📚 이제 머신러닝 학습 및 코드 실습 내용을 게시하려고 한다.
모든 실습 내용은 Jupyter notebook 에서 작성했으며 언어는 Python이다.
머신러닝이 뭘까?
내가 가진 데이터로 나 대신 학습하여 판단하는 것 👩🏻💻🤖🧑🏻💻
왜 그런 판단을 했는지 보이는 White Box 모델
📌 Iris Classification
Q) 꽃잎(petal), 꽃받침(sepal)의 길이/너비 정보를 이용해서 이 3종의 품종을 구분할 수 있을까?
필요한 import
import pandas
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris📚 데이터 관찰
# 데이터 불러오기 >> 변수명 등을 눈으로 확인한다
iris = load.iris()
# DataFrame으로 만들기
iris_pd = pd.DataFrame(iris.data, columns=iris.feature_names)
# 품종 정보도 column에 포함 >> 0, 1, 2의 값이 각 품종을 의미한다
iris_pd['species'] = iris.target👉 이제 시각화 해 확인해보자
# boxplot(x='sepal length (cm)')
plt.figure(figsize = (12,6))
sns.boxplot(x='sepal length (cm)', y='species', data=iris_pd, orient='h');
# boxplot(x='sepal width (cm)')
plt.figure(figsize = (12,6))
sns.boxplot(x='sepal width (cm)', y='sepcies', data=iris_pd, orient='h');
# boxplot(x='petal length (cm)')
plt.figure(figsize = (12,6))
sns.boxplot(x='petal length (cm)', y='sepcies', data=iris_pd, orient='h');
# boxplot(x='petal width (cm)')
plt.figure(figsize = (12,6))
sns.boxplot(x='petal width (cm)', y='sepcies', data=iris_pd, orient='h');
# pairplot
sns.pairplot(iris_pd, hue='species');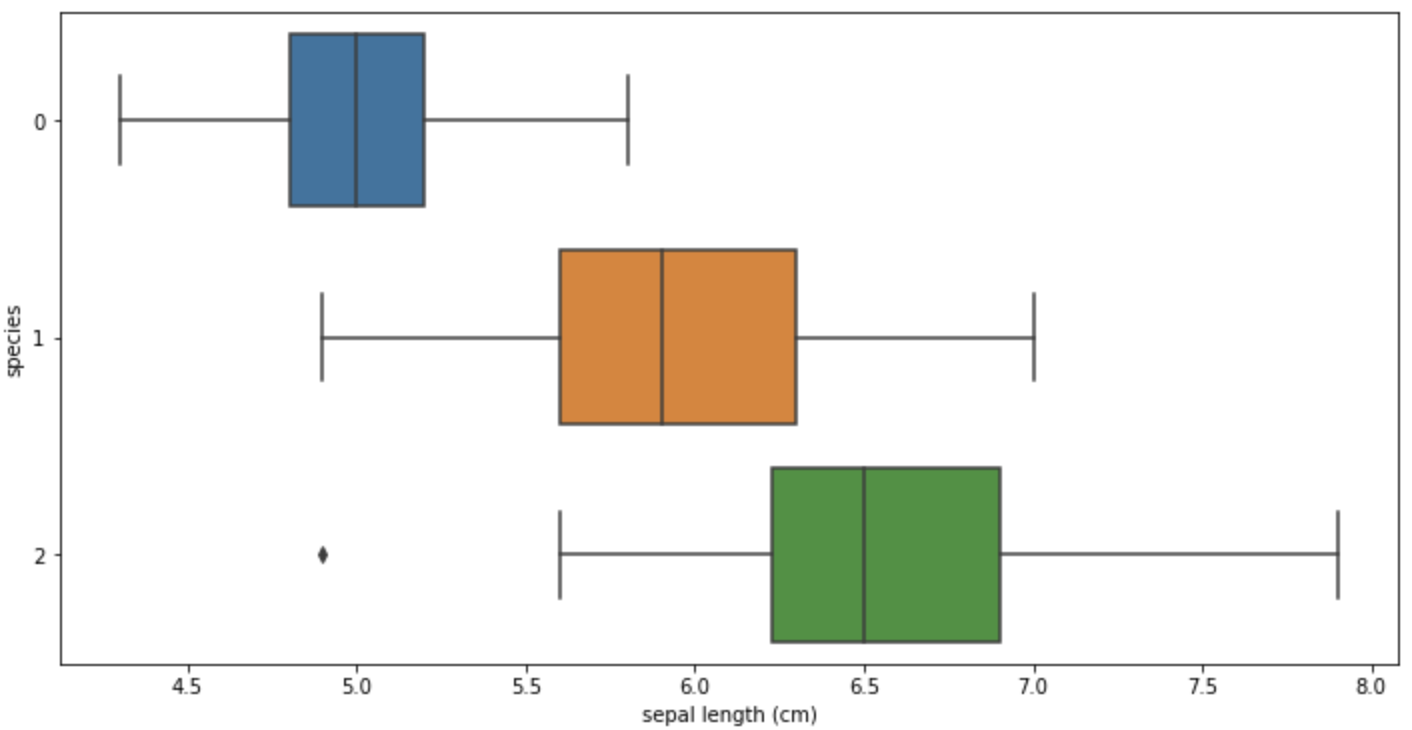
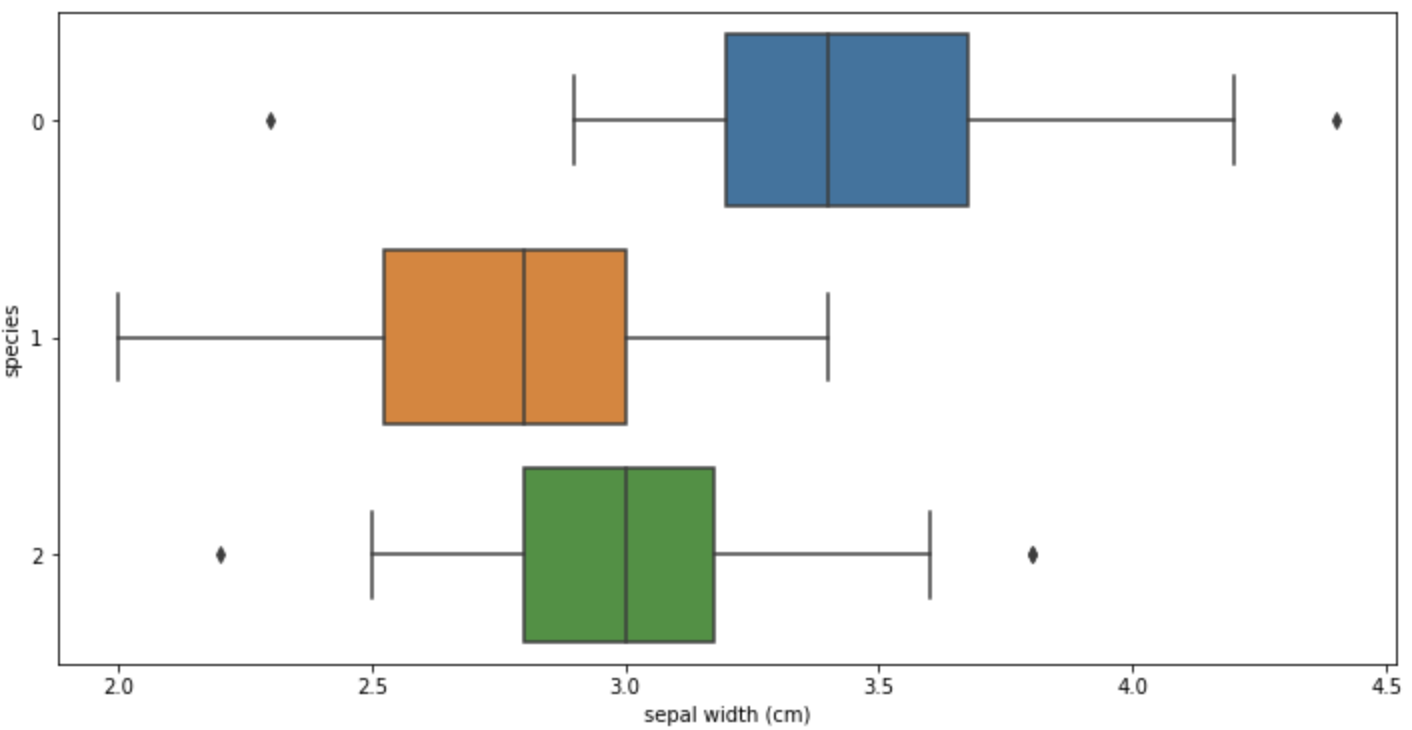
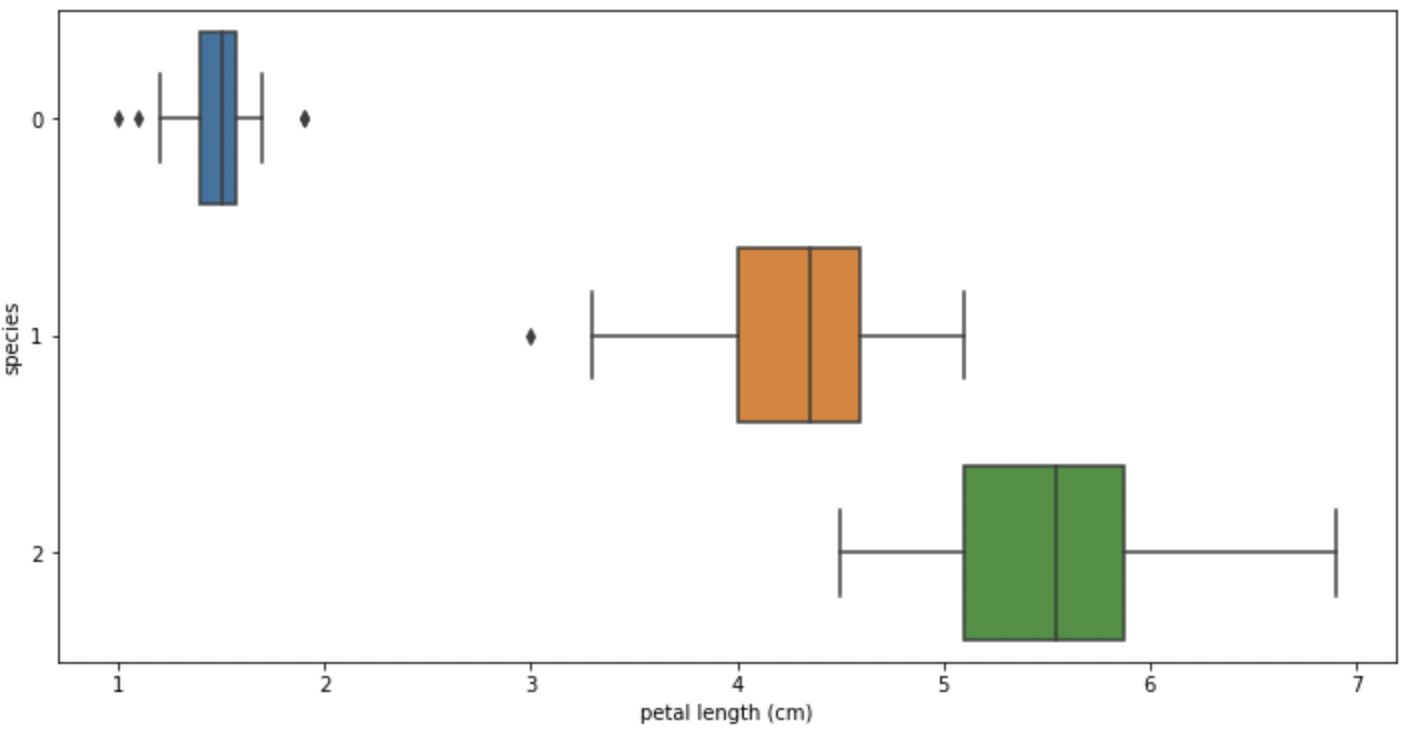
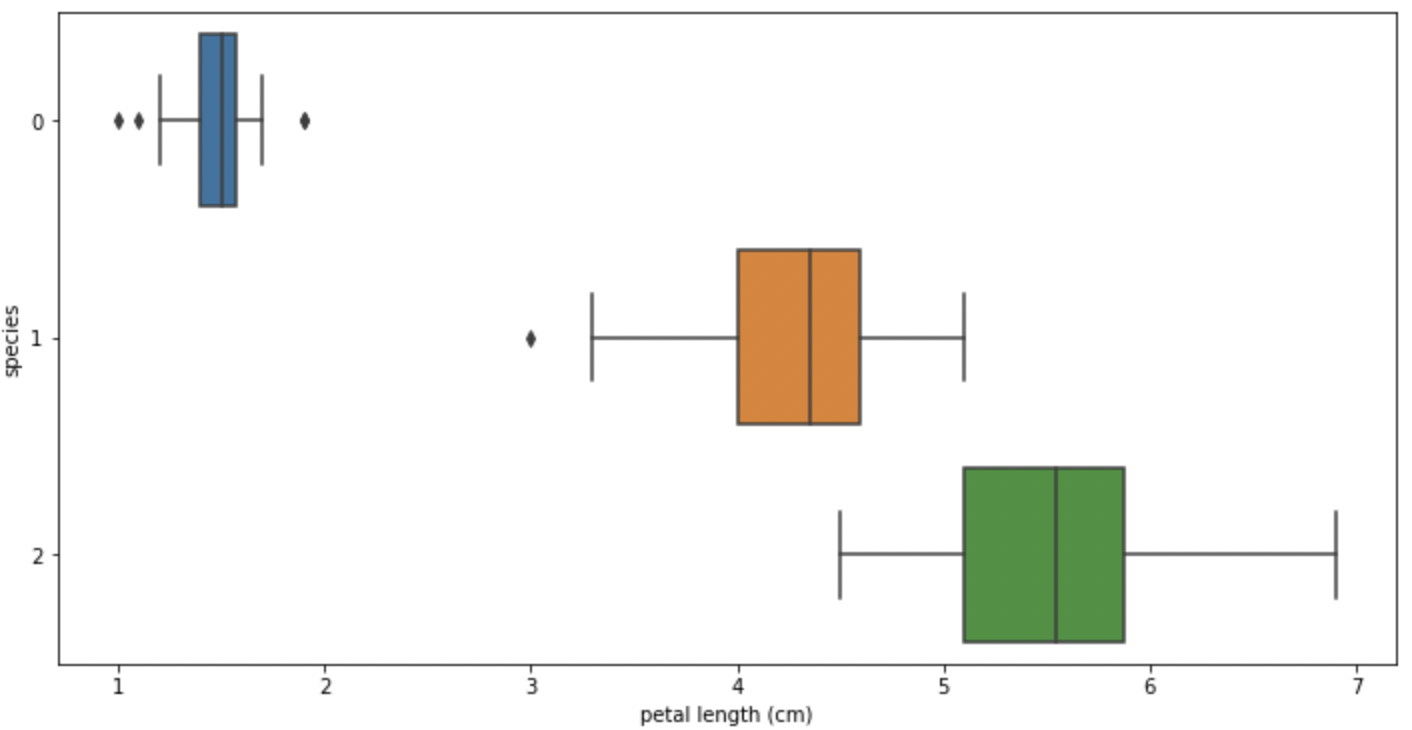
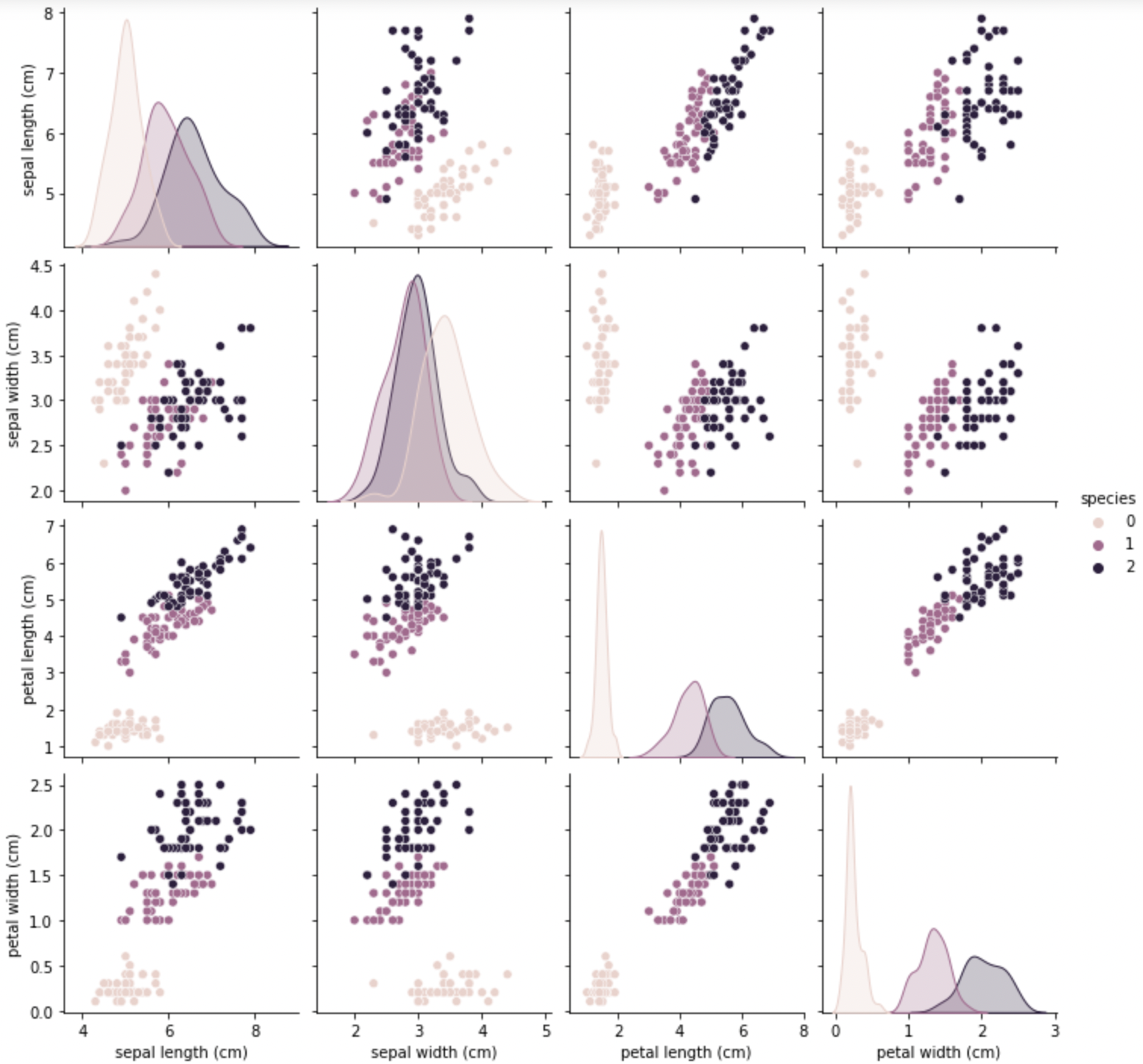
일단, sepal로는 겹쳐지는 데이터가 많아 경계를 만들기 어려워보인다.
그래서 petal을 집중적으로 다시 보자
sns.pairplot(data=iris_pd,
vars=['petal length (cm)', 'petal width (cm)'],
hue='species', height=4);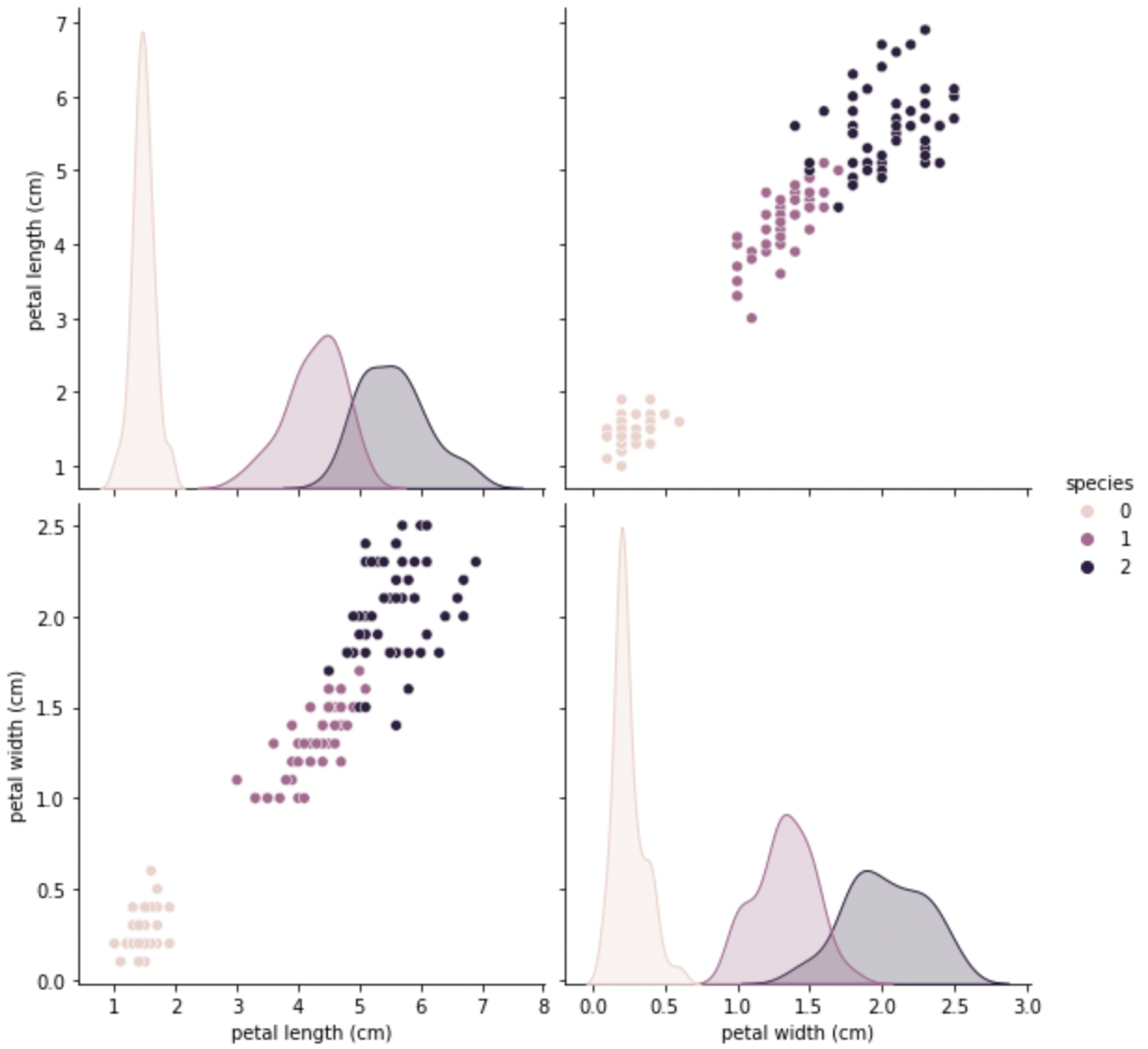
iris 3종에 대한 구분이 가능하게 산점도가 찍혀있다.
먼저, setosa는 육안으로 확인할 수 있을 정도로 명확히 구분되어 있다.
대략 Petal Length가 2.5보다 작다면 모두 setosa로 분류해도 된다.
그리고 versicolor는 petal length가 2.5보다 크면서 petal width가 1.6보다 작을 경우에 해당된다고 볼 수 있고,
verginica는 petal length가 2.5보디 크면서 petal width가 1.6보다 큰 경우에 해당된다.
하지만, 이게 최선이라고 말하기에는 근거가 충분하다고 할 수 없다.
💡 이때 알고리즘을 활용한다.
- 현재 상황에서 이것이 최선이라는 근거
- 어떠한 방법으로 각각 진행했을 때의 차이점에 대한 정량적 수치 제시
📚 Decision Tree
# 상황설정
plt.figure(figsize = (12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_pd, hue='species', palette='Set2');
첫번째 setosa 구분은 명확하니, 나머지 두 그룹을 잘 나누는 선을 어떻게 찾을까?
👉 학습을 위해 두 개의 데이터에 집중해보자
# 데이터 변경
iris_12 = iris_pd['species'] != 0]
plt.figure(figsize = (12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_12, hue='species', palette='Set2');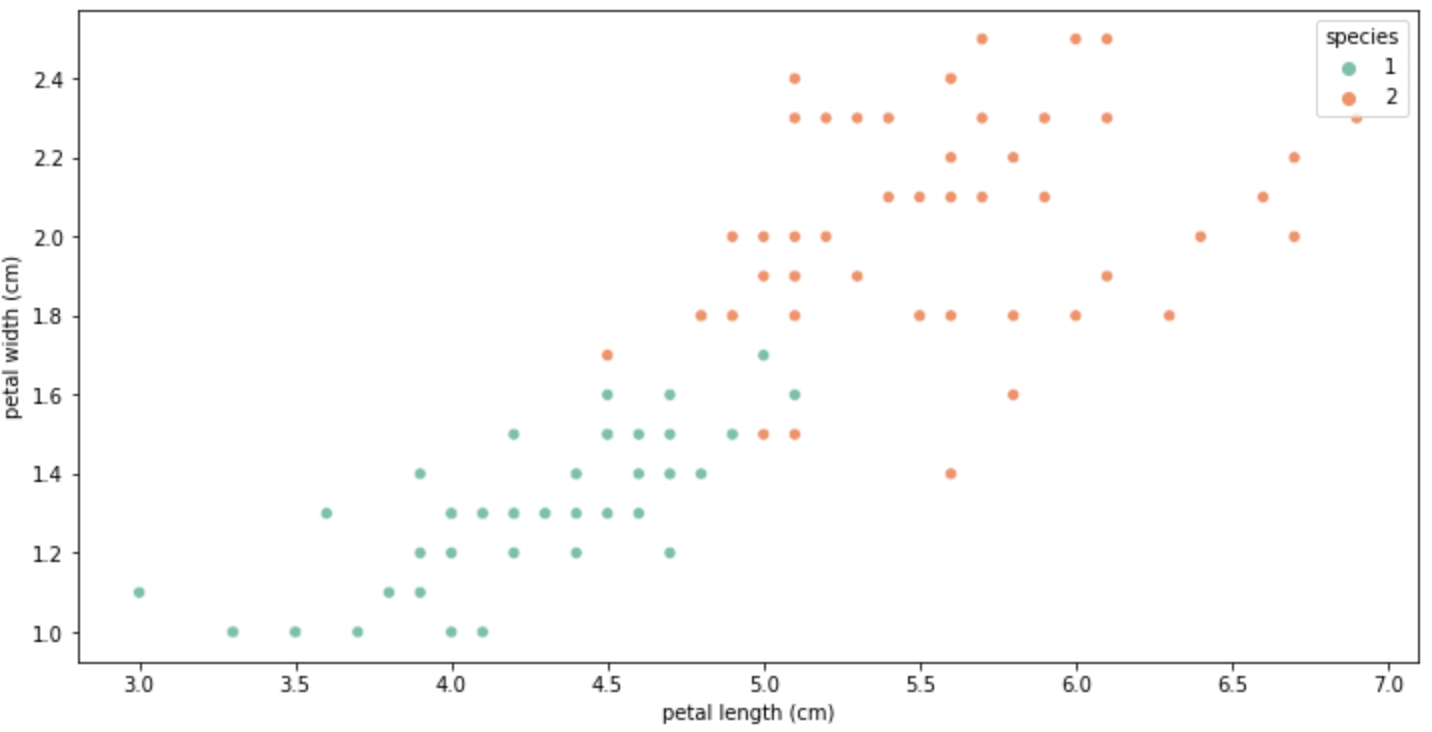
Q) 저 두 색의 산점도를 구분하는 선이 어디에 있으면 최고일까? 결정 트리의 분할 기준이 뭘까?
📚 Split Criterion
정보 이득
어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는 것
엔트로피
얼마만큼의 정보를 담고 있는가? 무질서도, 불확실성 >> 계산량이 많은 단점
지니계수
분순도율 >> 엔트로피와 비슷한 개념이면서 계산량이 적음
지니계수를 활용할건데,
width 값을 바꿔가며 계산하고 지니계수가 좋은(낮은) 지점을 찾아나가면 된다.
📚 scikit-learn Decision Tree
기존에는 위처럼 모두 계산했어야 했다.
하지만, 공개적인 frame work로 발전하기 시작했다.
그 중에 scikit-learn은 파이썬에서 가장 유명한 기계학습 오픈 소스 라이브러리이다.
이를 활용해 매우 간단하게 결정 나무를 만들어보자
💡 scikit-learn을 이용한 결정나무의 구현
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassfier()
iris_tree.fit(iris.data[:, 2:], iris.target)💡 Accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:, 2:])
accuracy_score(iris.target, y_pred_tr)