1. PaddleSeg
- PaddlePaddle
: Baidu에서 개발한 오픈 소스 딥러닝 프레임워크. 딥러닝 모델의 설계, 훈련, 배포 등 다양한 단계에서 사용됨
- PaddleSeg
: PaddlePaddle을 기반으로 한 semantic segmentation 라이브러리 이다. 다양한 세그멘테이션 모델과 데이터 처리 도구를 포함
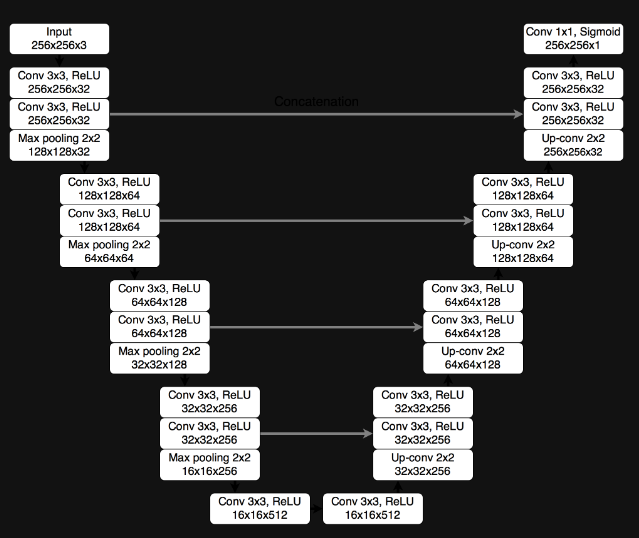
- UNet
: 의료 영상 분야 세그멘테이션에 주로 사용되는 신경망 아키텍쳐. U모양의 구조를 가지며, 입력 이미지와 동일한 크기의 세그멘테이션 맵을 출력으로 생성하며, 인코더와 디코더로 구분되어 이미지의 특징을 감지하고 복원하는 과정을 수행
PaddleSeg내에서도 UNet 모델 아키텍쳐를 사용한 pre-trained model을 제공
1) 다른 데이터셋 모델로 바꾸었더니 인식률 개선됨
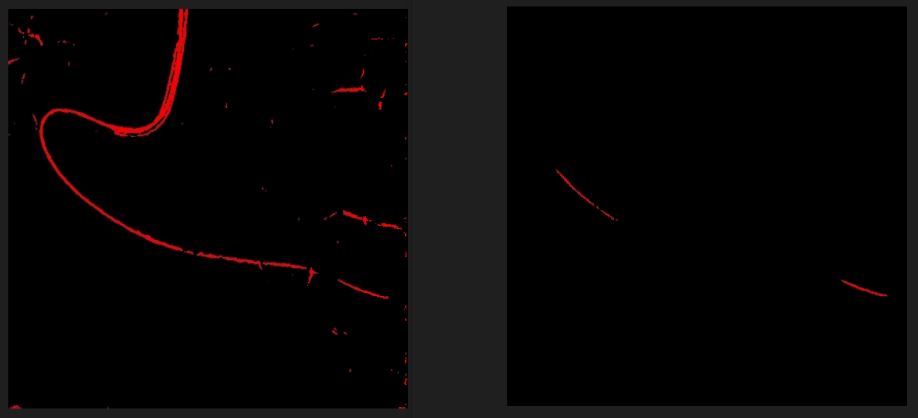
동일한 pre-trained 모델을 사용하더라도 데이터셋에 따라 세그멘테이션(segmentation) 결과가 달라질 수 있음.
① 다양한 데이터 분포: 세그멘테이션 모델은 주어진 데이터에 적응하여 물체 경계를 학습한다. 따라서 데이터셋마다 물체의 모양, 크기, 색상 등의 분포가 다를 수 있다. 이로 인해 동일한 모델이라도 서로 다른 데이터셋에서는 물체 경계를 다르게 예측할 수 있다.
② 클래스 및 레이블의 차이: 세그멘테이션 작업에서 클래스나 레이블의 정의는 데이터셋에 따라 다를 수 있다. 예를 들어, 어떤 데이터셋에서는 "나무"라는 클래스를 세분화하여 "소나무", "참나무" 등으로 나눌 수 있지만, 다른 데이터셋에서는 이를 구분하지 않을 수 있다. 이러한 클래스 및 레이블의 차이로 인해 모델은 각 데이터셋마다 다른 객체를 다르게 처리할 수 있다.
③ 클래스 불균형: 데이터셋에 따라 특정 클래스의 빈도가 다를 수 있다. 예를 들어, 어떤 데이터셋에서는 풍경에서 사람의 비중이 크지만, 다른 데이터셋에서는 사람이 드물게 등장할 수 있다. 이로 인해 모델은 상대적으로 더 빈번한 클래스에 더 많은 주의를 기울일 수 있다.
④ 환경 및 조명 변화: 데이터셋마다 환경과 조명 조건이 다를 수 있다. 세그멘테이션 모델은 주변 환경 및 조명에 민감하게 반응할 수 있으며, 이로 인해 동일한 물체라도 배경과의 경계를 다르게 인식할 수 있다.
⑤ 데이터 품질 및 양: 데이터셋의 품질과 양은 모델의 성능에 영향을 미칩니다. 더 많은 다양한 데이터로 모델을 학습시키면 일반화 성능이 향상될 가능성이 높다. 따라서 데이터셋의 크기와 품질이 세그멘테이션 결과에 영향을 줄 수 있다.
데이터셋의 특성을 잘 이해하고 모델을 적절하게 조정하면 원하는 성능을 얻을 수 있음. 즉 pre-trained 모델을 사용하면 "tuning"이 필요하다고 볼 수 있다.
2) PaddleSeg Unet
Unet은 의료 이미지 분석 및 컴퓨터 비전 분야에서 널리 사용되는 심층 신경망 아키텍처 중 하나로, 주로 의료 영상에서의 세그멘테이션 작업에 사용된다.
PaddleSeg 라이브러리에서 제고아는 UNet 아키텍쳐 기반의 pre-trained 모델을 사용하여 세그멘테이션을 수행하고자 한다.
3) UNet 모델의 주요 특징
① 인코더 : 입력 이미지를 다운샘플링하여 특징 맵을 추출
② 디코더 : 인코더에서 추출한 특징을 사용해 원본 입력이미지와 동일한 해상도의 세그멘테이션 맵을 생성. 업샘플링되어 확장되는 과정
4) 다운샘플링
- 이미지의 해상도를 점차 줄이는 프로세스
- 컨볼루션과 풀링 연산은 통해 중요 특징을 추출
- 풀링연산은 일정 영역 내 정보를 요약하여 대표값을 추출하고, 이를 이용해 해상도를 낮추는 과정
- 풀링 연산에는 Max Pooling 과 Average Pooling이 존재
ⓐ Max Pooling
: 주어진 영역 내 가장 큰 값을 선택하여 대표값으로 사용
ⓑ Average Pooling
: 주어진 영역 내 평균 값을 대표값으로 사용
5) 업샘플링(or 업스케일링)
- 이미지의 해상도를 점차 높이는 프로세스
- 데이터의 차원을 확대하거나 저해상도를 고해상도로 복원
- UNet모델은 다운샘플링 과정에서 버려진 공간 정보와 세부 정보를 복원하기 위해 엄샘플링을 사용