데이터 읽기
import pandas as pd
data_path = '../데이터셋/'
train_raw = pd.read_csv(data_path+'train.csv')
test_raw = pd.read_csv(data_path+'test.csv')train_raw.head()
여기서 필요한 것은 종속변수인 category와 독립변수인 data이다.
test_raw.head()
test 데이터는 data만 있는 것을 볼 수 있었다.
결측치 확인 및 처리
train_raw.isnull().sum()
결측치가 data열에 8개 있는 것을 확인했고, 데이터는 충분하기 때문에 결측치가 있는 행을 drop하는 것을 선택했다.
train_raw = train_raw.dropna()형태소 분석 준비
형태소 분석에는 Rhino를 사용했다.
import rhinoMorph
rn = rhinoMorph.startRhino()
train_data = list(train_raw.data)
train_category = list(train_raw.category)
test_data = list(test_raw.data)escape 문자 제거
data를 보면 \n과 같이 쓸모 없는 단어들이 많았고, 이를 정규식을 이용해 제거해줬다.
import re
for i in range(len(train_data)):
train_data[i] = re.sub('[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]', ' ', train_data[i])
train_data[i] = train_data[i].strip()
for i in range(len(test_data)):
test_data[i] = re.sub('[^가-힣ㄱ-ㅎㅏ-ㅣ\\s]', ' ', test_data[i])
test_data[i] = test_data[i].strip()형태소 분석
morphed_data = []
morphed_cat = []
cnt = 0
for data_each in train_data:
if cnt % 10000 == 0:
print('cnt : ', cnt)
morphed_data_each = rhinoMorph.onlyMorph_list(
rn, data_each, pos=['NNG','NNP','VV','VA','XR','IC','MM','MAG','MAJ'], eomi=True)
if morphed_data_each != []:
morphed_data.append(morphed_data_each)
morphed_cat.append(train_category[cnt])
cnt += 1morphed_test_data = []
cnt = 0
for data_each in test_data:
if cnt % 1000 == 0:
print('cnt : ', cnt)
morphed_data_each = rhinoMorph.onlyMorph_list(
rn, data_each, pos=['NNG','NNP','VV','VA','XR','IC','MM','MAG','MAJ'], eomi=True)
if morphed_data_each != []:
morphed_test_data.append(morphed_data_each)
cnt += 1저장하기 위해 라벨과 텍스트 연결하기
joined = ''
cnt = 0
for tmp in morphed_data:
joined_data = ' '.join(tmp)
if joined_data:
joined += str(morphed_cat[cnt]) + '\t' + joined_data + '\n'
cnt += 1joined_test = ''
for tmp in morphed_test_data:
joined_data = ' '.join(tmp)
if joined_data:
joined_test += joined_data + '\n'파일 저장
나중에 스터디원들을 위해 파일을 저장해둔다.
def write_data(data, filename, encoding='cp949'):
with open(filename, 'w', encoding=encoding) as f:
f.write(data)
write_data(joined, data_path+'morphed.txt', encoding='cp949')
write_data(joined_test, data_path+'morphed_test.txt', encoding='cp949')형태소 분석한 데이터 읽어오기
def read_data(filename, encoding='cp949'):
with open(filename, 'r', encoding=encoding) as f:
data = [line.split('\t') for line in f.read().splitlines()]
return data
def write_data(data, filename, encoding='cp949'):
with open(filename, 'w', encoding=encoding) as f:
f.write(data)train = read_data(data_path+'morphed.txt')
test = read_data(data_path+'morphed_test.txt')train_text = []
train_label = []
for val in train:
train_label.append(int(val[0]))
train_text.append(val[1])데이터의 길이 통계
from collections import Counter
import numpy as np
text_len = [len(line.split(' ')) for line in train_text]
print('최소길이: ', np.min(text_len))
print('최대길이: ', np.max(text_len))
print('평균길이: ', np.mean(text_len))
print('중위수 길이: ', np.median(text_len))
print('구간별 최대 길이: ', np.percentile(text_len, [0, 25, 50, 75, 90, 100]))
print('최소길이 문장: ', train_text[np.argmin(text_len)])
print('최대길이 문장: ', train_text[np.argmax(text_len)])
보면 90%와 100%의 차이가 많이 큰 것을 보아 이상치가 있고, 90%정도에서 자르는 것이 좋아보인다.
Tokenizing
from keras.preprocessing.text import Tokenizer
from keras_preprocessing.sequence import pad_sequences
max_words = 10000
maxlen = 260
tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(train_text)
word_index = tokenizer.word_indexprint(f'전체에서 {len(word_index)}개의 고유한 토큰을 찾았습니다.')
print('word_index: ', word_index)
Data Sequencing
data = tokenizer.texts_to_sequences(train_text)Data Padding
data = pad_sequences(data, maxlen=maxlen)One-Hot Encoding
def to_one_hot(sequences, dimension):
result = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
result[i, sequence] = 1
return resultdata = to_one_hot(data, max_words)
labels = to_one_hot(train_label, 3) # 0,1,2로 분류되기 때문sequencing한 텍스트 데이터와 라벨을 원-핫 인코딩해준다.
데이터 분리 (Train, Validation)
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(data, labels, stratify=labels)모델 층 쌓기
epochs = 10
batch_size = 32
from keras.models import Sequential
from keras.layers import Dense
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(max_words,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.summary()
노드 수는 적당히 정했고, 다중 분류이기 때문에 출력층의 활성화 함수는 softmax를 이용했다.
모델 컴파일
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc'])optimizer는 Adam, loss는 다중 분류 문제이므로 categorical_crossentropy를 사용한다.
모델 훈련 (Train, Validation)
from tensorflow.keras.utils import Sequence
class DataGenerator(Sequence):
def __init__(self, x_set, y_set, batch_size):
self.x, self.y = x_set, y_set
self.batch_size = batch_size
def __len__(self):
return int(np.ceil(len(self.x) / float(self.batch_size)))
def __getitem__(self, idx):
batch_x = self.x[idx * self.batch_size: (idx + 1) * self.batch_size]
batch_y = self.y[idx * self.batch_size: (idx + 1) * self.batch_size]
return batch_x, batch_y
train_gen = DataGenerator(x_train, y_train, batch_size)
test_gen = DataGenerator(x_val, y_val, batch_size)
history = model.fit(train_gen, epochs=epochs, batch_size=batch_size, validation_data=test_gen)
history_dict = history.history한 번에 안 돌아가길래 DataGenerator를 만들어서 사용했다.

성능 확인
acc = history_dict['acc']
val_acc = history_dict['val_acc']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
print('Validation accuracy of each epoch: ', np.round(val_acc, 3))
ep = range(1, len(val_acc) + 1)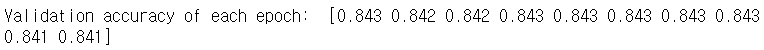
Plotting Accuracy & Loss
import matplotlib.pyplot as plt
plt.plot(ep, acc, 'bo', label='Training Acc')
plt.plot(ep, val_acc, 'r', label='Validation Acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.show()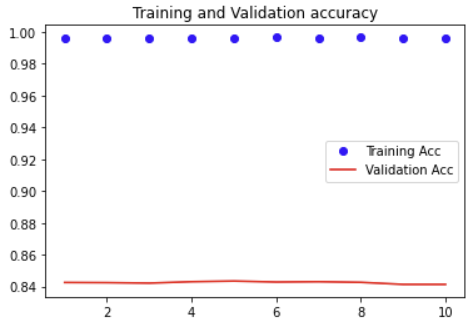
plt.plot(ep, loss, 'bo', label='Training Loss')
plt.plot(ep, val_loss, 'r', label='Validation Loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()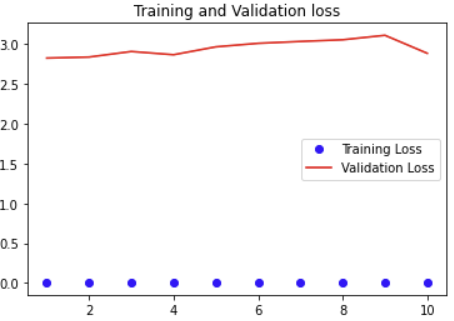
Test 데이터 Sequencing, Padding, One-Hot Encoding
test_text = []
for i in test:
test_text.append(i[0])test_d = tokenizer.texts_to_sequences(test_text)
test_d = pad_sequences(test_d, max_words)
test_d = to_one_hot(test_d, max_words)Test 데이터 예상 및 평가
pred = model.predict(test_d)
pred = np.argmax(pred, -1)제출용 파일 만들기
submit = pd.read_csv(data_path+'sample_submission.csv')
submit.category = pred
submit.to_csv('KrTeaparty_submission.csv', index=False)제출 후기
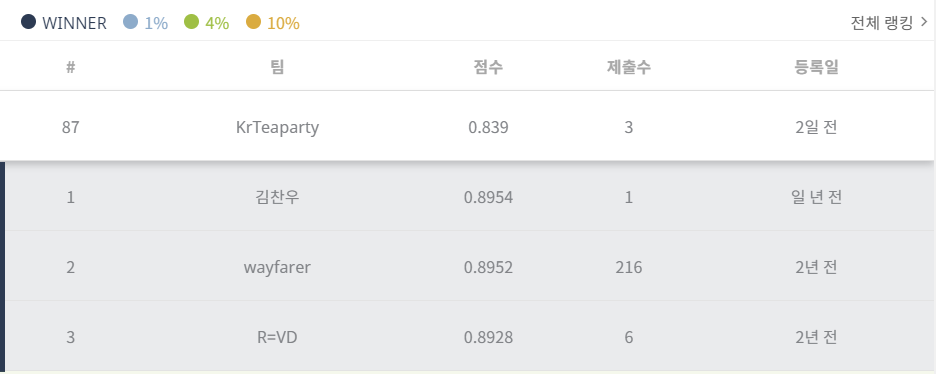
제출 결과 0.839가 나왔다. 아무 것도 조정하지 않은 상태에서 이정도 결과가 나올 줄은 몰랐다.
불용어가 상위 빈도에 출현하는 것을 확인했기 때문에 불용어 처리도 해보았지만 성능은 떨어졌다.
추가로 모델을 개선할 때 시도해볼 만한 것은 Dropout과 규제 정도가 유효해보인다.

데이터를 접하는 중