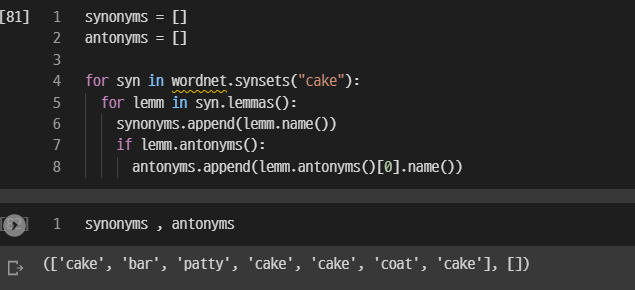
예시 단어 : cake
cake는 wordnet을 활용하여 뽑았을 때 반대어가 없다.
synonyms = []
antonyms = []
for syn in wordnet.synsets("cake"):
for lemm in syn.lemmas():
synonyms.append(lemm.name())
if lemm.antonyms():
antonyms.append(lemm.antonyms()[0].name())output : (['cake', 'bar', 'patty', 'cake', 'cake', 'coat', 'cake'], [])
DESIGN 1 : 유의어, 반대어 모두 활용
-
유의어가 대체 1순위지만 , "유의어 리스트에 담긴 0번째 인덱스 값이 원본 text 단어와 동일하지 않을 경우"라는 조건을 달아두었다.
-
만약 유의어 리스트에 담긴 0번째 인덱스 값이 원본 텍스트 단어와 동일하다면 반대어 리스트를 체크한다. 반대어 리스트에 담긴 값이 한 개라도 있다면 그 값으로 대체한다.
-
배경 : 유의어 리스트에 원본 단어와 동일한 단어가 담기는 경우는 흔하다. 적어도 몇 백 개의 단어를 대체해야하는데, 유의어 리스트에 담긴 모든 요소를 순회하면서 원본 단어와의 동일 여부를 체크하기엔 비용이 많이 든다.
def text_replace(word):
synonyms , antonyms = list(), list()
for syn in wordnet.synsets(word):
for lemm in syn.lemmas():
synonyms.append(lemm.name())
if lemm.antonyms():
antonyms.append(lemm.antonyms()[0].name())
return synonyms[0] if synonyms[0] != word else ( antonyms[0] if len(antonyms) != 0 else word) DESIGN 2 : 유의어만 활용
- 유의어만 활용한다. 유의어 리스트에 담긴 값을 set을 활용해 중복을 제거한다. 중복 제거한 유의어 리스트를 순회하여 대체어를 선택한다.
- 인덱스가 없는 set의 특징을 활용하여, 리스트 순회하는 과정에서 원본 단어와 일치하지 않는 단어를 발견하는 즉시 해당 값을 리턴한다. 그러면 굳이 랜덤할 수 있도록 조작하지 않아도 된다.
def get_deduple_val(synonymsList, compare_word):
# set을 쓰기 때문에 굳이 random할 수 있도록 조작해줄 필요없음
for word in set(synonymsList):
if word!= compare_word:
result = word
break
return result
# design2
def text_replace(word):
synonyms = list()
for syn in wordnet.synsets(word) :
for lemm in syn.lemmas() :
synonyms.append(lemm.name())
result = get_deduple_val(synonyms, word)
return result
