0. 개요
DBMS는 예기치 못한 장애(Crash)발생 시 데이터베이스의 복구를 위해 log record와 check point를 사용해 복구 작업을 실행한다. 그렇다면 어떤 과정으로 복구를 실행할 수 있는가?
1. Transaction and Disk
1) 디스크와 메인 메모리간 데이터 이동
- input
트랜잭션이 데이터베이스의 데이터를 처리하기 위해 데이터를 디스크에서 메인메모리로 가져와야함 - output
메인 메모리의 작업 결과를 다시 디스크에 반영해야함
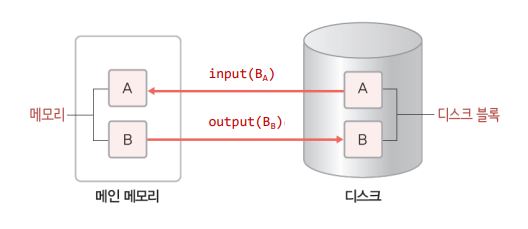
① input(Bx) : data X를 보함하고 있는 디스크 블록(Bx)를 메인 메모리로 이동시키는 연산
- on demand (요청 즉시 실행)
② output(Bx) : data X를 포함하는 메인 메모리 버퍼 블록 Bx를 디스크 블록에 이동시키는 연산
- by buffer manager (실행 시기를 알 수 x)
왜 disk에 반영되는 실행 시기를 알 수 없을까?
- buffer manager의 "steal, no force" policy 때문. (for response time & throuhput)
2) 메인 메모리와 변수 간 데이터 이동 연산
응용 프로그램에서 트랜잭션 수행을 지시한 경우
- read(x)
메인 메모리 버퍼 블록에 저장된 데이터 x를 프로그램의 변수로 읽어옴 - write(x)
프로그램의 변수 값을 메인 메모리 버퍼 블록에 데이터 x에 기록
① read(x) : 내부적으로 input(Bx)가 실행
- 디스크블록 > 메인 메모리 버퍼 블록 > 프로그램 변수
② write(x) : output(Bx)가 실행되어야 연산의 결과가 안전하게(비휘발성) 디스크의 데이터베이스에 저장
- 만약, write(x)는 실행하였으나 output(Bx)가 실행되기 전에 트랜잭션 붕괴 시 변경된 x값이 상실!!
2. Crash & Recovery
- Redundancy(중복)이 핵심
- Dump
데이베이스 전체를 다른 저장 장치에 주기적으로 복사
- Log
데이터베이스에서 변경 연산이 실행될 떄마다 데이터를 변경하기 이전 값과 변경 후 값을 별도의 파일에 기록
1) 회복을 위한 연산
① redo(재실행)
: 가장 최근에 저장된 데이터베이스의 복사본을 가져와 로그를 이용해 복사본 생성 이후에 실행 된 모든 변경 연산을 재실행 하여 장애 발생 직전의 데이터베이스 상태로 복구
② undo(취소)
: 로그를 이용해 지금까지 실행된 모드 변경 연산을 취소해 데이터베이스를 원래의 상태로 복구
2) 로그 파일
※ 하기의 내용은 Recovery-① 에 기재한 prevLSN,page_length 등의 필드는 생략하고 기본적인 필드만 고려
<Ti, start>
- Ti가 수행을 시작
<Ti, X, old_val, new_val>
- Ti가 X를 old_val에서 new_val로 갱신
<Ti, commit>
- Ti가 성공적으로 완료
<Ti, abort>
- Ti가 철회됨
3. Recovery - ①
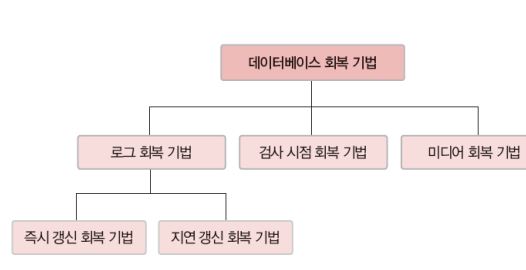
1) 로그 회복 기법
① 지연 갱신 회복기법
-
트랜잭션이 '부분 완료' 상태가 될 때까지 모든 output()연산을 "지연"
-
<Ti, commit>을 포함하는 로그 레코드를 로그 파일에 기록한 후 데이터베이스에 갱신 요청(output() 연산 요청) 후 '완료'상태로
★ 장애 발생 시
⑴ 트랜잭션이 완료되기 전 장애 발생
=> 로그 내용을 무시하고 버림
⑵ 트랜잭션 완료 후 장애 발생
=> redo 연산 실행
② 즉시 갱신 회복기법
-
트랜잭션이 '진행'중인 상태에서 변경 연산 결과를 데이터베이스에 갱신 요청(output() 연산 요청)
★ 장애 발생 시
⑴ 트랜잭션이 완료되기 전 장애 발생
=> undo
⑵ 트랜잭션이 완료 후 장애 발생
=> redo
2) 검사 시점 회복
-
checkpoint를 주기적으로 검사하여 검사 시점부터 검사하도록
-
검사 시점에 다음의 작업을 수행
① 메인 메모리(로그 버퍼)에 있는 모든 로그 레코드를 디스크에 기록
② 메인 메모리 버퍼에 있는 모든 변경 연산의 결과를 디스크에 있는 데이터베이스에 반영
③ 검사 시점을 표시하는 <checkpoint, L> 로그 레코드를 로그 파일에 기록- L은 현재 실행되고 있는 트랜잭션 리스트
여기까지는 기본적인 회복 기법.
4. Recovery - ②
1) Crash Recovery - Big Picture

< Three Phase>
- A(Analysis) : start from chkpt
- R(Redo) : page를 업데이트한 로그 레코드 중 가장 오래된 것(recLSN)부터 REDO(재실행)
- U(Undo) : 실행 중인 트랜잭션의 가장 오래된 레코드부터 UNDO(취소)
=> UNDOING transaction which is not commited at crash
※ 참고 Database Management Systems, 3ed, R. Ramakrishnan and J. Gehrke
※ (즉시 갱신 회복 기법 기준)
Transaction Table
: active Xact들을 관리
- contains
XID, status(running/commited/aborted), lastLSN
Dirty Page Table (DPT)
: dirty page in buffer pool들을 관리
- contains
recLSN(first caused page to be dirty)
① Analysis
checkpoint부터 검사
- End record : 트랜잭션 '완료' 후 장애 발생되었으므로 Xact table에서 트랜잭션 삭제
- other records : 트랜잭션이 완료 전 장애 발생 => Xact table에 트랜잭션 추가 & lastLSN = LSN
- 만약 P가 DPT에 없다면, Add Pto D.P.T & recLSN=LSN
② REDO
트랜잭션 '완료' 후 장애 발생 시 REDO
- DPT의 smallest recLSN부터 REDO
- 각 CLR 또는 업데이트 로그 레코드의 LSN을 확인하고, 다음 조건을 만족하지 않는 경우 해당 작업을 재실행
ⓐ Affected page is not in Dirty Page Table(D.P.T)
ⓑ Affected page is in D.P.T, but has recLSN > LSN
ⓒpageLSN >= LSN
③ UNDO
트랜잭션 완료 전 장애 발생 시 UNDO
2) Example of Recovery

※ First Crash
① Analysis
LSN30 : T1 abort => UNDO LSN10, but already undone at CLR,40
LSN50(P1) , LSN20(P3), LSN10(P5) : dirty pages
LSN45 : T1 is cornpleted transaction
T2,T3 : Xact Transaction
② REDO
Nothing to consider
③ UNDO
UNDO T2 LSN 60
UNDO T3 LSN 50, T3 end (T3의 UNDO 종료)
T2를 UNDO하는 과정에 Crash 발생 & Restart
※ Second Crash
UNDO T2 LSN 20
