with python 3.8.12 & scikit-learn 1.0.1
📌 교차검증이란?
예를 들어 내가 만든 모델을 train, test data로 평가했을 때, accuracy가 72%, 71%가 되었다고 하자. 과연 이 값이 정말로 괜찮은 것이라고 할 수 있을까?
또 만약, trian data에서는 100%의 예측률을 갖고 있었는데, 새로운 test data를 적용하고 보니 전혀 도움되지 않는 예측 결과물을 내놓는다면 어떨까?
이 경우는 과적합(overfitting)에 해당된다.
그래서 이를 해결하기 위해 교차검증(cross validation)을 활용한다.
test data는 모델이 충분히 준비될 때 까지 사용하지 않고 train data 일부를 검증용으로 활용한다. 이를 통해 일반화된 모델을 선택할 수 있게 된다.
내가 직접 나누지 않아도 scikit-learn을 사용하면 편리하다.
사이킷런이 제공하는 교차검증 중 몇 가지를 나눠 살펴보자
- 데이터들이 독립적이고 동일한 분포를 가진 경우
- 데이터의 클래스에 불균형이 있는 경우
- 데이터가 그룹화된 경우
- 데이터가 시간에 관련된 경우
1. 독립적이고 동일한 분포의 데이터
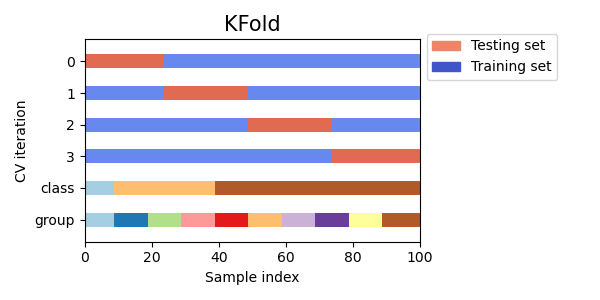
📚 K-fold
k-fold 는 모든 데이터를 k개의 샘플로 나누며, 가능한 같은 크기로 나누고 이렇게 나눠진 것을 fold 라고 한다.
그래서 k-1개의 fold를 train data로, 남은 하나는 test로 활용한다.
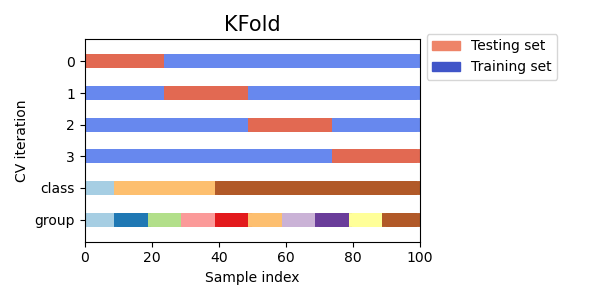
그리고 한 번 fold 지나갈 때마다 accuracy를 구하고 그 값을 총 평균내어 모델의 성능을 평가한다.
Accracy = Average(Accracy1, ..., Accuracyk)
간단한 예제로 살펴보자. 아래에서 5개 샘플에 대해 3-fold-cv를 진행했다.
import numpy as np
from sklearn.model_selection import KFold
X = ["a", "b", "c", "d", "e"]
kf = KFold(n_splits=3)
print(kf.get_n_splits(X))
print(kf)
for train, test in kf.split(X):
print(train, test)출력 (KFold는 index를 반환)
3
KFold(n_splits=3, random_state=None, shuffle=False)
[2 3 4] [0 1]
[0 1 4] [2 3]
[0 1 2 3] [4]📚 LOO
만약 KFold에서 k가 데이터와 같은 크기라면 Leave One Out 전략과 동일하다고 할 수 있다.
Leave One Out은 간단한 교차 검증인데, 데이터 중 하나를 제외하고 모두 train data로 활용된다. 이 경우 train data에서 하나의 샘플만 제거하기 때문에 나머지가 모두 학습에 활용되어 데이터 낭비가 줄어든다.
예제
from sklearn.model_selection import LeaveOneOut
X = [1, 2, 3, 4]
loo = LeaveOneOut()
for train, test in loo.split(X):
print("%s %s" % (train, test))출력
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]2. 클래스에 불균형이 있는 데이터
📚 Stratified k-fold
데이터 중 분류 대상 클래스의 불균형이 심한 것이 있을 수 있다.
그럴 때 StratifiedKFold는 데이터 레이블의 분포를 고려해 각 train, validation 폴드가 전체 데이터셋의 분포에 가까워진다.
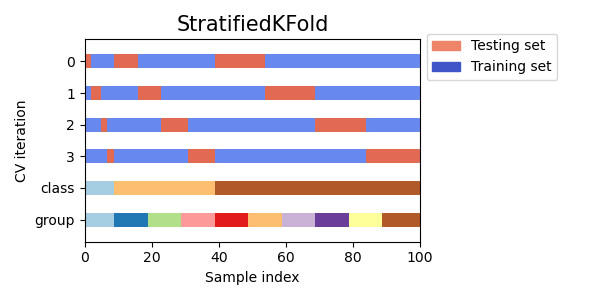
한 번 KFold와 비교하는 간단한 예제를 확인해보자.
from sklearn.model_selection import StratifiedKFold
X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
skf = StratifiedKFold(n_splits=3)
for train, test in skf.split(X, y):
print('train - {} | test - {}'.format(np.bincount(y[train]), np.bincount(y[test])))
from sklearn.model_selection import KFold
X, y = np.ones((50, 1)), np.hstack(([0] * 45, [1] * 5))
kf = KFold(n_splits=3)
for train, test in kf.split(X, y):
print('train - {} | test - {}'.format(np.bincount(y[train]), np.bincount(y[test])))출력
train - [30 3] | test - [15 2]
train - [30 3] | test - [15 2]
train - [30 4] | test - [15 1]
train - [28 5] | test - [17]
train - [28 5] | test - [17]
train - [34] | test - [11 5]출력 결과 중 위의 내용이 StratifiedKFold 진행한 것이다. y 데이터가 0과 1로 이루어져 있었고 1이 0에 비해 적었다. 출력 내용에서 대괄호 안의 3 이나 2 같은 수가 1의 갯수라고 생각해도 되는데, 이처럼 StratifiedKFold를 거치면 train data와 test data 모두에서 클래스 비율을 유지하게 된다.
3. 그룹화된 데이터
환자 의료 데이터와 각 환자의 샘플 채취 데이터 같이 개별 그룹에 따라 데이터가 달라지는 경우가 있을 수 있다. 이때, 특정 그룹 집합에 대해 훈련된 모델이 다른 그룹에 잘 일반화되는지 알고 싶다면 어떻게 검증할 수 있을까? 이를 측정하려면 validation fold의 모든 샘플이 짝을 이루는 train fold에서 오지 않았는지 확인해야 한다.
📚 Group k-fold
GroupKFold는 train, test data에서 동일한 그룹이 표시되지 않도록 하는 KFold의 변형 방식이다.
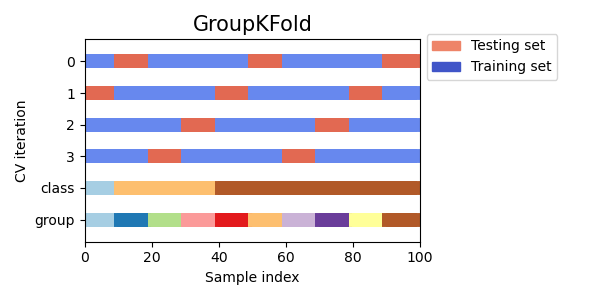
간단하게 1~3 3개의 그룹이 있다고 하고 예제를 확인해보자.
from sklearn.model_selection import GroupKFold
X = np.array([0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10])
y = np.array(["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"])
groups = np.array([1, 1, 1, 2, 2, 2, 3, 3, 3, 3])
gkf = GroupKFold(n_splits=3)
gkf.get_n_splits(X, y, groups)
for train_index, test_index in gkf.split(X, y, groups=groups):
print("%s %s" % (train, test))
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print(X_train, X_test, y_train, y_test)출력
[0 1 2 3 4 5] [6 7 8 9]
[0.1 0.2 2.2 2.4 2.3 4.55] [ 5.8 8.8 9. 10. ] ['a' 'b' 'b' 'b' 'c' 'c'] ['c' 'd' 'd' 'd']
[0 1 2 3 4 5] [6 7 8 9]
[ 0.1 0.2 2.2 5.8 8.8 9. 10. ] [2.4 2.3 4.55] ['a' 'b' 'b' 'c' 'd' 'd' 'd'] ['b' 'c' 'c']
[0 1 2 3 4 5] [6 7 8 9]
[ 2.4 2.3 4.55 5.8 8.8 9. 10. ] [0.1 0.2 2.2] ['b' 'c' 'c' 'c' 'd' 'd' 'd'] ['a' 'b' 'b']각 그룹은 다른 test fold에 있고, 같은 그룹은 test나 train에 동시에 포함되지 않는다. 즉, 두 개의 다른 폴드에 동일한 그룹이 나타나지 않는다.
이때 fold들은 데이터의 불균형 때문에 모두 정확히 같은 크기로 나누어지지 않는다는 점을 주의하자.
예제 2
import numpy as np
from sklearn.model_selection import GroupKFold
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([1, 2, 3, 4])
groups = np.array([0, 0, 2, 2])
group_kfold = GroupKFold(n_splits=2)
group_kfold.get_n_splits(X, y, groups)
print(group_kfold)
for train_index, test_index in group_kfold.split(X, y, groups):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print(X_train, X_test, y_train, y_test)출력
GroupKFold(n_splits=2)
TRAIN: [0 1] TEST: [2 3] # index
[[1 2]
[3 4]] [[5 6]
[7 8]] [1 2] [3 4]
TRAIN: [2 3] TEST: [0 1]
[[5 6]
[7 8]] [[1 2]
[3 4]] [3 4] [1 2]4. 시간 종속된 데이터
시계열 데이터는 시간적으로 가까운 관측치 사이의 상관관계로 특징지어진다. 그래서 훈련시키는 데 사용되는 것과 같은 미래 관측치에 대한 시계열 데이터에 대해 모델을 평가하는 것은 매우 중요하다. 그 방법으로 제공되는 것이 Time Series Split이다.
📚 Time Series Split
Time Series Split은 k번째 fold까지 train fold로 사용하고 k+1번째 fold는 test fold로 사용하는 KFold의 변형이다.
앞선 교차검증과 다르게 여기에서의 연속적인 훈련 세트는 그 앞에 있는 것들의 상위 집합이다. 그리고 항상 첫번째 train set에 모든 잉여 데이터를 추가해간다.
이는 고정된 시간 간격의 시계열 데이터 교차검증에 활용될 수 있다.
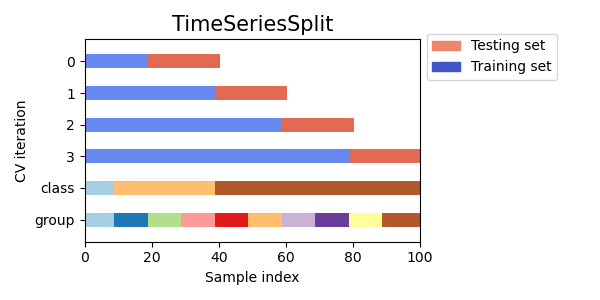
예제
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
tscv.get_n_splits(X)
print(tscv)
TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
for train, test in tscv.split(X):
print("%s %s" % (train, test))
X_train, X_test, y_train, y_test = X[train], X[test], y[train], y[test]
print(X_train, X_test, y_train, y_test)출력
TimeSeriesSplit(gap=0, max_train_size=None, n_splits=3, test_size=None)
[0 1 2] [3]
[[1 2]
[3 4]
[1 2]] [[3 4]] [1 2 3] [4]
[0 1 2 3] [4]
[[1 2]
[3 4]
[1 2]
[3 4]] [[1 2]] [1 2 3 4] [5]
[0 1 2 3 4] [5]
[[1 2]
[3 4]
[1 2]
[3 4]
[1 2]] [[3 4]] [1 2 3 4 5] [6][참고] https://scikit-learn.org/stable/modules/cross_validation.html
