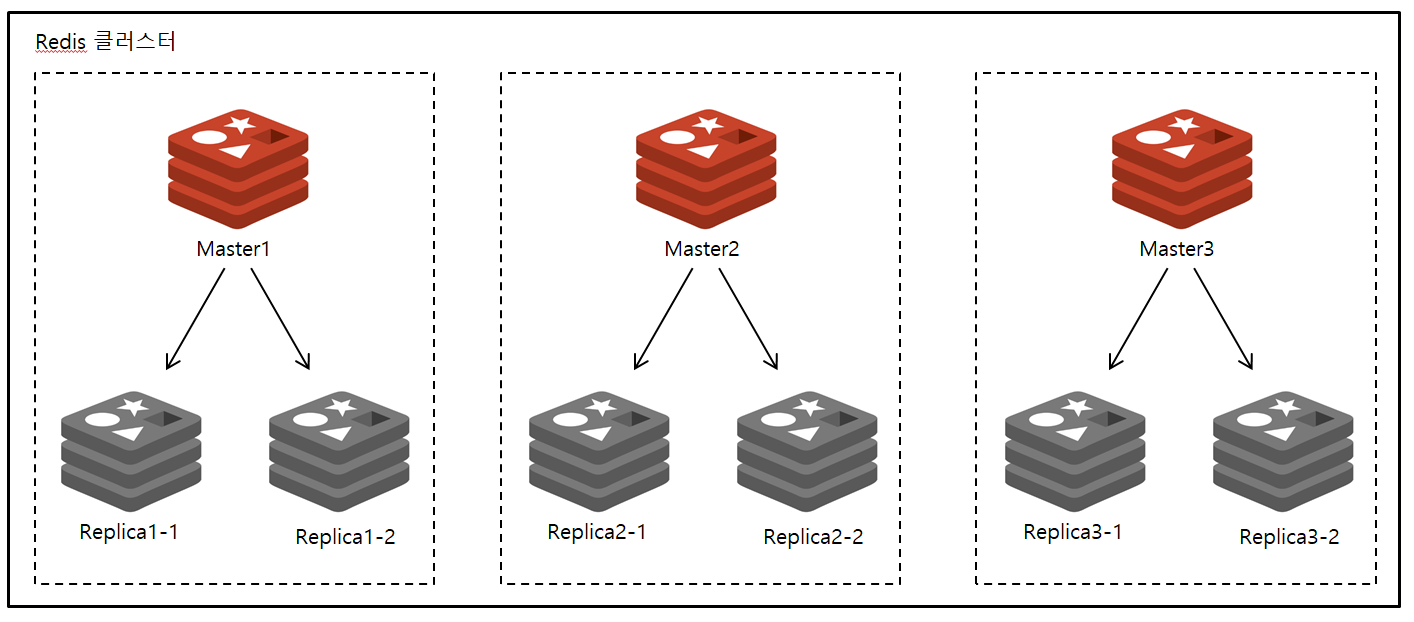
레디스 클러스터 기능 개요
레디스 클러스터는 여러 캐시 노드를 연결하여, 일부 장애가 발생해도 시스템을 계속 운영할 수 있도록 페일오버 기능을 지원합니다. 또한 샤딩을 통해 레디스 서버가 실행 중일 때 노드 사이에 키를 옮길 수 있습니다.
레디스 클러스터의 장점
Replicaion을 사용할 때는 마스터의 Replica 수를 늘려서 읽기 작업의 확장성을 높일 수 있었지만, 쓰기 작업은 기본적으로 마스터에서만 수행되기 떄문에 레플리카 수를 늘리는 방식으로는 확장성을 높이기 어렵습니다. 이를 해결하귀 위한 방법으로 레디스 클러스터는 샤딩을 제공합니다.
레디스 클러스터는 클라이언트 요청에 대해 클러스터 내 각 노드로 요청을 분배하는 과정에서 프록시를 사용하지 않으므로 프록시로 인한 오버헤드가 없습니다. 만약 데이터를 갖고 있지 않은 노드에 요청이 들어올 경우, 레디스 클러스터는 클라이언트에게 데이터를 가진 마스터 노드의 정보를 제공하고, 해당 노드로 요청을 리다이렉트 합니다. 이 과정에서 얻은 정보를 클라이언트가 저장하고 있다면, 다음 요청부터는 리다이렉트에 의한 오버헤드도 없앨 수 있습니다.
두 개의 TCP 포트
레디스 클러스터를 연결하기 위해서는 두 개의 TCP 포트를 사용합니다. 첫 번째 포트는 클라이언트로부터의 TCP 연결을 받는 포트로, 기본값은 6379 입니다. 두 번째 포트는 클러스터 내부 통신을 위한 포트로, 기본 값에 +10,000을 더한값을 사용합니다 (16379) 두 번쨰 포트를 클러스터 버스 포트라고 합니다.
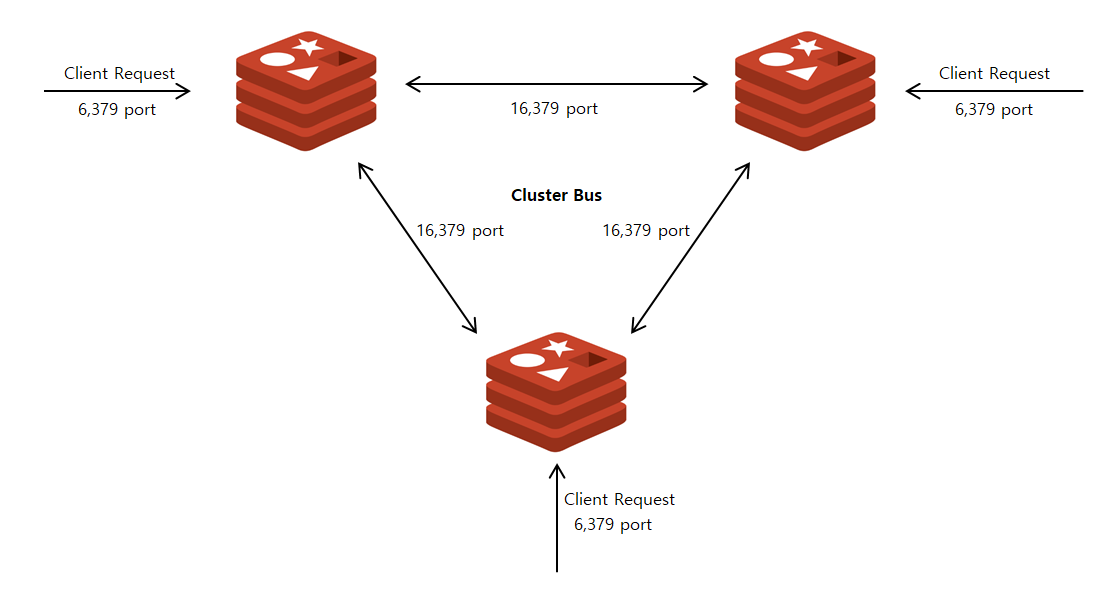
각 노드는 클러스터 버스를 통해 다른 모든 노드와 연결됩니다. 통신에는 이진 프로토콜이 사용됩니다. 노드는 Full Mesh구조로 구성되며, 노드 간에는 구성 정보, 상태와 같은 정보들을 교환합니다. 또한 Failover 인증, 설정 업데이트 등에 사용되는 하트비트 패킷 교환도 이뤄집니다. 이와 같은 통신 방식은 Gosship protocol을 통해 이뤄지는데, 이 프로토콜은 클러스터의 노드 수가 증가해도, 노드 간 메시지 수가 지수적으로 증가하지 않도록 고안되었습니다. 내부적으로 설정 정보를 공유하고 인지하기 위해 Raft라는 분산 합의 알고리즘으로 구현되어 있습니다.
동작 메커니즘
레디스 클러스터에서 클라이언트의 요청 처리는 다음과 같은 흐름으로 진행됩니다.
- 클라이언트가 클러스터를 구성하는 캐시 노드 중 하나의 IP 주소에 접속합니다.
- 접근 노드의 레플리카 마스터인 경우 다음과 같은 내용에 따라 조건 분기
- 접근 노드가 레플리카인 경우
- 읽기 쿼리 : 클라이언트 설정에 따라
READONLY명령어 실행 여부에 따라 동작
READONLY명령어가 실행되었고, 해당 키가 노드의 슬롯 범위 내에 있는 경우
- 요청된 캐시 노드에서 요청을 처리
- 그 외 경우
- 레디스 서버가
MOVED리다이렉트를 클라이언트에 응답합니다.- 클라이언트가
MOVED리다이렉트를 받고 로컬 슬롯 매핑을 업데이트합니다.- 클라이언트가 해당 키의 슬롯을 가진 샤드의 마스터에 접근합니다.
- 쓰기 쿼리
- 레디스 서버가
MOVED리다이렉트를 클라이언트에 응답합니다.- 클라이언트가
MOVED리다이렉트를 받고 로컬 슬롯 매핑을 업데이트합니다.- 클라이언트 해당 키의 슬롯을 가진 샤드의 마스터에 접근합니다.
- 접근 노드가 마스터인 경우
- 키가 해당 캐시 노드의 슬롯 범위 내인 경우
- 요청된 마스터에서 처리합니다.
- 키가 해당 캐시 노드의 슬롯 범위 밖인 경우
- 레디스 서버가
MOVED리다이렉트를 클라이언트에 응답합니다.- 클라이언트가
MOVED리다이렉트를 받고 로컬 슬롯 매핑을 업데이트합니다.- 클라이언트 해당 키의 슬롯을 가진 샤드의 마스터에 접근합니다.
IP 주소의 순서는 클라이언트가 사용하는 DNS Resolver의 이름을 어떻게 해석하느냐에 따라 달라질 수 있으며, 이 결과에 따라 접근할 노드가 결정됩니다.
클러스터 장애 탐지
레디스 클러스터는 문제가 발생한 마스터가 속한 샤드 내의 레플리카를 마스터로 승격시키도록 동작합니다. 장애 탐지 기능은 이 동작의 수행 시점을 결정합니다.
장애 탐지 메커니즘
클러스터의 각 캐시 노드의 상태는 PFAIL, FAIL 두 가지로 나타낼 수 있습니다. 클러스터는 Gosship protocol을 사용 하여 주기적으로 핑을 보내게 되는데 이떄 포함된 내용에는 다른 노드에 다른 노드의 상태 정보를 담고 있는 Gosship Section이 있습니다. 다른 노드의 상태 정보를 공유하는 형태로 상태를 파악합니다.
- PFAIL
- Possible Failure의 약자
- 특정 노드가 다른 노드에 핑을 보내고,
cluster-node-timeout이내 응답이 오지 않을 때, PFAIL로 표시 cluster-node-timeout/ 2 만큼 시간이 지나도 핑의 응답이 오지 않으면 연결을 다시 시도- 마스터 노드가 PFAIL 상태일 때는 Failover를 실행할 수 없습니다.
- FAIL
- FAIL 상태가 되어야 마스터의 Failover를 실행할 수 있습니다.
- PFAIL에서 다음 조건에 따라 FAIL 상태로 변환
- 과반수의 마스터 노드가 대상 노드를 PFAIL 혹은 FAIL 상태로 판단하는 경우
- 판단에 걸리는 시간
cluster-node-timeout*cluster-replica-validity-factor로 계산
cluster-replica-validity-facotr 0으로 설정되어 있으면, master <-> replica의 연결이 끊어진 시간과 관계없이 Failover가 실행됩니다.
장애가 발생한 동안 샤드 내에서 마스터가 2 개로 나뉜 상황을 가정합니다 .장애 복구 과정에서 각 마스터에 저장된 데이털르 병합할때는 last failover wins방식을 사용하여 마스터를 퐇ㅁ하는 레플리카가 새로운 마스털 승격되며 승격되지 않은 다른 마스터의 기록은 손실됩니다.
레플리카 선출
마스터가 정상적으로 동작하지 않으면 레플리카는 자동적으로 새로운 마스터로 Failover를 실행합니다.
다음 조건들을 만족하는 레플리카 마스터 후보가 되면 선출 프로세스가 시작 됩니다.
- 레플리카 마스터가 FAIL 상태
- 마스터가 하나 이상인 슬롯을 관리
- 레플리카가 일정 시간 이상 마스터와 연결이 끊긴 상태
선출하는 과정은 다음과 같습니다.
- 마스터가
FAIL상태임을 감지한 레플리카는 일정 시간 동안 대기한 후, 클러스터 내의 각 마스터에게FAILOVER_AUTH_REQUEST패킷을 브로드캐스트 합니다.
이때cluster-node-timeout* 2의 시간만큼 대기합니다. - 각 마스터는 해당 패킷을 받으면
FAILOVER_QUTH_ACK로 응답합니다.
cluster-node-timeout* 2의 시간 동안 다른 레플리카로부터의 패킷에는 응답하지 않습니다. 마스터는 각 에포크마다 한 번만 투표할 수 있으며, 마스터가 가진lastVoteEpoch보다 오래된currentEpoch의 투표는 반영하지 않습니다. - 레플리카는
currentEpoch이하의 에포크 응답을 무시하고, 그렇지 않은 경우에는 반영합니다.
과반수의 마스터로부터 투표를 받으면, 해당 레플리카가 승격 대상으로 Failover가 실행 됩니다. 과반수에 도달하지 못하면cluster-node-timeout2 대기한 후,cluster-node-timeout4의 시간 후에 재투표를 진행합니다. - 새로운 마스터가 된 노드는 다른 마스터보다 더 크게
configEpoch를 증가시킵니다.
레플리카의 딜레이 시간은 마스터가 FAIL 상태임을 감지한 후, 500밀리 초 동안 기다린 후 각 마스터에게 투표 요청을 보냅니다.
DELAY= 500ms + 무작위 지연(0~500ms) +REPLICA_RANK* 1000ms
마스터가FAIL상태를 전파하기 위한 500ms
동시 선출을 피하기위한 무작위 지연
RANK는 레플리케이션 진행 상황이 빠른 순서대로 번호
클러스터 키워드
슬롯
레디스 클러스터는 각 샤드마다 하나의 마스터와 0개 이상의 레플리카를 가지며, 총 16,384개의 슬롯이 갹 샤드에 분배됩니다. 클러스터에 저장되는 키는 CRC16 해시 함수를 사용하여 해시값을 계산합니다. 그 값을 16384로 나눈 나머지를 구한 다음, 해당 값의 슬롯을 가진 샤드는 요청을 처리하게 됩니다.
HASH_SLOT = CRC16(key) mod 16384
이 과정은 슬롯의 개수를 기준으로 하며, 데이터 크기는 고려하지 않습니다.
해시테그
레디스 클러스터는 데이터의 일관성과 높은 성능을 제공하기 위해 MSET과 같이 여러 키를 동시에 조작하는 명령어나 이페머럴 스키립트를 실행할 때 모든 키가 동일한 슬롯에 있어야 합니다. 만약 다른 슬롯에 있는 키에 접근 하려고 하면 CROSSSLOT 오휴가 발생합니다.
동시에 여러 키를 조작할 때 키가 존재하지 않거나 혹은 리샤딩 중이어서 원본 노드와 목적지 노드의 데이터가 일시적으로 분리된 경우에 TRYAGAIN 오류를 반환합니다.
데이터를 저장할 때는 해시태그 기능을 사용하며, 키가 달라도 같은 슬롯에 접근할 수 있게 됩니다. 해시태그를 사용하기 위해서는 키 내의 공통 문자열을 {} 로 감싸야 합니다. 또한 해시태그로 인식되려면 다음과 같은 조건을 충족해야 합니다. 만약 이 조건을 만족하는 대상이 여러 개 있을 경우에는 갖아 먼저 조건을 만족하는 것이 대상이 됩니다.
- 키에 {을 포함해야 합니다
- { 의 오른쪽에 }을 포함해야 합니다.
- {} 사이에 하나 이상의 문자가 포함돼야 합니다.
클러스터 버스
레디스 클러스터 내의 각 노드는 클러스터 버스라고 하는 TCP 버스를 통해 이진 프로토콜과 완전 메시 구조로 서로 연결되어 있습니다.
각 노드는 상대 노드로 핑을 보내고 응답을 받아 해당 노드가 정상으로 작동 중인지 확인합니다. 단, 클러스터 내의 각 노드가 서로 연결되어 있어도 모든 노드 쌍에 핑을 주고 받은 완전 메시 방식을 사용하지는 않습니다. 그 이유는 노드 수가 늘어날수록 보내야 하는 핑의 양이 급격히 늘어나 클러스터 성능이나 네트워크 대역폭에 영향을 미칠 수 있기 때문입니다.
일반적으로 각 노드는 다른 노드를 무작위로 선택하여 핑을 보내고 응답을 받습니다. 이 과정에서 각 노드가 보내는 전체 팽 패킷의 총량은 일정하도록 유지합니다. 만약 cluster-node-timeout 설정 시간의 절반을 초과하는 동안 다음 조건 중 하나라도 만족하는 노드가 있을 경우, 해당하는 모든 노드에 핑을 보내도록 설정되어 있습니다.
- ping이 전송되지 않은 노드
- ping의 응답을 받지 못한 노드
클러스터에 속하지 않은 노드에서 온 핑 메시지라도 수신되면 응답을 반환하지만, 클러스터 외부 노드에서 오는 패킷은 폐기됩니다. 노드가 클러스터의 일부로 인식되는 과정은 다음과 같은 방법으로 이뤄집니다.
- MEET 메시지
CLUSTER MEET [ip] [port]명령을 보내면, 해당 명령을 받은 노드는 대상 노드를 클러스터의 일부로 인식합니다.
- Gosship 프로토콜
- 노드 A가 다른 노드 B에 대해 노드 B가 알지 못하는 클러스터 내 다른 노드 정보를 가지고 있을 때, 노드 A에서 노드 B로 보내는 가십 메시지를 통해 노드 B도 해당 노드를 인식하게 됩니다.
노드 사이의 슬롯 배치는 다음 두 종류의 메시지로 관리되며, 메시지를 통해 슬롯 구성이 업데이트 됩니다.
- 하트비트 메시지
- UPDATE 메시지
파티셔닝
파티셔닝은 여러 레디스 인스턴스 간에 데이터 세트를 분할하여 저장하는 작업입니다.
파티셔닝은 키를 분리하는 방식에 따라 레인지 파티셔닝과 해시 파티셔닝 등으로 구분할 수 있습니다.
파티셔닝의 실행 방법에는 다음과 같은 방법이 있습니다.
- 클라이언 측 파티셔닝
어느 노드로 요청을 보낼지 클라이언트에서 결정하는 방식입니다. 각 슬롯과 슬롯별 캐시 노드의 매핑 정보를 보관하는 방식으로 구현 - 프록시 기반 파티셔닝
클라이언트에서 직접 노드로 요청을 보내는 대신 프록시가 클라이언트로부터의 요청을 받아 대상 노드로 라우팅합니다. - 쿼리 파운딩
클라이언트의 요청을 받았을 때 처음에는 무작위 노드로 보내고, 그 노드가 요청을 처리하기에 적합하지 않으면 대상 노드로 요청을 리다이렉트하는 형식의 라우팅입니다.
클러스터 관련 명령어
| 명령어 | 설명 |
|---|---|
| CLUSTER INFO | 클러스터 상태를 확인한다. |
| CLUSTER NODES | 클러스터에 참가하고 있는 노드 상태를 확인한다. |
| CLUSTER REPLICAS | (레디스 5.0.0 이후) 마스터와 연결 중인 레플리카 상태를 확인한다. |
| CLUSTER SLAVES | CLUSTER REPLICAS 명령어와 동일하다. |
| CLUSTER SHARDS | 클러스터 각 샤드에 할당된 슬롯 범위. 샤드를 구성한 마스터 레플리카 IP 주소 및 노드 ID 등 노드 정보를 확인한다. |
| CLUSTER COUNTKEYSINSLOT | 지정한 해시 슬롯 번호에 저장되어 있는 키개수를 확인한다. |
| CLUSTER GETKEYSINSLOT | 지정한 해시 슬롯 번호에 저장되어 있는 키를 확인한다. |
| CLUSTER KEYSLOT | 지정한 키의 해시 슬롯 번호를 확인한다. |
| CLUSTER COUNT_FAILURE REPORTS | FAIL 및 PFAIL 개수를 확인한다. |
| CLUSTER MYID | 노드 ID를 확인한다. |
| READONLY | 레플리카로 연결 시 읽기 쿼리를 실행한다. 동작 키 슬롯을 지닌 마스터로 리다이렉트를 처리하는 게 기본 이다. |
| READWRITE | 기본 동작으로 키 슬롯을 가진 마스터로 리다이렉트를 처리한다. READONLY 명령어 실행 시 해제한다. |
| CLUSTER MEET | 클러스터에 캐시 노드 참가를 요청한다. |
| CLUSTER FORGET | 클러스터에서 캐시 노드를 제외한다. |
| CLUSTER REPLICATE | 캐시 노드를 지정한 마스터 레플리카가 되도록 설정한다. |
| CLUSTER ADDSLOTS | 마스터에 슬롯을 할당한다. |
| CLUSTER ADDSLOTSRANGE | 마스터에 슬롯을 할당한다. |
| CLUSTER DELSLOTS | 마스터에서 슬롯을 해제한다 |
| CLUSTER DELSLOTRANGE | 마스터에서 슬롯을 해제한다. |
| CLUSTER FLUSHSLOTS | 데이터베이스가 비었을 때 모든 슬롯 정보를 삭제한다. |
| CLUSTER SETSLOT | 해시 슬롯 상태를 변경한다. 리샤딩에 사용한다. |
| CLUSTER FAILOVER [FORCE | TAKEOVER] |
| CLUSTER SET-CONFIG-EPOCH | CurrentEpoch를 지정한 값으로 설정한다. |
| CLUSTER BUMPEPOCH | 값이 0 또는 클러스터 내 최대 에포크보다 작은 경우에 configEpoch 값을 증가시킨다. |
| CLUSTER RESET [HARD | SOFT] |
| CLUSTER SAVECONFIG | nodes.conf에 클러스터의 노드 상태를 저장한다. |
| CLUSTER LINKS | 클러스터 버스의 캐시 노드와 다른 노드의 연결 상태를 확인한다. |
| ASKING | 클라이언트가 명령어 실행 타킷을 ASK 리다이렉트할 때 사용한다. |
