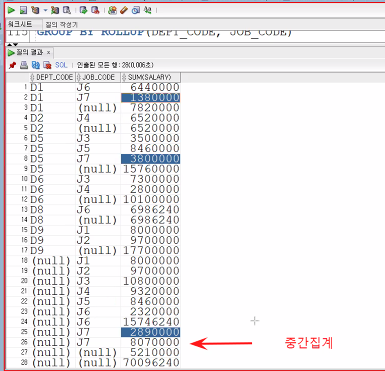
J7인 것만 골라 합해서 중간집계 냄
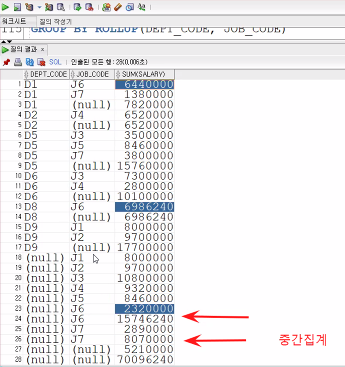
J6인 것만 골라 합해서 중간집계 냄
집합연산자(SET OPERATION):
여러개의 쿼리문을 가지고 하나의 쿼리문으로 만드는 연산자
- UNION : OR | 합집합(두 쿼리문을 수행한 결과를 더하고 중복된 값 한 번만 더함)
- INTERSECT: AND | 교집합(두 쿼리문을 수행한 결과값 중 중복된 결과값 반환)
위 둘은 OR와 AND가 더 간단해서 잘 사용 안 함 - UNION ALL : 합집합+교집합(중복되는 부분은 두 번 표현될 수 있음)
- MINUS: 차집합(선행결과값에서 후행 결과값을 뺀 나머지
- UNION : OR , 합집합
부서코드가 D5인 사원 또는 급여가 300만원 초과인 사원들 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000
ORDER BY EMP_ID;OR절이 더 간단
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5' OR SALARY > 3000000;- INTERSECT : AND , 교집합
부서코드가 D5이면서 급여가 300만원 초과인 사원들 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
INTERSECT
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;AND절이 더 간단
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5' AND SALARY > 3000000;- UNION ALL : 합집합+교집합
부서코드가 D5인 사원이거나 급여가 300만원 초과인 사원들 모두 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
UNION ALL
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;- MINUS : 차집합
부서코드가 D5인 사원중에서 급여가 300만원 초과인 사원들 제외하고 조회
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5'
MINUS
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE SALARY > 3000000;간단한 연산식으로도 가능
SELECT EMP_ID, EMP_NAME, DEPT_CODE, SALARY
FROM EMPLOYEE
WHERE DEPT_CODE = 'D5' AND SALARY <= 3000000;JOIN:
두개 이상의 테이블에서 데이터를 조회하고자 할 때 사용되는 구문
조회 결과는 하나의 결과물(RESULT SET)로 나옴
관계형 데이터베이스는 최소한의 데이터로 각각 테이블에 담겨 있음
(중복을 최소화하기 위해 최대한 쪼개서 관리)
=> 관계형 데이터베이스에서 SQL문을 이용한 테이블간 "관계"를 맺는 방법
JOIN은 크게 "오라클전용구문"과 "ANSI구문" (ANSI: 미국국립표준협회)
\[JOIN 용어 정리\]
오라클 전용 구문 | ANSI 구문 등가조인 | 내부조인(INNER JOIN) => JOIN USING / ON
(EQUAL JOIN) | 자연조인(NATURAL JOIN) => JOIN USING 포괄조인 | 왼쪽 외부조인(LEFT OUTER JOIN)
(LEFT OUTER) | 오른쪽 외부조인(RIGHT OUTER JOIN)
(RIGHT OUTER | 전체 외부조인(FULL OUTER JOIN) 자체조인(SELF JOIN) | JOIN ON
비등가 조인(NON EQUAL JOIN) | 카테시안 곱(CATESIAN PRODUCT) | 교차조인(CROSS JOON)1. 등가조인(EQUAL JOIN / 내부조인(INNER JOIN):
연결시키는 컬럼값이 "일치하는 행들만" 조인되어 조회(=일치하는 값이 없는 행은 조회 제외)
오라클 전용 구문
FROM절에 조회하고자하는 테이블을 나열(,구분자로)
WHERE절에 매칭시킬 컬럼(연결고리)에 대한 조건을 제시함
- 1)연결할 컬럼명이 다른 경우(DEPT_CODE, DEPT_ID)
컬럼명이 다른 경우 WHERE절에 반드시 두 테이블의 컬럼명을 넣어야한다.
SELECT EMP_ID, EMP_NAME, DEPT_CODE, DEPT_TITLE
FROM EMPLOYEE, DEPARTMENT
WHERE DEPT_CODE = DEPT_ID;- 2) 연결할 컬럼명이 같은 경우(EMPLOYEE: JOB_CODE, DEPARTMENT: JOB_CODE)
여기까지 정리함
여기까지 정리함
여기까지 정리함!!!!!!!!!!!!!!!!!!!!!
JOIN 구문에서의 ON에서 조건과 WHERE 조건문 차이:
- ON: JOIN 전에 조건을 실행
- WHERE: JOIN 후에 조건을 실행
INNER JOIN에서는 둘 다 상관없지만
OUTER JOIN에서는 ON으로 해야 NULL값도 살아있는 상태로 테이블을 조회할 수 있음.
TABLE1
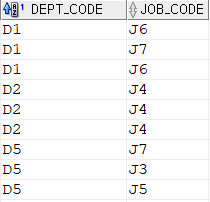
TABLE2
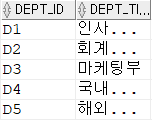
테이블이 이렇게 주어졌을 때
SELECT TABLE1.DEPT_CODE, TABLE1.JOB_CODE
FROM TABLE1
LEFT OUTER JOIN TABLE2 ON (DEPT_CODE = DEPT_ID)
AND TABLE2.DEPT_TITLE = '마케팅부';AND 조건일 때는
TABLE2의 세번째 컬럼을 제외한 모든 값들이 NULL을 띄며 조회됨
D1 J6 NULL NULL
D1 J7 NULL NULL
D1 J6 D3 마케팅부
...SELECT TABLE1.DEPT_CODE, TABLE1.JOB_CODE
FROM TABLE1
LEFT OUTER JOIN TABLE2 ON (DEPT_CODE = DEPT_ID)
WHERE TABLE2.DEPT_TITLE = '마케팅부';WHERE일 때는
TABLE2의 3행을 제외한 모든 값들이 조회 불가
D1 J6 D3 마케팅부오직 이 컬럼만 조회됨
포괄조인/외부조인:
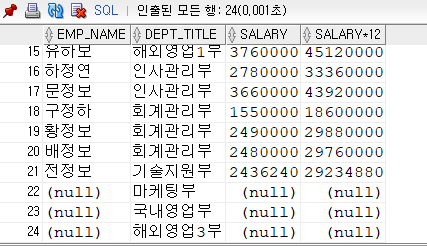
사원이름, 급여, 연봉 모두 없지만 DEPT_ID가 기준이기 때문에 조회가 됨.
