
수정 (2021-07-23)
※※ 대탈출 1화 관련된 스포일러가 포함되어 있습니다. ※※
노랑통닭 이제 안먹는다.
대탈출 시즌4 첫화는 망했다.
나는 재능있는 PD가 심혈을 기울여 만든 한시간 반짜리 노랑통닭 광고를 봤다.
시즌3 종영 이후 무려 1년이나 기다렸는데...
다른사람들은 어떻게 생각할까, 일단 데이터 수집이 만만한 트위터 반응부터 살펴보기로 했다.
트위터에서 대탈출 관련 트윗 수집하기
R 패키지 rtweet 을 사용하면 키워드를 이용해 쉽게 트윗을 수집할 수 있다.
search_tweets을 이용하면 키워드를 이용해 간편히 수집 가능하다.
library("rtweet")
TWEET_N <- 18000
HASHTAG <- "대탈출"
rt <- search_tweets(HASHTAG,
n=TWEET_N, # 수집할 tweet 수 (max 18000)
include_rts=FALSE) #리트윗 포함여부 FALSE 미포함, TRUE 포함위 코드를 실행하면 아래와 같이 계정인증을 요구한다.
매번 브라우저에서 로그인하기는 귀찮으므로 https://developer.twitter.com/en 에서 API 사용신청을 한 후 token을 생성해 저장해 놓는다. (github의 1. create_token.R)
TOKEN_NAME <- "./token/twitter_token.rds"
TWEET_N <- 18000
HASHTAG <- "대탈출"
twitter_token <- readRDS(TOKEN_NAME)
rt <- search_tweets(HASHTAG,
n=TWEET_N,
include_rts=FALSE,
token = twitter_token)이렇게 하면 매번 인증할 필요가 없다.
처음에는 "#대탈출"을 이용해 검색을 했으나 수집되는 트윗 양이 너무 적어 해시태그를 떼고 "대탈출" 키워드로 수집했다.
수집된 text를 확인해보면 굉장히 많은 컬럼들이 포함되어있는데 여기서는 본문 text만 필요하므로 text컬럼만 가져오고, 뒤에서 의미연결망을 그리기 위해 트윗별 id를 부여해준다.

성공적으로 대탈출 관련 tweet을 수집했지만 이모지, 링크, 특수문자 등 불필요한 찌꺼기들이 많이 포함되어 있다.
이제 이것들을 처리해보자
Text 전처리 하기
1. 필요한 텍스트만 남기기
추출한 데이터를 보면 불필요한 텍스트가 많이 포함되어 있어 모두 제거해 주었다.
제거한 것들
- URL
- 다른유저 언급 (@)
- 이모지 (😁 같은 것)
- 온전한 한글, 영어 제외 모든 것
추가처리
- 양쪽 끝 공백 제거
- 2개 이상 공백을 공백하나로 변환
- 영어를 전부 대문자로 변환
rmURLs <- function(x) { gsub("(f|ht)tp(s?)://\\S+", "", x, perl=T) }
rmTag <- function(x) { gsub("(@[A-Za-z가-힣0-9_]+)", "", x, perl=T) }
rmEmoji <- function(x) { gsub("[\U00010000-\U0010FFFF]+", "", x, perl=T) }
toSpace <- function(x, pattern) { gsub(pattern, " ", x) }
preprocess_text <- function(text_df) {
text_df %>%
mutate(text=rmURLs(text),
text=rmTag(text),
text=rmEmoji(text),
text=toSpace(text, "\n"),
text=toSpace(text, "[^가-힣A-Za-z]"),
text=gsub(" +", " ", text),
text=trimws(text),
text=toupper(text))
}
texts <- preprocess_text(texts)
깔끔해졌다!
2. 단어 추출하기 (사용자 사전)
위와 같이 데이터를 처리하고 바로 형태소 분석을 시도하니 문제가 생겼다.
대탈출, 여고추리반, 노랑통닭, PPL 등 사전에 없는 단어들이 제대로 형태소 분석이 되지 않았다.
이런경우 형태소분석기에 대탈출 관련 용어들을 사용자 사전을 등록해주면 되지만 굉장히 귀찮은 일이다... 재미로 하는일에 너무 많은 공수를 들이기는 싫어서 검색을 해보던 중 흥미로운 python 라이브러리가 있어 시도해 보았다.
soynlp 패키지
주어진 문서를 읽어서 해당 문서 안에서 사용되는 명사로 추정되는 단어를 추출해주는 Python라이브러리다.
이 경우에는 대탈출 방송과 관련된 단어들을 꽤나 추출해낼 수 있었다.
완벽한 사용자 사전이라고 할 순 없지만 나름 쓸만한 결과를 얻었고 재미로 하는거라 이정도만 하기로 했다.
이부분만 python으로 구현했고 추출된 단어들에서 필요해보이는 것들만 수동으로 골라내고 출연진 이름정도만 추가한 후 user_dict.txt에 저장해 형태소 분석기에 적용했다. (word_extraction.ipynb)
이런게 있는줄 알았으면 첨부터 전부 Python으로 할 걸
corpus_fname = 'twitter_text.txt'
with open(corpus_fname, 'r', encoding="cp949") as f:
lines = f.readlines()
lines = [s.replace("\n", "").replace('"', "") for s in lines][1:]
lines = [s.upper() for s in lines][1:]
from soynlp.word import WordExtractor
word_extractor = WordExtractor(
max_left_length=6,
min_frequency=10,
min_cohesion_forward=0.02,
min_right_branching_entropy=0.0
)
word_extractor.train(lines)
words = word_extractor.extract()import math
def word_score(score):
return (score.cohesion_forward * math.exp(score.right_branching_entropy))
print('단어 (빈도수, cohesion, branching entropy)\n')
for word, score in sorted(words.items(), key=lambda x:word_score(x[1]), reverse=True)[:100]:
print('%s (%d, %.3f, %.3f)' % (
word,
score.leftside_frequency,
score.cohesion_forward,
score.right_branching_entropy
)
)
대탈출, 스케일, 노랑통닭, 타임머신, 피피엘, 치킨, 시즌 등 사전에 없는 단어가 추출된다.
이후 형태소 분석 결과에서도 괜찮은 결과를 얻었다.
3. 형태소 분석하기
형태소 분석기는 tidytext 와 함께 사용하기가 쉽고 설치도 간단한 Elbird 패키지를 사용했다.
library("tidytext")
library("Elbird")
tokenize_text <- function(text_df) {
text_df %>%
unnest_tokens(
input = text,
output = word,
token = analyze_tidy
) %>%
separate(word, sep="/", into=c("word", "morph"))
}
read_user_dict("./user_dict.txt")
words <- tokenize_text(texts)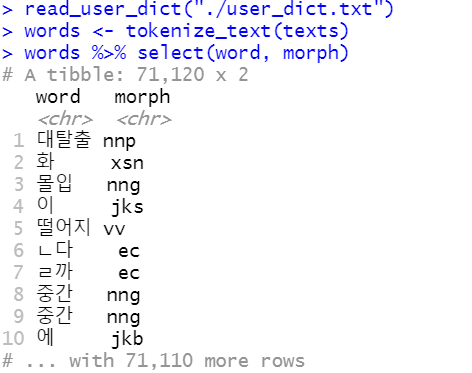
형태소별로 분리된 단어 데이터 프레임을 얻었다!!
ㄴ까, ㄹ까, 에 같은 형태소들은 필요 없으므로 관심있는 품사만 남기고 제외하고 전부 제거해준다.
- 형용사 뒤에는 다를 붙여줘서 보기 좋게 만들자
ex) "재미있" -> "재미있다" - 같 이란 형용사가 큰 의미없이 너무 많이 등장해서 제거했다. ( 별로인 것 같은데... 처럼 말끝에 "같다"를 쓰는사람이 많았다. )
그리고 남은 단어들을 갯수를 세서 빈도수 내림차순으로 정렬해준다.
target_morph <- c("nng", "nnp", "va", "xr", "sl", "@")
synonym <- data.table::fread("synonym.csv", encoding = "UTF-8")
synonym_dict <- NULL
for (i in 1:dim(synonym)[1]){
# print(i)
synonym_dict[synonym$og[i]] <- synonym$synonym[i]
}
processed_word <- words %>%
filter(morph %in% target_morph,
word!="같") %>%
mutate(word=ifelse(morph=="va", paste0(word,"다"), word),
word=ifelse(word %in% names(synonym_dict),
synonym_dict[word],
word),
word=toupper(word)) %>%
count(word) %>%
filter(nchar(word)>1,
n>10) %>%
rename(freq=n) %>%
arrange(desc(freq))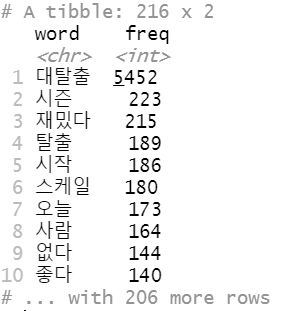
wordcloud 그리기
이제 wordcloud 그리기는 아주 간단하다.
library(wordcloud2)
SOURCE_NAME <- "twitter"
# preprocess.R 먼저 실행
processed_word$freq[1] <- min(processed_word$freq[1],
processed_word$freq[2]*2)
wc <- wordcloud2(
processed_word,
size=1.5,
color = c("black",
sample(
rep_len(gray.colors(20, start = 0, end = .4),
nrow(processed_word) - 1),
nrow(processed_word) - 1
)),
backgroundColor = "#FFE400",
rotateRatio = .4,
shape = "diamond",
gridSize = 7,
ellipticity = .6,
shuffle=FALSE
)
wc워드클라우드에서는 빈도수 = 글자크기 인데 대탈출 이라는 단어가 검색 키워드라 그런지 모든트윗에 포함되서 너무 크게 나왔다. 적당히 크기를 조절해줘서 보기 예쁘게 한다.
대탈출 포스터를 보면 노란 바탕에 검은색 글씨만사용하니까 맞춰서 그려보자.
노란 바탕색은 대탈출 포스터를 검색해서 color picker로 찍어왔다.
대탈출 테마 색으로 맞춰서 그렸는데, 노랑통닭 색깔이다 화가난다.

그래도 예쁘게 잘 나왔다. 한번 살펴보자
- 역시 PPL, 노랑통닭 이 아주 크게 보인다.
- 재밌다 가 아주 많이 등장한다. 재밌게 본사람이 많구나...
- 이번화는 아스달연대기 세트장에서 촬영을 했기때문에 아스달, 연대기, 세트장 같은 단어들도 보인다.
- 정종연PD의 이전작품 여고추리반 에 대한 언급이 많았다.
- 그외에 시즌, 시작, 기대, 스케일 등등 첫방의 기대감에 대한 내용들도 보인다.
의미연결망 그리기
하는김에 의미연결망도 그려보자
library("widyr")
library("tidygraph")
library("ggraph")
library("showtext")
SOURCE_NAME <- "twitter"
texts <- readRDS(get_latest_data(SOURCE_NAME)) %>%
get_text(SOURCE_NAME)
texts <- preprocess_text(texts)
words <- tokenize_text(texts)
# -------------------------------------------------------------------------
target_morph <- c("nng", "nnp", "va", "xr", "sl", "@")
pair <- words %>%
mutate(word=ifelse(morph=="va", paste0(word,"다"), word),
word=ifelse(word %in% names(synonym_dict),
synonym_dict[word],
word),
word=toupper(word)) %>%
filter(word!="대탈출",
word!="같다",
nchar(word)>1,
morph %in% target_morph) %>%
pairwise_count(item=word,
feature=id,
sort=T)
# 관련없는 키워드 삭제
trash <- c("LT", "GT",
"결제", "티빙",
"유니", "버스",
"피오", "블락비", "BLOCKB",
"같다",
"인성", "최고", "신사", "축하", "생일", "HAPPYINSEONGDAY")
set.seed(1)
graph_component <- pair %>%
filter(n>7,
!((item1 %in% trash) & (item1 %in% trash))) %>%
as_tbl_graph(directed=FALSE) %>%
mutate(centrality=centrality_degree(),
group=as.factor(group_infomap()))
ggraph(graph_component,
layout="nicely") +
geom_edge_link(color="gray50",
alpha=.5) +
geom_node_point(aes(color=group,
size=centrality),
show.legend = FALSE) +
scale_size(range=c(5, 15)) +
geom_node_text(aes(label=name),
repel=TRUE,
size=5,
family="naumgothic") +
theme_graph()의미연결망을 그리고 나니 출연진중 한명인 피오와 소속그룹 BLOCKB에 대한 언급이 너무 많아서 제외해주었다.
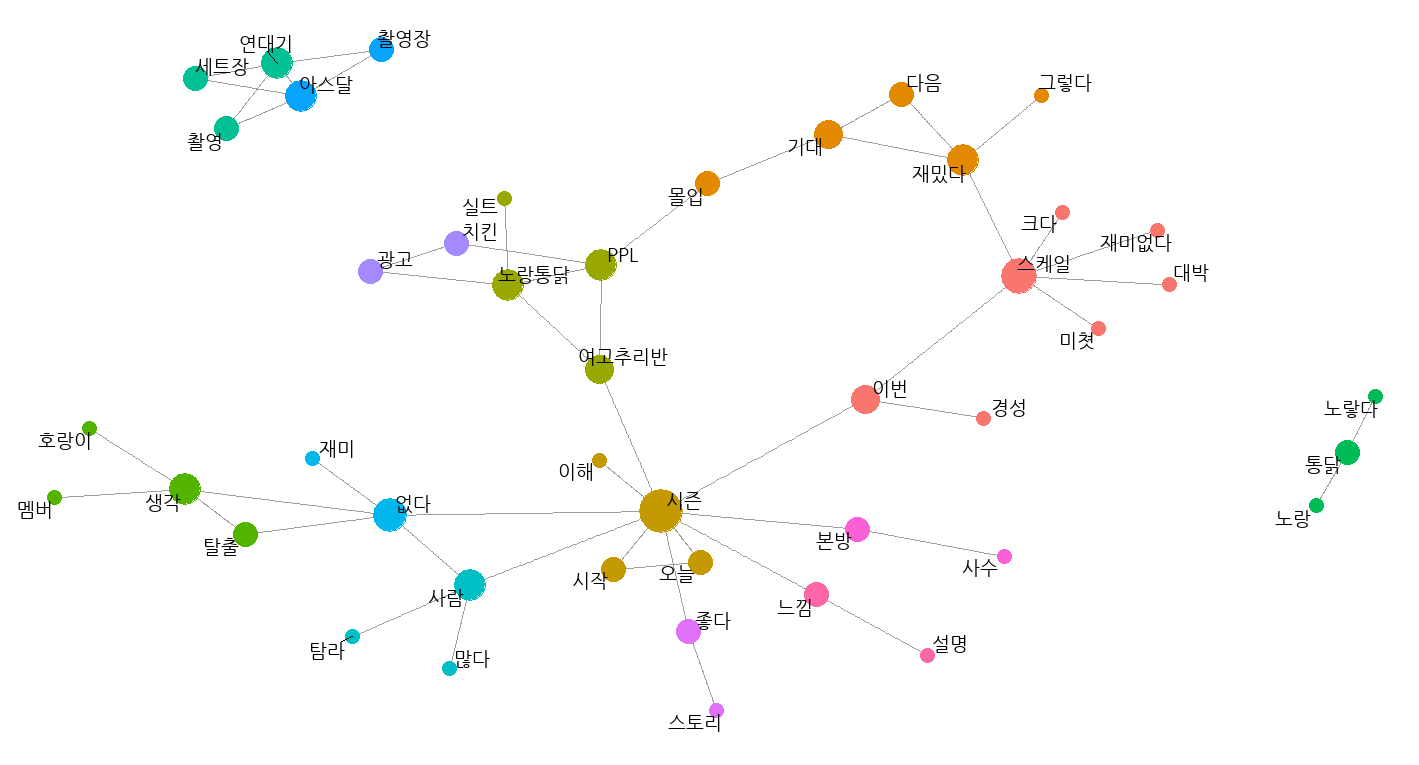
마찬가지로 살펴보자
- 좌측 상단에 아스달연대기 세트장에 대한 언급들이 따로 분리된다.
- 그리고 우측 노랑통닭에 대한 언급들도 따로 분리된다.
- 중앙쪽에 여고추리반, 노랑통닭, PPL 이 연결되있어서 좀 찾아봤더니, 이전작인 여고추리반에서 노랑통닭을 엄청 노출시켜서 결국 PPL을 따냈다는 내용의 트윗이 많았다.
- 중앙 하단쪽 시즌시작에 대한 언급들도 많이 보인다.
- 경성부터 이어지는 타임머신 세계관의 스케일에 대한 감탄과 스케일만 크지 재미없다는 혹평이 동시에 등장한다.
- 호랑이관련 내용은 첫방을 보신 분이라면 아마 알 듯 하다.
마무리
나름 재미있었다.
첫방이후 찔끔찔끔 포스팅하다보니 어느새 2화도 방영했다.
물론 2화 이후에도 동일한 코드를 돌려서 분석해보았다.
이것도 나중에 결과만 포스팅해야지...
참, 유튜브 다음화 예고편에서 댓글 수집해서 만든 유튜브 버전도 있는데 이쪽은 비판적인 의견이 훨씬 많은 것 같다.
유튜브 댓글 수집한 결과도 언젠가 포스팅 예정...
시간이 될 때, 코드를 좀 더 정리해서 매주 자동으로 돌아가게 만들어 봐야겠다.
끝!
