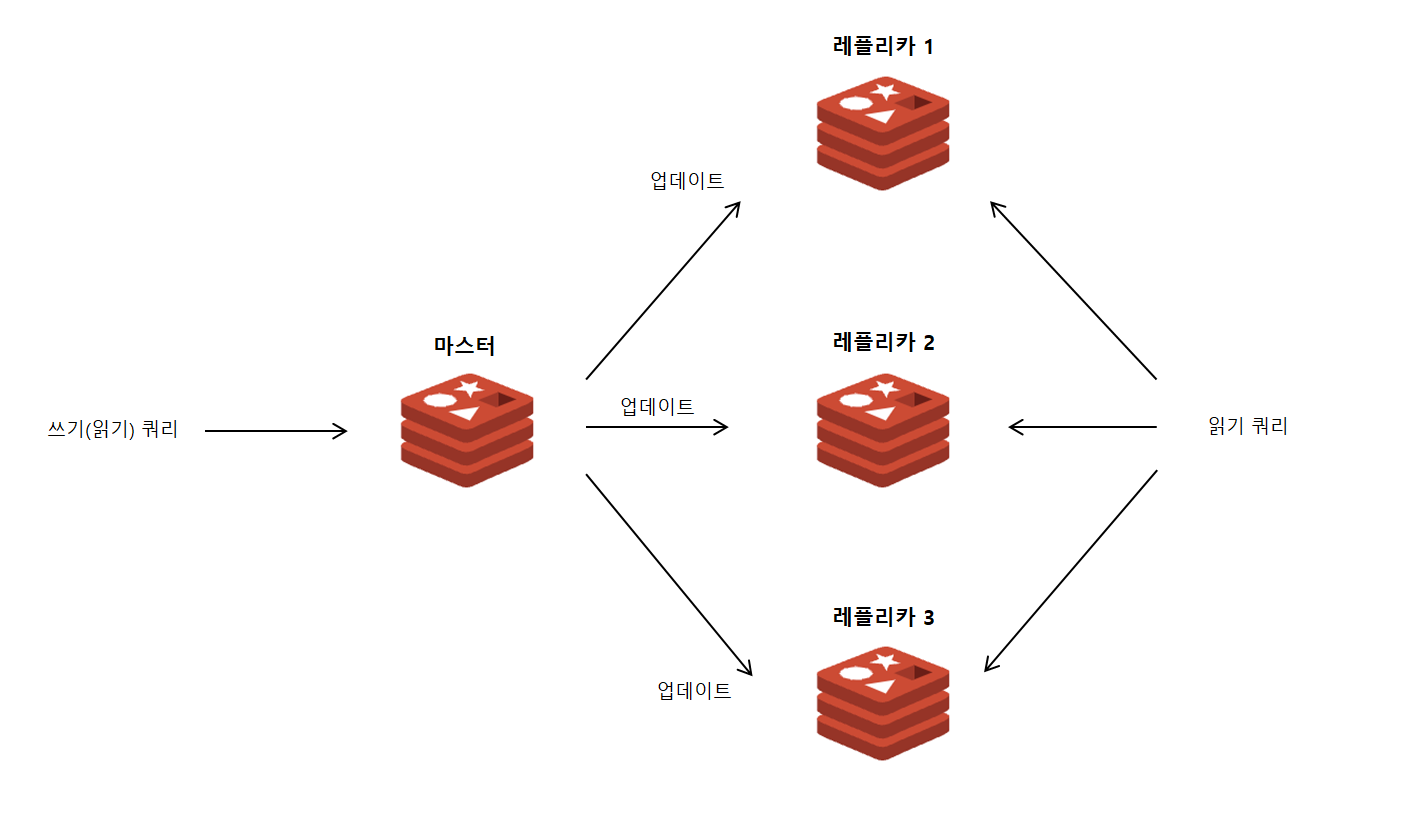
데이터 레플리케이션은 일반적으로 쓰기 작업이 있을 때마다 업데이트된 데이터를 다른 서버로 계속 보내 복제하는 것을 말합니다. 이러한 방식을 통해 서버를 추가하고 리소스를 확장하여 읽기 쿼리의 부하를 관리할 수 있으며, 데이터 중복성을 통한 Failover로 가용성을 얻을 수 있습니다.
레플리케이션 기능
비동기 처리를 통한 구현
레디스의 레플리케이션 이벤트 루프의 비동기 논블로킹 방식으로 구현되었습니다. 비동기 종작으로 인해 지연이 발생하는 경우, 마스터와 레플리카 내의 데이터가 동일하다고 보장할 수 없습니다. 즉, 마스터에 데이터를 저장한 직후 레플리카에 접근하면 데이터가 존재하지 않을 수도 있습니다.
레플리케이션을 사용할 때 레디스를 연결하는 방법
레플리케이션을 사용할 때는 각 캐시 노드의 IP 주소나 엔드포인트를 기록해두고, 레디스 클라이언트에서 직접 접근하거나 twemproxy와 같은 프록시를 활용해 여러 레플리카의 요청 라우팅 과정을 자동화할 수 있습니다.
ElastiCache를 사용하는 경우, 클러스터 모드가 비활성화 된 레디스 클러스터에선느 다음과 같은 엔드포인트를 사용할 수 있으므로 프록시 등을 직접 준비하고 관리하는 수고를 덜 수 있습니다.
마이그레이션으로 활용하기
다운 타임을 최소화하기 위해 레플리케이션 기능을 활용할 수 있습니다.
레플리케이션 주의사항
레플리케이션 작업을 실행할 때 마스터에 영속성이 설정되어 있지 않은 경우, 엔진을 재실행하거나 종료하면 데이터 세트가 초기화된 상태로 실행됩니다.
레플리케이션을 시작할 때의 메커니즘
- 레플리카는
PSYNC명령어로 마스터에 연결을 요청하며, 해당 시점까지 처리한 레플리케이션 ID와 오프셋을 전송- 마스터는 요청받은 마스터의 레플리케이션 ID와 자신의 레플리케이션 ID가 일치하는지 확인하고, 오프셋이 레플리케이션 백로그의 버퍼에 있는지 확인
- 요청 받은 오프셋이 레플리케이션 백로그에 있는지에 따라 처리가 달라짐
3-1. 레플리케이션 백로그에서 동기화가 가능한 경우 : 요청된 오프셋이 레플리케이션 백로그에 있고, 레플리케이션 백로그에서 동기화가 가능한 경우에는 부분된기화를 실행합니다.
3-2. 레플리케이션 백로그에서 동기화가 불가능한 경우 : 레플리케이션 중단 중에 마스터가 받은 쓰기 작업 요청의 크기가 버퍼 크기를 초과하여 부분 동기화가 불가능한 경우에는 전체 동기화를 실행
2가지로 분리된 이유는 전체 동기화가 처리에 미치는 영향이 크기 때문입니다. 레플리케이션은 가능한 부분 동기화를 실행하고 불가능하다면 전체 동기화가 수행됩니다.
전체 동기화
- 레플리카가 마스터에 레플리케이션 시작을 요청합니다.
- 마스터는
BGSAVE명렁어를 실행하여 프로세스를 포크 처리하고, 포크된 프로세스에서 메모리 스냅숏을 진행합니다.BGSAVE처리가 완료된 후, RDB 파일을 레플리카로 전송합니다. 그동안 마스터의 쓰기 작업은 레플리카의 클라이언트 출력 버퍼에 기록됩니다. 레플리카는 전송된 RDB 파일을 메모리로 불러옵니다.- 레플리카의 클라이언트 출력 버퍼에 쓰기 작업이 완료되면, 마스터의 쓰기 작업은 실시간으로 레플리카로 계속해서 전송됩니다.
전체 동기화를 시작할 때의 세부사항
- 레플리카에 이미 RDB 파일이 있다면 데이터의 일관성을 위해 레플리카에 있는 파일은 삭제됩니다.
- 마스터로 RDB를 수신 받는 동안, 클라이언트의 요청이 온다면 기본적으로 응답하게 되어 있습니다.
- 이전 데이터가 반환되거나 빈 값이 반환될 수 있습니다.
replica-serve-stale-data값을 수정하여 응답대신 SYNC with master in progress 오류 메시지로 응답합니다.
여러 개의 레플리카가 있을 때의 동작
- 첫 번째의 레플리카의
BGSAVE완료 전 두 번째의 레플리카 동기화 요청할 경우 첫 번째와 동일한 내용으로 복제됩니다.BGSAVE완료 이후 요청하면 전체 동기화 과정이 처음부터 다시 시작합니다.
레플리케이션 연결이 끊길 때의 동작
클라이언트 출력 버퍼가 초과되면 연결이 끊어지고 재동기화를 시도하게 됩니다.
TTL이 설정된 키의 레플리케이션 동작
레플리카에서는 TTL이 설정된 키를 자체적으로 만료시키지 않으며, 만료된 키의 정보는 마스터에서 모든 레플리카로 DEL명령어를 통해 전송됩니다. RDB 파일을 덤프할 때 만료된 키는 포함되지 않으므로 레플리카에서 복원되지 않습니다.
디스크 없는 레플리케이션
디스크 없는 레플리케이션에서는 프로세스가 포크된 후, RDB 파일을 직접 소켓으로 전송합니다. repl-diskless-sync를 yes로 변경하여 기능을 활성화할 수 있습니다.
레플리케이션을 시작하면, 이후에 추가되는 레플리카는 선행 작업이 완료될 때까지 기다려야합니다.
디스크 없는 레플리케이션은 큰 데이터 세트를 처리하는 경우나 디스크 속도가 느리고 네트워크 대역폭이 넓은 경우에 특히 유용하다.
그 외 레플리케이션 최적화를 위한 확인 사항
TCP_NODELAY 설정이 있습니다. 활성화 하면 지연 시간은 감소하지만 사용하는 대역폭이 증가합니다. 기본 설정은 낮은 지연 시간을 우선시하기 때문에 활성화되어 있습니다.
비활성화하면, 더 적은 TCP 패킷으로 레플리카에 데이터를 전송하므로 필요한 대역폭을 줄일 수 있지만 레플리케이션 지연 시간이 증가합니다.
부분 동기화
레플리케이션 연결이 끊어진 동안의 모든 쓰기 작업이 레플리케이션 백로그에서 레플리카로 전송됩니다.
백로그의 크기는 repl-backlog-size로 설정할 수 있으며, 기본값은 1MB 입니다. 만약 초과하면 레플리카의 PSYNC 요청에서 오프셋이 백로그에 포함되지 않기 때문에 전체 동기화를 시작하게 됩니다.
동기식 강제하기
레플리케이션은 기본적으로 비동기 방식입니다. 그러나 동기식으로 수행하려면 WAIT 명령어를 사용합니다.
데이터 손실에 대한 안전성을 높일 수 있으며, 특히 Failover 도중에 쓰기 작업을 받은 레플리카를 새로운 마스터로 효율적으로 승격시킬 수 있습니다. WAIT 명령어는 클라이언트가 지정한 개수만큼의 레플리카로부터 응답을 받을 때까지 현재 클라이언트를 차단하도록 동작합니다.
레플리케이션 동작 중 매커니즘
연결 상태 모니터링
마스터는 기본적으로 10초 간격으로 모든 레플리카에 ping을 보냅니다. repl-ping-replica-period 로 조절할 수 있습니다. 레플리카는 매초 REPLCONF ACK <offset> 명령어를 사용하여 처리한 위치를 포함한 ping을 보내고, 마스터는 각 레플리카로부터 받은 마지막 핑의 시작을 기록합니다.
Failover
레디스는 기본적으로 마스터에 문제가 발생했을 때 자동으로 failover하는 기능이 기본적으로 없습니다. 따라서 마스터가 다운되었을 경우, 새로운 마스터로 승격시킬 노드에서 REPLICAOF NO ONE 명령어를 수동으로 실행해야 합니다.
레디스 클러스터나 레디스 센티널을 사용하면 자동 failover기능을 사용할 수 있습니다. failover 중에는 CLIENT PAUSE 명령어를 사용하여 클라이언트의 접근을 일시적으로 중단함으로써 클라이언트의 쓰기 작업이 새로운 마스터로 향하게 할 수도 있습니다.
