문제 설명
위와 같이 입력받은 문자열에서 중복 없는 가장 긴 길이의 문자열의 길이를 리턴하는 문제이다.
결과 1
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if len(s) == 1 :
return len(s)
left = 0
right = 0
answer = 0
while right<len(s):
temp = s[left:right+1]
if len(temp)>len(set(temp)) :
left+=1
continue
if len(temp)>answer:
answer = len(temp)
right += 1
return answer문제를 보면 전형적인 투포인터/슬라이딩 윈도우 문제같다.
그래서 평소 아는대로 작성해보았지만 결과는 통과해도, 16.47%의 처참한 결과를 보여준다

답은 맞는데 더 좋은 방법을 찾아야 한다
사실 이 문제는 해시 테이블에 관련되어 나온 문제이기 떄문에
해시테이블을 이용해 풀어봐야 할 것 같다.
개선 방법에 대한 고찰

해시테이블
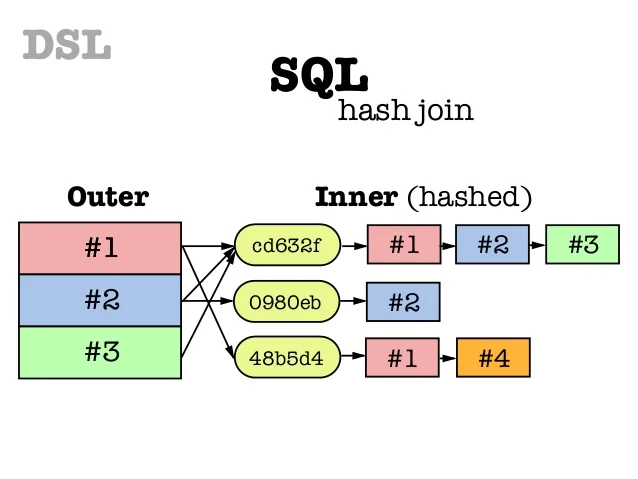
해시테이블은 입력받은 데이터에서 일정한 규칙으로 index 만들어 테이블의 해당 위치에 key:value를 갖은 해시들이 들어가게 된다.
이렇게 해시테이블로 구성할 경우 검색에서 O(1)이라는 놀라운 시간복잡도를 보여준다.
다만 같은 index가 도출되어 충돌이 일어날 수 있는데, 그럴 경우 해당 index 마지막 해시와 연결시켜 추후 key값으로 선형조회하여 찾는다. 그렇기에 사실 언제나 상수시간이라고 할 수 없지만 일반적으로는 거의 그렇다고 한다.
하지만 위 사진을 보고 이렇게만 들으면 해시테이블 만들기는 상당히 길고 복잡한 코드가 될 것 같다.
그런데 이를 어떻게 문자열 찾기에 응용할 수 있을까?
결과 2
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
if len(s) == 1 :
return len(s)
table = {}
answer = 0
left = 0
for i,char in enumerate(s) :
if char in table and left <= table[char]: # 중복 문자이며 이미 지나쳐온 중복 문자일 경우
left = table[char] + 1 # 윈도우 내의 첫번째 중복 문자 앞으로 left를 당김
else : # 중복이 없으면 문자열 전진
windowLength = i + 1 - left #현재 윈도우 사이즈. +1을 하는 이유는 index가 0에서 시작하기 때문
if answer < windowLength : answer = windowLength #현재 윈도우 길이가 이전 최장길이보다 길면 답교체
# answer = max(answer, i +1 - left) <- 이렇게 하면 더 빠름
table[char] = i #테이블에 문자열의 문자가 key로 담긴 곳에 현재 index값 넣기.
이러면 윈도우 내의 문자들 위치가 계속해서 갱신된다
return answer표로 정리해본 솔루션 흐름
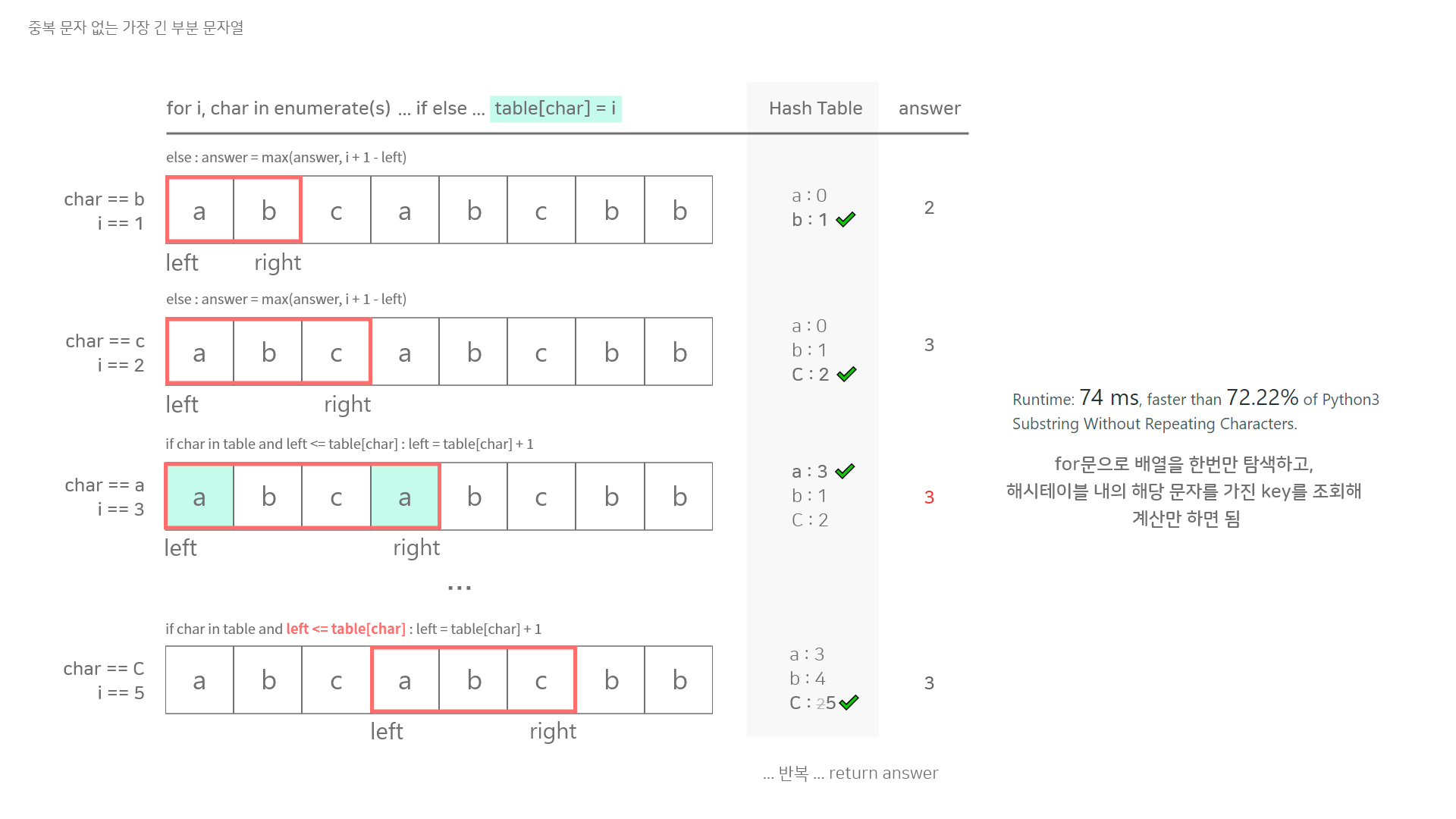
둘다 for문을 돌린다는 것은 마찬가지지만 성능은 3배 이상 개선된 것을 볼 수 있다.
이렇게 개선된 원인은 temp = s[left:i+1] 해당 코드에 있다고 생각한다.
기존 코드로 탐색했을 땐 중복 문자의 정확한 위치를 알수 없어 배열 선형검색 뿐만 아니라 중복문자가 left지점에서 멀 경우 해당 위치를 찾아 바로 건너뛸 수 없기 때문에 불필요한 과정이 훨씬 늘어난다.
내가 겪은 문제
해시테이블을 만드는 방법과 정의에 대해 듣고 나니 해당 문제에서 어떻게 테이블 구조를 짜서 index를 도출하고 key와 value를 지정하지 라는 생각이 앞서 원리는 파악해도 응용할 방법을 찾기가 쉽지 않았다.
하지만 배열에 있는 중복데이터의 수를 딕셔너리 타입으로 찾아내는 것 처럼, 이것또한 거기서 좀 더 응용되어 간단히 풀수 있는 문제였다. 그냥 파이썬의 딕셔너리가 해시테이블이라는 것만 이해하고 넘어가도 되었다....😭
가끔 알고리즘 문제를 너무 어렵게 생각해서 이미 거의 다 찾은 방법을 구현으로 풀어내지 못할 경우가 있다
이럴 경우 나에게 필요한 조건이 뭔지, 내가 왜 이렇게 하려고 하고있는 지에 대한 타당성을 다시 한번 정리해보는 시간을 갖는게 좋을 것 같다.
