
💡 V8엔진이란
V8은 구글에서 C++으로 개발한 고성능 JavaScript 엔진으로 JavaScript 코드를 바이트 코드로 컴파일하고 실행하며 히든 클래스, 인라인 캐싱과 같은 최적화 기법을 사용하여 동적 타이핑 언어인 자바스크립트의 특성에도 불구하고 높은 성능을 제공하여 Chrome, Node,js, Electron 등 많은 곳에서 사용되고 있다
💡 JIT 컴파일러
JIT(Just-In-Time)은 프로그램이 실행되는 런타임 시점에 기계어로 번역하는 컴파일 기법이다. 인터프리터와 컴파일러를 혼합하여 둘의 장점을 취한 기법으로 볼 수 있다.
기존의 컴파일 방식은 모든 코드를 번역 해야해서 컴파일 시간이 길어지고 메모리 사용량도 커질 수 있는데 JIT 컴파일러는 코드가 실제로 실행될 때 필요한 부분만을 컴파일하여 컴파일 시간을 줄이고 코드의 변경에 유연하게 대응이 가능하며 실행 중에 발생하는 정보들을 바탕으로 실행 환경에 특화된 최적화를 통해 성능 향상이 이루어진다
Chrome, Firefox, Safari를 비롯해 모던 브라우저 자바스크립트 엔진은 대부분 JIT 컴파일 방식을 채택하여 자바스크립트 코드를 해석하고 실행한다
💡 V8엔진의 등장 배경
초창기 자바스크립트는 HTML을 동적으로 처리하는 것이 최우선 이였기때문에 가벼운 실행을 위해 인터프리터 방식을 기반으로 자바스크립트 엔진을 개발하였다.
하지만 이런 인터프리터 방식은 메모리 관점에서는 가볍지만 실행속도, 최적화 등 고성능 프로그램을 실행하기에는 한계가 있었고 그러던중 구글은 Google Maps 같은 대규모 웹 어플리케이션 서비스를 제공하기 위해서 JIT컴파일러 방식을 도입한 고성능의 자바스크립트 엔진 V8을 개발하였다
💡 V8엔진의 동작 원리
V8의 핵심 구조는 아래의 그림으로 설명할 수 있는데 자바스크립트로 작성된 소스코드를 Parser에게 전달하고 Parser는 자바스크립트를 분석하여 AST를 생성한다.
그러면 Ignition이라는 인터프리터는 AST를 기반으로 Bytecode를 생성하고 실제 자바스크립트가 실행된다
이 과정에서 성능 향상을 위해 최적화 컴파일러 Turbofan이 사용되어 Bytecode를 분석하고 자주 사용되는 코드(hot)에 대해서 더 효율적으로 최적화 하며, V8 9.1버전 부터 도입된 비최적화 컴파일러 Sparkplug을 통해서 Ignition이 생성한 Bytecode를 빠르게 컴파일하면서 Ignition과 TurboFan 사이의 너무 큰 성능차로 인한 각극을 줄이는 중간단계의 컴파일러를 도입하여 실제 전반적인 성능이 5~15% 향상 되었다고 한다
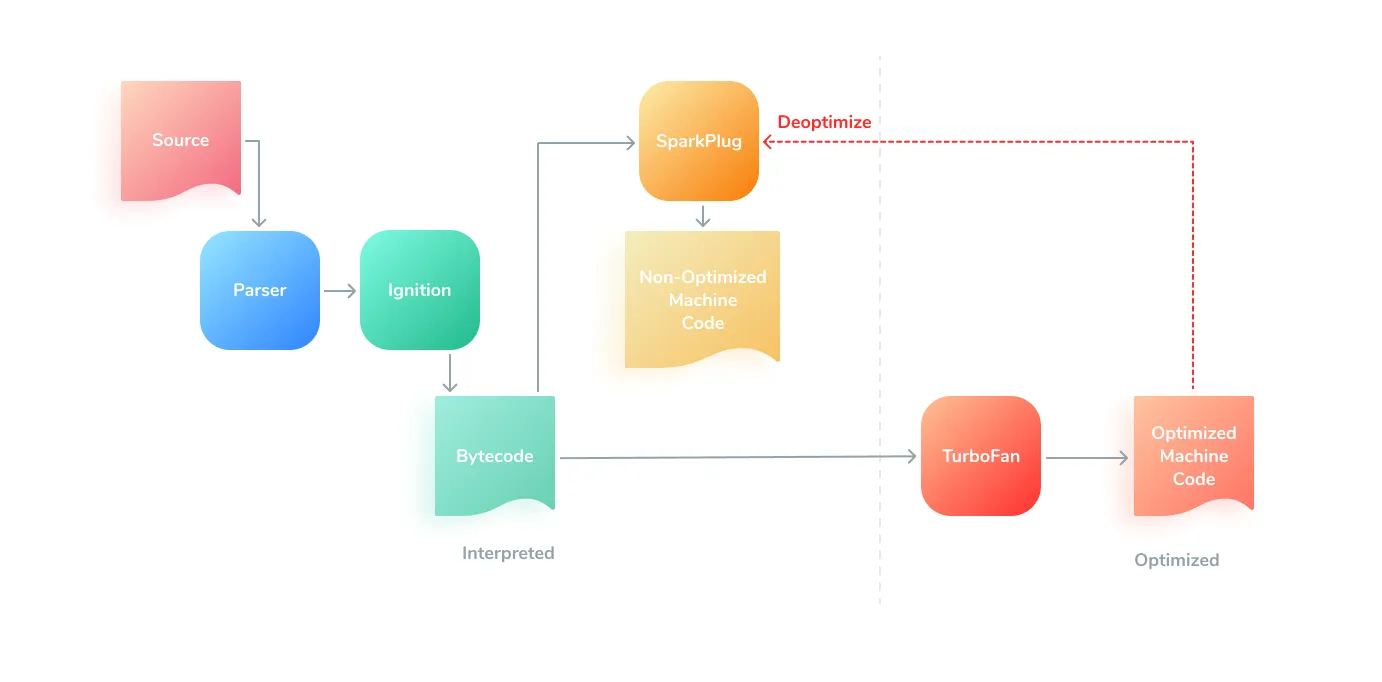
V8엔진 동작 방식 medium
🔎 V8의 동작원리를 이해하기 위해 각 단계를 좀 더 자세히 알아보자
1) Parser
V8엔진은 처음 자바스크립트 소스코드를 Parser에게 보낸다 Parser는 전달받은 자바스크립트 코드를 어휘분석(Lexical Analysis)이라는 과정을 통해서 토큰으로 분해되는데 이 과정에서 소스코드가 키워드, 식별자, 연산자 및 구분자로 분해된다. 이후 Parser는 이렇게 만들어진 토큰을 구문분석(Syntax Analysis)이 라는 과정을 진행하며 이때 문법에러가 있으면 Syntax Error가 발생하게된다. 만약 여기까지 문법에러가 없다면 이렇게 만들어진 토큰으로 트리 형태를 만드는데 이게 바로 추상구문트리(Abstract Syntax Tree, AST)이다
⭐ AST 변환은 이런식으로 된다
function square(n) {
return n * n;
}{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square",
},
params: [
{
type: "Identifier",
name: "n",
},
],
body: {
type: "BlockStatement",
body: [
{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n",
},
right: {
type: "Identifier",
name: "n",
},
},
},
],
},
};
2) Ignition (인터프리터)
Ignition이란 전달받은 AST를 바탕으로 바이트 코드를 생성하는 V8의 인터프리터이다. 바이트 코드란 기계어를 추상화한 코드로 고수준 언어와 기계어 사이의 중간 형태의 코드이다. 이렇게 변환된 바이트코드가 실행되기 바로 전에 실행 컨텍스트가 생성되고 이 시점에 호이스팅, this바인딩 등이 일어난다. 또한 Ignition은 바이트 코드를 실행하면서 프로파일링 및 피드백 데이터를 수집하는데 이런 수집한 정보를 바탕으로 코드가 반복되어 실행되는지 등의 여러 조건에 따라 TurboFan 컴파일 또는 SparkPlug 컴파일이 결정된다
3) TurboFan
Ignition이 생성한 바이트 코드를 Ignition이 수집한 데이터를 기반으로 복잡하고 정교하게 기계어 코드로 변환하는 최적화 컴파일러이다. TurboFan이 사용하는 최적화 기법으로는 대표적으로 히든클래스, 인라인캐싱이 존재하며 필요에따라 역최적화를 진행하기도 한다
4) SparkPlug
Ignition과 TurboFan사이의 중간단계에 위치한 비최적화 컴파일러이다. TurboFan과 마찬가지로 Ignition이 생성한 바이트 코드를 바탕으로 기계어 코드를 만들어 낸다
🔎SparkPlug가 도입된 이유
V8 5.9 버전이후로는
Ignition과TurboFan만 존재했는데 9.1버전부터 비최적화 컴파일러SparkPlug가 도입되게 되었는데 이유가 뭘까?
최적화 컴파일러TurboFan은 시간은 조금 걸려도 최적의 성능으로 코드 실행이 가능했지만Ignition과TurboFan사이의 너무 큰 성능차로 인한 각극을 줄이고자 빠르고 단순한 비최적화 컴파일러SparkPlug를 도입하게된다SparkPlug는TurboFan과 같이AST가 아닌 바이트코드를 기계어로 변환하며TurboFan처럼 최적화를 하지않아서 빠르게 동작이 가능하다
💡 V8엔진 성능 최적화
앞서 TurboFan에서 최적화 기법으로 히든클래스와 인라인캐싱이 존재한다고 했는데 이 두 가지에 대해서 알아보자
✨ 동적 타이핑 언어에서의 객체의 제약
정적 타이핑 언어는 컴파일 시점에 프로퍼티에 대한 정보를 결정하고 오프셋을 결정하여 런타임에 객체의 프로퍼티를 빠르게 참조할 수 있지만 동적 타이핑언어는 객체의 프로퍼티가 동적으로 변경될 수 있기 때문에 각 프로퍼티에 대한 정보를 메모리에 저장하고 프로퍼티를 읽어야할때마다 동적탐색 해야 한다. 이는 자바스크립트의 유연성을 높여주지만 메모리 사용량과 성능에 영향을 줄 수 있다.
✨ 히든클래스(Hidden Class)
V8에서는 이러한 동적 타이핑언어의 객체에 대한 성능 저하를 최소화하기 위한 장치로 히든 클래스라는 내부 구조를 만들어서 동적탐색을 회피하고 있다.
쉽게말해 히든 클래스를 만들어서 동일한 히든클래스를 가진객체는 동일한 구조와 프로퍼티 배치를 공유하며, 이를 통해 같은 구조의 객체가 여러 번 생성되어도 쓸데없이 객체를 늘리지 않고 히든 클래스를 공유하면서 메모리 효율적으로 오프셋 관리를 하는 것
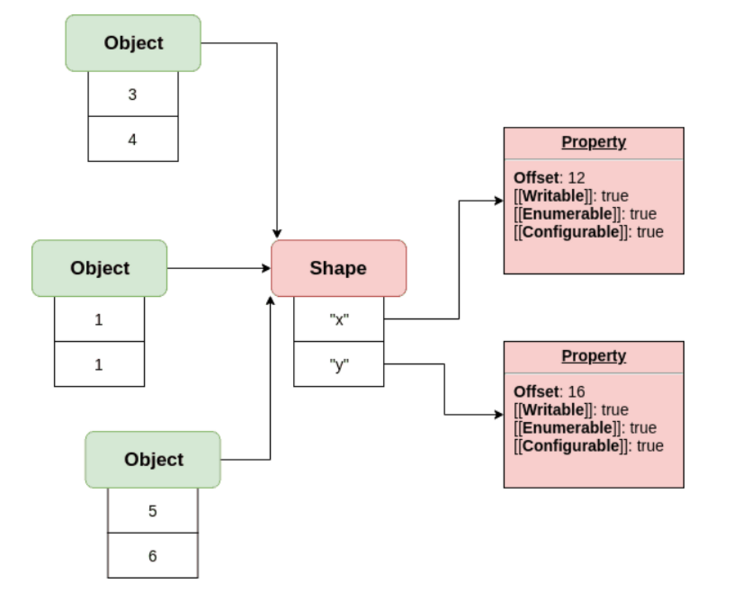
const obj = {
x: 1,
y: 1,
};이런 간단한 객체 obj 가 존재한다고 가정할 때 객체의 각 프로퍼티 x,y는 메모리에 저장되는데 그 위치는 히든클래스(Shape)에 정의된 offset에 따라 결정된다. 아래의 그림에서 x는 offset이 12, y는 offset이 16인 곳에 각각 저장되어 있으며, 이는 각각의 오프셋만큼을 포인터를 이동시켜 obj의 x,y를 찾도록 알려준다. 이처럼 히든클래스는 객체의 구조와 프로퍼티에 대한 정보를 담고 있으며, V8엔진은 이 정보를 활용하여 프로퍼티를 찾는 과정을 수행한다

이러한 히든클래스는 동일한 구조의 객체를 생성할 때 비로소 빛을 발하는데
동일한 구조의 객체를 여러 번 생성해도 히든 클래스를 통해 각 객체의 속성 구조와 오프셋을 공유하면서도, 각 객체는 독립적인 메모리 공간에 속성값을 저장하므로, 서로 다른 속성값을 가질 수 있고 이는 히든 클래스를 쓸데없이 늘리지 않으면서 오프셋을 효율적으로 사용해 속성 접근방법을 높이는 최적화 방법이다
const obj1 = {
x: 1,
y: 1,
};
const obj2 = {
x: 3,
y: 4,
};
const obj3 = {
x: 5,
y: 6,
};
🚩주의해야 할 점은 동일한 구조의 객체 라고해서 항상 동일한 히든 클래스를 갖는 것은 아닌데 아래의 코드에서
obj1,obj2,obj3은 같은 구조를 갖지만 결과적으로 셋다 다른 히든클래스를 갖는다
const obj1 = {
x: 1,
y: 1,
};
const obj2 = {};
obj2.x = 1;
obj2.y = 1;
function Point(x, y) {
this.x = x;
this.y = y;
}
const obj3 = new Point(1, 1);동적으로 속성을 추가하게 되는경우 추가할 때마다 새로운 히든클래스가 생성되며 새로 만들어지는 히든 클래스에서는 속성을 추가하기 전의 기존의 히든클래스를 참조하는 transition 이라는 속성을 갖게되어 히든클래스들은 transition 체이닝을 통해 이전 히든클래스의 참조를 하게된다. 아래의 그림을 보면 같은 구조이지만 위에서 본 히든클래스의 구조랑 다른 구조를 갖는 것을 알 수 있다
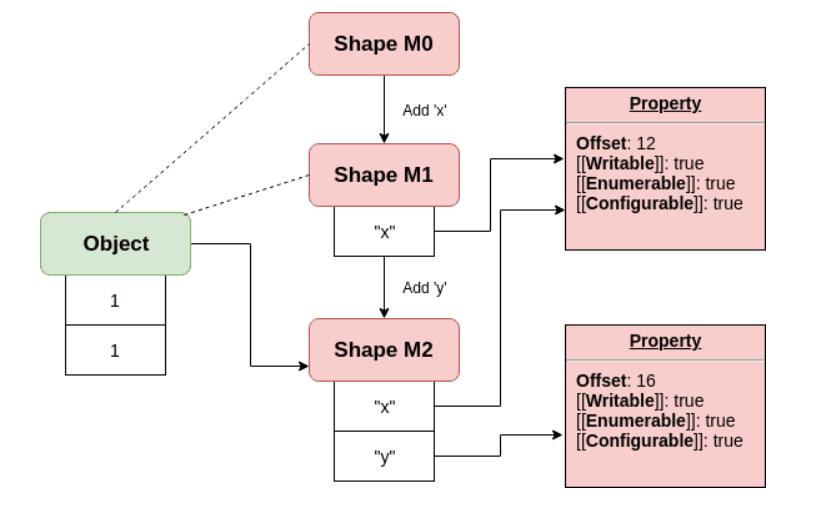
따라서 결과적으로 빈객체에서 동적으로 할당된 객체와 초기값이 할당된 객체는 분명 같은 속성을 갖는 객체일지라도 히든클래스의 형태가 달라진다. 그래서 특별한 이유가 있는게 아니라면 동적으로 속성을 추가하는 것보다 한 번에 객체를 생성하는 것이 히든 클래스의 수도 줄이고 transition 체이닝도 단축하여 최적화 이점을 가져갈 수 있다.
✨ 인라인캐싱(Inline Cache, IC)
인라인 캐싱이란 자바스크립트에서 반복적으로 객체의 프로퍼티에 접근하는 작업을 최적화하는 기법이다. 자바스크립트에서 객체의 프로퍼티에 접근하려면 해당 객체의 히든클래스를 통해 프로퍼티의 위치를 찾아야 한다.
하지만 반복적인 접근이 발생할 경우, 매번 히든클래스로부터 프로퍼티의 위치를 다시 찾는 것은 비효율적인데 인라인 캐싱은 이러한 비효율성을 개선하기 위해 히든클래스로부터 알아낸 프로퍼티의 인덱스 정보를 캐싱하는데 같은 히든클래스를 가진 객체에 접근할 때에는 프로퍼티의 위치를 다시 찾는 과정을 생략하고, 캐싱된 인덱스를 그대로 사용하여 접근 속도를 향상시킨다
즉, 인라인 캐싱 이란 객체의 프로퍼티에 접근하는 과정에서 히든클래스로부터 알아낸 프로퍼티의 인덱스를 캐싱하여 반복적인 접근을 최적화하는 기법이다
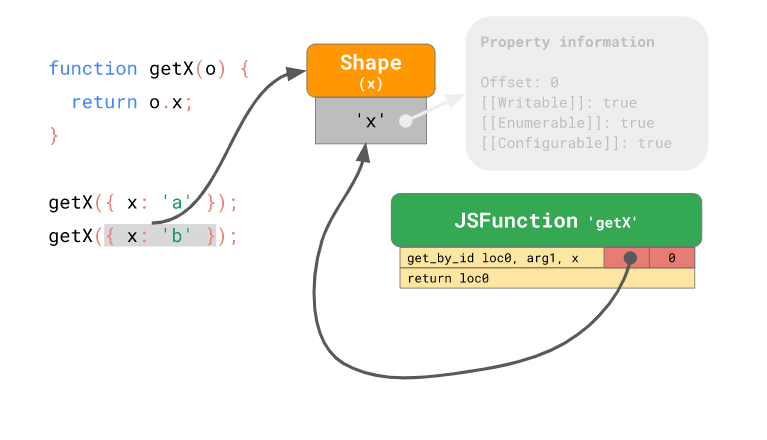
위 그림에서 getX({x: 'a'})가 실행될 때 x라는 프로퍼티를 갖는 히든클래스가 생성되어 해당 히든클래스와 오프셋정보가 캐싱된다. 이후에 getX({x: 'b'})가 실행될 때 이전에 캐싱된 {x: 'a'}와 동일한 히든클래스를 갖기 때문에 히든 클래스의 프로퍼티 조회를 하지 않고 바로 캐싱된 offset을 통해 값을 가져올 수 있게된다. 따라서 반복적인 접근에서 히든클래스와 오프셋을 재활용하여 접근속도를 향상시킬 수 있게된다.
💡 V8 최적화를 위해 우리가 고려해 봐야 할 것
-
가능한 같은 구조, 같은 순서의 객체로 히든 클래스를 공유하도록 해서 불필요한 히든 클래스를 최소화 하기
-
객체 초기화 이후 동적으로 프로퍼티를 추가하거나 제거하는 작업은 히든클래스 구조가 변경되기 때문에 가능하면 피하기
-
함수 호출 시 인라인 캐싱 최적화를 위해 동일한 객체유형 사용하기
이러한 것들을 지키지 않아도 성능상의 큰 이슈가 발생하는 것은 아니지만 최적화 기법을 적용함으로써 V8엔진 내부에서 추가적인 최적화 이점을 얻을 수 있기 때문에 코드를 작성할 때 이러한 사항들을 인지하고 있어야한다.
📕 참고 자료
라인 V8의 히든 클래스 이야기
V8 기본 자바스크립트 컴파일러 Sparkplug
V8 function optimization
구글 V8엔진 살펴보기
JavaScript engine fundamentals: Shapes and Inline Caches
