0. Why Parallel Access to Data?
1 Terabytes Data를 처리하기위해 10MB/s를 사용하면 1.2일이 걸리는 반면, 1000개의 parallel access를 통해 1.5분에 처리
=> Data의 빠른 처리를 위해 분산 처리를 하고자 병렬로 접근
1. Parallel DBMS
Parallelism is natural to DBMS processing
1) Pipeline parallelism
: many machines each doing one step in multi-step process
2) Partition parallelism
: doting same thing(step) to different pieces of data
1. Types of Architecture
1) Shared Memory(SMP)
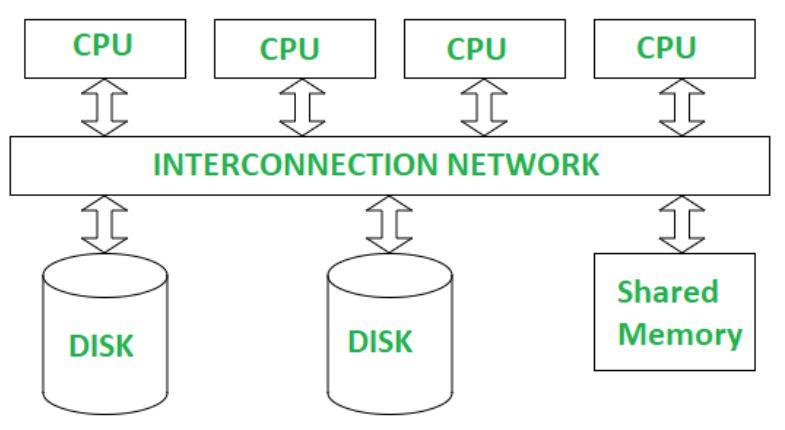
프로세스간 메모리를 공유, 디스크는 각자
: 프로그래밍하기는 쉬우나, 확장성이 낮다.
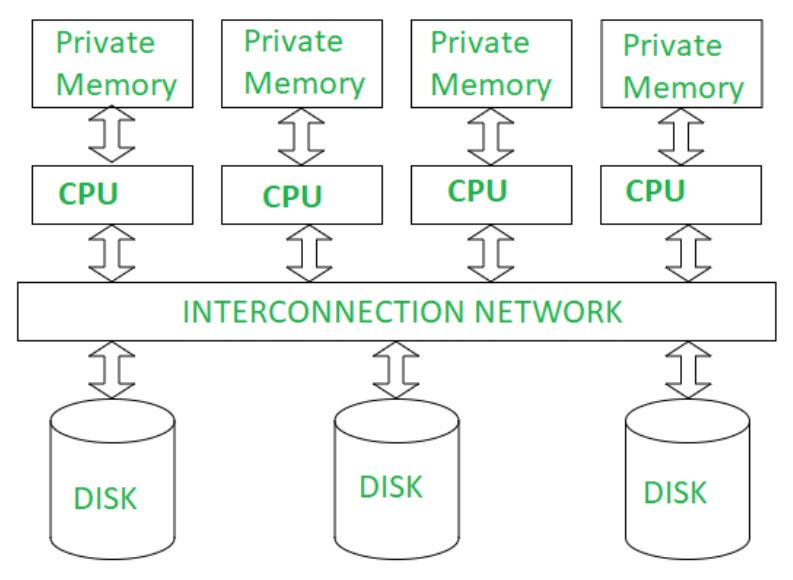
2) shared disk
3) shared nothing (network)
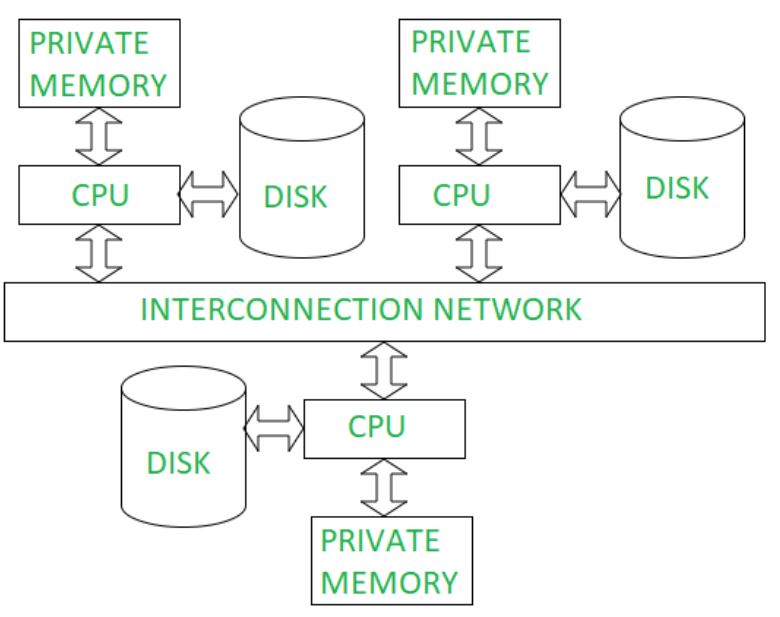
: 다른 프로세스가 네트워크로 연결되어, 프로그래밍하긴는 어려우나, 구축이 쉽고 확장성이 좋다
2. Different Types of DBMS
- pipe lining 개념
machine cycle : fetch, decode, execution의 cycle은 여러 operator로 구성
1) Intra-operator parallelism
: all machines working to compute a given operation (scan, sort, join etc..)
- 여러 원격 사이트가 같은 연산을 동시에 수행 (연산자 내 병렬처리)
e.g Select 연산자의 작업을 여러 개의 스레드 또는 프로세스를 사용하여 병렬로 실행. 각 프로세스는 동일한 연산자에 대해 다른 입력 데이터 조각을 처리하고 결과를 mergel
-> 단일 연산자의 처리 속도를 향상
2) Inter-operator parallelism
: each operator run concurrently on different site (pipelining 방식, 연산자 간 병렬처리)
- 여러 연산자는 전체 데이터 처리 파이프라인에서 다른 작업을 수행
e.g SELECT, JOIN, GROUP BY 등 여러 연산자가 순차적으로 실행하여
-> 전체 쿼리의 처리 속도 향상
3) Inter-query parallelism
: different queries run on different sites
- 독립적인 쿼리를 여러 사이트에서 동시에 처리
-> 데이터베이스 시스템의 처리 속도와 확장성을 향상
3. Data Partitioning
: data 분할 (★) , data 쪼개기
- partitioning a table
1) Range Partition

: table의 attribute에 대해 sorting
=> 범위에 따라 분할
i. equljoin
ii. 범위 질의
iii. group by
query에 적합
2) Hash
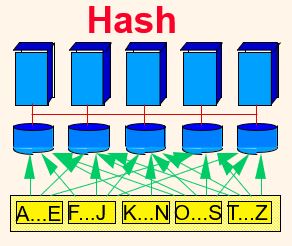
: 정렬후 hash값에 따라 해당되는 disk에 저장.
equijoin 에 적합
3) Round Robin
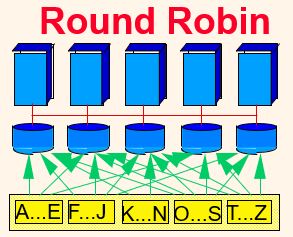
: sorting 후, Round Robin 방식으로 데이터를 디스크에 할당
골고루 분산됨 (balanced partitioning, 균등 분할)
<=> range나 hash는 골고루와는 거리가 멈
- shared disk나 shared memory 아키텍쳐는 partitioning 방식에 영향을 덜 받음, but shared nothoing의 경우 partitioning 방식이 중요함.
