Data Science
1.ARIMA 모델 예측 결과
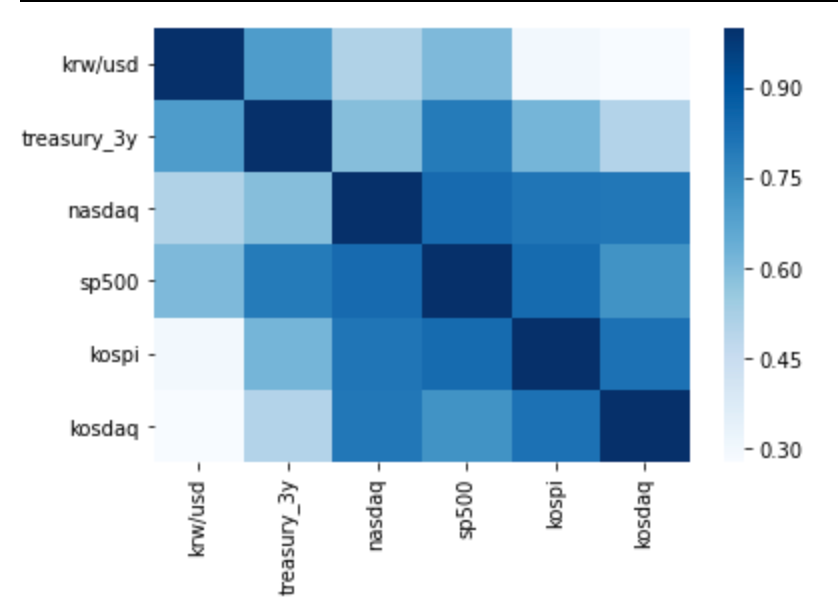
RNN 기반의 LSTM 모델을 사용하여 시계열 분석을 진행하기 전에, 시계열 데이터를 예측하는 전통적인 머신러닝 방법론인 ARIMA 모델을 활용하여 다양한 경제/금융 변수들의 데이터 추이를 예측하는 것을 목표로 함FRED, 한국은행의 경제통계 DB를 통해 7가지 변수(
2021년 8월 26일
2.Amazon Redshift Super Type Data 쿼리

Redshift는 Athena와는 달리, 비정형 데이터 구조(주로 Json과 같은 key-value 구조)를 저장할 수 있도록 하는 super type 컬럼을 제공하고 있다.관련 내용 : https://docs.aws.amazon.com/redshift/lat
2022년 3월 14일
3.[Python 심화] Zip 함수

열벡터를 묶어버리는 Zip 함수 이해해보기 !
2023년 5월 22일
4.데이터를 분류한다는 것의 의미

일단 데이터 리터러시는 Tidy Data를 기준으로 설명하도록 한다.하나의 데이터를 Row 하나라고 하면, 이 데이터에는 N개의 Feature가 맵핑되어 있는 것이다. 아주 간결하게 표현하면 Row 1개는 N차원 벡터이다. 차원의 수는 각 데이터가 갖고 있는 Featu
2023년 9월 24일