
In Retrospect...
진작 했어야 하지만.. 코드만 보면 스트레스를 받고 머리가 아파지는 것 때문에 Python 코드 리뷰 및 분석을 미뤄두었다.
이제는 여유가 조금 생겨서 계속 미뤄두었던 데이터 전처리 및 자동화 코드와 관련된 엔지니어링 측면의 리뷰를 해보기로 했다. 일단 데이터 엔지니어링 및 리포트 자동화 인턴쉽을 할 때, Python으로 순수하게 내가 작업한 코드만 약 1,000줄 가량의 Python 코드였던 것 같다. 작업량이 결코 적은 수준은 아니었다..
Git을 활용하여 DMP 프로덕트의 기능을 일부 수정 및 추가 개발을 했던 기억도 난다. 정확히 시스템 상에서 어떤 기능을 어떻게 고쳤는지는 조금 더 회고를 해봐야할 것 같다. 확실한 것은 사내 광고 DMP에서 개별 데이터 엔드포인트 매체별로 ETL 기능이 개발되어 있었고, 고객사가 추가될 때마다 이에 대한 Python 코드와 DB에 적재된 데이터에 직접 접근해야 할 경우에는 SQL 스크립트까지 추가로 반영해주는 작업을 했던 것이 기억난다.
그리고 이 때 이후로 데이터 엔지니어링 업무에 대해 많은 흥미와 도전 의식이 생겼다. CS 지식 학습과 프로그래밍 연습을 안정적으로 성실히 하지 않으면 기본기가 쌓이지 않아, 데이터 엔지니어로서 성장하기 쉽지 않기 때문이다.
0. Refactoring
우선, 전임자의 Python 코드의 가독성과 효율성을 높여야했다. 조금 충격적이었던 것은, 아무리 비개발자가 짠 코드라고 해도 너무나 가독성이 떨어지고 사람이 일을 하라고 만든 코드 뭉치인가 의심스러울 정도였다. 객체지향 개념은 1도 들어가있지 않은 코드였다. 나도 객체지향을 몰랐기 때문에 지금 생각해보면 클래스를 사용하여 재사용성을 높인다면 조금 괜찮은 코드들이 많이 만들어지지 않았을까 한다. 팀 자체가 잘 훈련된 개발자로 이루어진 팀이 아니었기 때문에 정교한 코드 작성이 이루어지진 않았다.
구조적으로 반복되는 라인도 너무 많아서, 이들의 구조를 일반화하여 함수 하나로 감싸는 작업만 수차례 진행했다.
Refactoring = Logical and clean generalization, without error.
최대한 깔끔하게 다듬는다고 다듬었던 기억이 나는데 여전히 누더기였다.
이 때 파이썬 클린코드란 무엇인가, 좋은 코드의 구조와 가독성 좋은 코드를 어떻게 해야 오류없이 작성할 수 있는지 머리를 쥐어짜냈던 기억이 있다. 마치 논리적인 분석글을 쓰면서 몇가지의 논리적 구조체로 글의 내용을 맞춰가는 것처럼 말이다.
데이터 엔지니어링이라는 작업을 크게 2가지 기준으로 나누어 분석해보도록 하자. 첫번째 기준은 데이터 엔지니어링 코드의 기능, 즉 각 코드가 수행하는 역할별로 나누는 것이다. 두번째 기준은 데이터 엔지니어링 작업의 일반적인 프로세스인 ETL 절차를 기준으로 나눠보는 것이다.
첫번째 기준인 기능 단위의 데이터 엔지니어링에 대해 살펴보자.
1. Data Engineering by features
내가 작성한 코드의 구조를 경험적으로, 귀납적으로 일반화해보면 다음과 같이 크게 4가지 기능을 사용했던 것 같다. (1) 데이터 형변환, (2) 데이터 필터링, (3) 데이터 Merging, 그리고 (4) 데이터 Aggregation 이렇게 분류해볼 수 있겠다.
(1) 데이터 형변환 (astype, to_datetime, 결측치 제거 등)
(2) 데이터 필터링 (loc)
(3) 데이터 Merging (Join, Merge, Concat)
(4) Aggregation (Pivot)
다음으로는 프로세스 기준으로 데이터 엔지니어링 작업을 분류해보자.
2. Data Engineering by Process
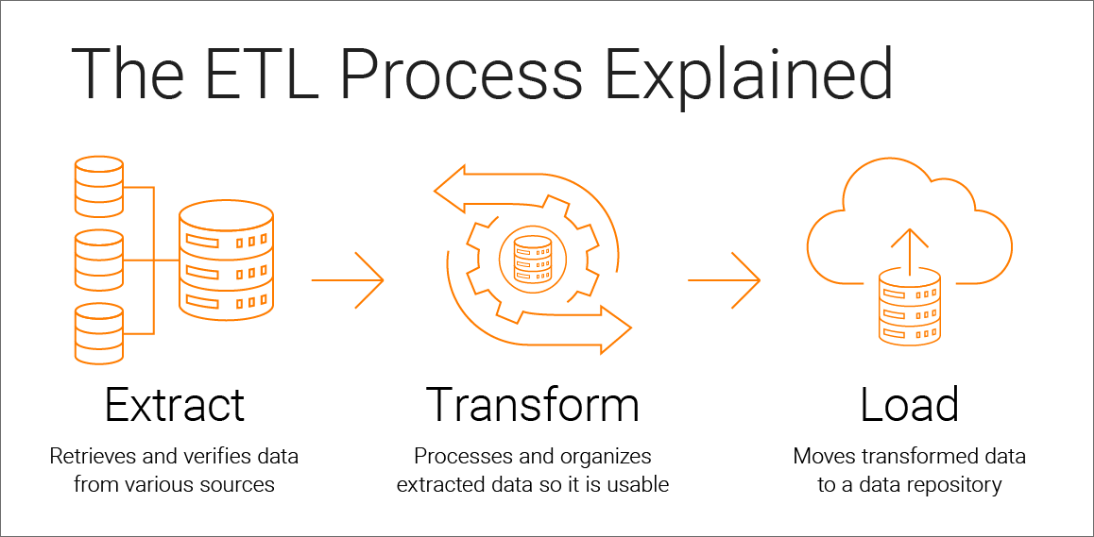
엄밀히는 내가 수행한 데이터 엔지니어링 작업은 백엔드 시스템 엔지니어링 측면의 데이터 엔지니어링이 전혀 아니었다.. 소프트웨어 프로그램의 가장 상위 레이어인 API 레벨에서 뽑혀져나온 데이터(그러나 양이 많은...)를 핸들링 및 가공하여 리포팅할 때 필요한 Python 자동화 코드를 만들었을 뿐이다.
그래서 아직도 더 하위 레이어에서의 데이터 엔지니어링에 대해 갈증이 있다. 데이터 파이프라인을 직접 정의하고 설계하여 백엔드 단위에서 처리되는 데이터 ETL 플로우를 본다던지 등등... 좌우지간, API를 통해 추출되어 로컬에 저장된 데이터를 어떻게 수집하고 이를 가공 및 적재하는지 알아보자.
어쨌든 동일한 대상을 분류 기준만 다르게 설명하는 것이기에 1에서 다룬 내용과 일부 겹치는 부분이 있을 것이다.
(1) Data Extraction (데이터 추출 및 수집; E)
참고로, 일반적인 사무직 종사자들이 특정 데이터 테이블을 긁어올 일이 있으면 Listly를 무조건 사용해야 한다.
(2) Data Transformation (데이터 가공; T)
(3) Data Load (데이터 적재; Load)
Next...
다음엔 내가 지금까지 학습해왔던 지식과 경험을 토대로 내가 생각하는 Data Literacy란 무엇이고, 어떤 구조로 나는 데이터를 이해하고 분석하고 있는지를 간단하게 리뷰해보고 싶다.
DE 관련 재밌는 블로그
