분산 처리를 위한 Cluster 방식?
Computer Cluster는 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합을 말한다
그러면 Quartz에서 나눠진 시스템을 하나로 동작하게 하는 방법은 무엇일까?
그것은 스케줄링 시스템을 DB화 하는 것이다.
기존에 사용하던 방식은 Memory 에 스케줄이 담겨있습니다.
즉, 같은 소스로 여러 서버에 구동 시 각각의 스케줄러가 동작하여 문제가 생길 수 있습니다.
이를 해결하기 위한 방식이 Cluster 입니다.
스케줄이 DB에 담겨져 있고, 각각 서버들은 DB에 저장된 정보로 동작하게됩니다.
한 서버가 먼저 스케줄을 선점하면 다른 서버는 해당 스케줄을 동작하지 않습니다.
여러 서버가 나눠서 스케줄을 실행하게 되고, 한개의 서버가 죽게 되더라고 다른 서버로 대체가 가능해 집니다.
DB in scheduler
Quartz ERD
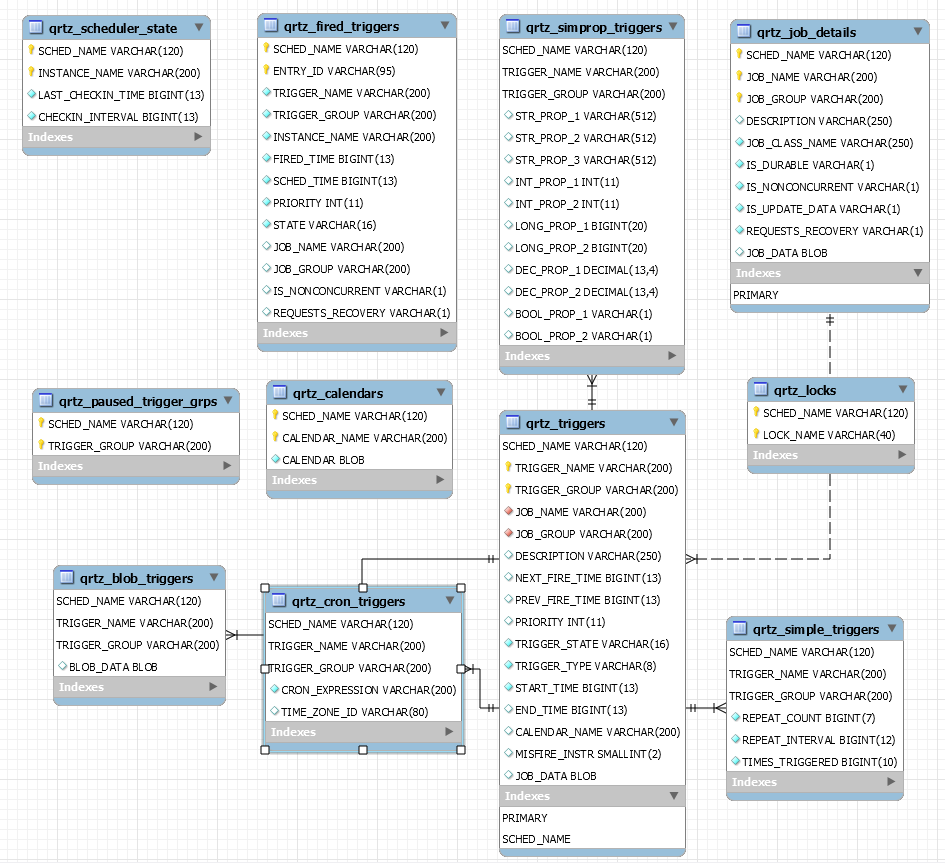
- QRTZ_JOB_DETAILS
- Job 정보를 담고 있는 테이블
- 이름, 그룹 및 옵션 정보와 JOB_DATA를 담고 있다.
- QRTZ_TRIGGERS
- Job을 실행할 스케줄 정보은 Trigger 테이블
- Job과 trigger는 1:N 관계이다
- Cron, Simple Type 정보
- 스케줄 정보를 담고있다 (시간 정보는 Epoch Time 으로 담겨있다)
- 이전 실행 시간
- 다음 실행 시간
- 종료 시간
- QRTZ_CRON_TRIGGERS
- Trigger Type이 Cron인 경우
- Cron Expression 이 담겨있다.
- Time Zone 설정이 담겨있다.
- QRTZ_SIMPLE_TRIGGERS
- Trigger Type이 Simple인 경우
- 반복 일정, 횟수 정보가 담겨 있다
- QRTZ_CALENDARS
- 달력 형태의 스케줄러 관리
- QRTZ_SIMPROP_TRIGGERS
- Simprop 형태의 Trigger 정보
- 필자도 사용을 하진 않아 어떤 데이터가 쌓이는지 모르겠음
- QRTZ_BLOB_TRIGGERS
- 필자도 사용을 하진 않아 어떤 데이터가 쌓이는지 모르겠음
- QRTZ_LOCKS
- QRTZ_SCHEDULER_STATE
- Cluster 사용 정보
- QRTZ_FIRED_TRIGGERS
- 실행중인 Trigger 정보
- QRTZ_PAUSED_TRIGGER_GRPS
- 활성되지 않은 트리거 정보
Batch ERD
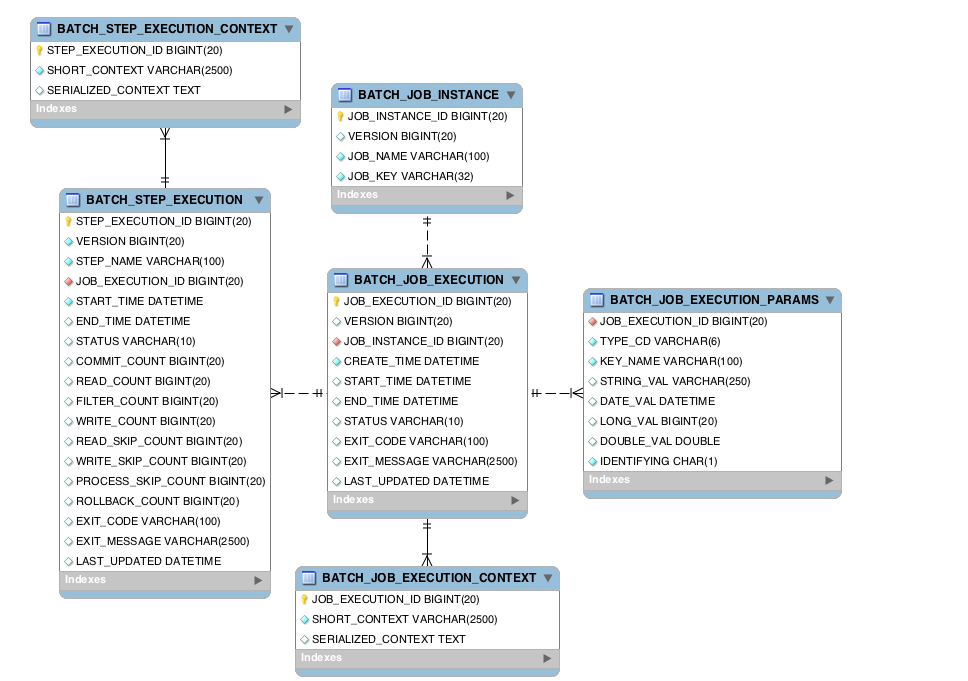
- BATCH_JOB_INSTANCE
Job실행 시 식별하는 고유의 정보로 등록JOB_INSTANCE_ID로 테이블 pk 생성
- BATCH_JOB_EXECUTION
JOB_INSTANCE_ID를 fk로 삼고 있는 테이블Job의 생성 시간, 시작 시간, 종료 시간 및 상태 값과 종료된 코드의 값을 확인할 수 있다.
- BATCH_JOB_EXECUTION_CONTEXT
- 작업에 필요한 작업 수준 데이터
- BATCH_JOB_EXECUTION_PARAMS
Job이 담고 있는 파라미터를 저장하고 있다
- BATCH_STEP_EXECUTION
JOB_EXCUTION_ID를 fk로 삼고 있는Step테이블Job아래Step이 실행에 대한 정보를 담고 있다.
- BATCH_STEP_EXECUTION_CONTEXT
- 작업에 필요한 작업 수준 데이터
위 스키마 테이블로 스케줄 정보와, JOB이 실행되면서 DB에 CRUD한 이력(read, commit 개수)을 확인 할 수 있습니다.
위 테이블을 좀더 활용을 한다면,
QRTZ 테이블을 이용해 QUARTZ ADMIN 페이지를 만들어 스케줄 수정이 가능하고, BATCH 테이블을 이용해 성공, 실패 이력을 확인할 수 있는 페이지를 만들거나 알림 기능을 추가할 수 있습니다.
Job, Trigger 등록
Job
@Bean public Job testJob() { return jobBuilderFactory .get("testJob") .incrementer(new RunIdIncrementer()) .start(testSetp()) .build(); }Job은 jobBuilderFactory를 통해 등록하게 됩니다.
incrementer
동일한Job Parameter인 경우 스케줄러 실행을 막고 있어, 중복을 피하기 위해 사용되고 있습니다.RunIdIncrementer()를 사용하여 RUN_ID 의 값을 순차적으로 올려주는 방식을 사용하면, JOB 실행 시 중복된 값을 피할 수 있습니다.private static String RUN_ID_KEY = "run.id"; private String key = RUN_ID_KEY; public JobParameters getNext(@Nullable JobParameters parameters) { JobParameters params = (parameters == null) ? new JobParameters() : parameters; JobParameter runIdParameter = params.getParameters().get(this.key); long id = 1; if (runIdParameter != null) { try { id = Long.parseLong(runIdParameter.getValue().toString()) + 1; } catch (NumberFormatException exception) { throw new IllegalArgumentException("Invalid value for parameter " + this.key, exception); } } return new JobParametersBuilder(params).addLong(this.key, id).toJobParameters(); }start()
실행될Step을 입력합니다.
Job아래 여러Step을 통해, 처리된 결과나 상태에 따라 다양한Step으로 처리가 가능합니다.
next(),from(),on(),to(),end()로 다음step을 결정합니다.
Step
@Bean @JobScope public Step testSetp() { return stepBuilderFactory .get("testSetp") .<testDomain, testDomain>chunk(100) .reader(testReader()) .processor(testProcessor()) .writer(testWriter()) .build(); }Step은 크게
tasklet과Chunk로 나눠집니다.
- Chunk?
<testDomain, testDomain>chunk(100)로 chunk 방식을 사용하게 됩니다. 괄호안 숫자는 처리될 개수를 뜻 하고 있습니다.
총 1000개의 데이터이고 Chunk단위가 100개이면 Reader -> Processor -> Writer을 총 10번 반복하게 됩니다. 또한 Chunk 단위로 Transaction이 묶입니다.
Reader는 DB에서 데이터를 읽고, Processor에서 데이터를 가공하고, Writer에서 가공한 데이터를 DB에 반영하게 됩니다.- tasklet?
tasklet(new testTasklet())로 tasklet 방식을 사용하게 됩니다.
Reader, Processor, Writer 단위로 나눠지지 않고, 단일 태스트로 구성되어 처리하게 됩니다.
JobDetail, Trigger
@Bean public JobDetail jobDetail() { //Set Job data map JobDataMap jobDataMap = new JobDataMap(); jobDataMap.put("jobName", "testJob"); return JobBuilder.newJob(CustomQuartzJobBean.class) // extends QuartzJobBean Class .withIdentity("testJob", null) // Job Name, Job Group (Key 등록) .setJobData(jobDataMap) .storeDurably() // 등록된 Trigger 없이 인스턴스 유지 .build(); } @Bean public Trigger jobTrigger() { CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0 * * * * ?"); return TriggerBuilder .newTrigger() .forJob(jobDetail().getKey()) .withIdentity("jobTrigger", null) .withSchedule(scheduleBuilder) .build(); }
JobDetail
- 실행할
Job이름을withIdentity()에 기입Trigger
- 실핼될
JobDetail을forJob()에 기입withIdentity()에Key등록withSchedule()에Cron,Simple기입서버 기동 시, 기입된
JobDetail과Trigger를 읽어 스키마 테이블에 등록처리가 된다.
initialize-schema옵션에 따라 달라질 수 있다.
저는 QUARTZ_ADMIN 페이지로 스키마 테이블에 등록하고 있습니다.
이제 Application 구동하면 정해진 시간에 시작되는걸 확인할 수 있습니다.
