
이전 글에 이어서 Instruction Tuning 관련 논문을 리뷰하겠습니다. 오늘 리뷰할 논문은 Instruction Tuning에 CoT prompting을 추가하여 모델의 성능 향상 (특히 reasoning ability)를 증진할 수 있는지 실험한 논문입니다.
Scaling Instruction-Finetuned Language Models(2022)
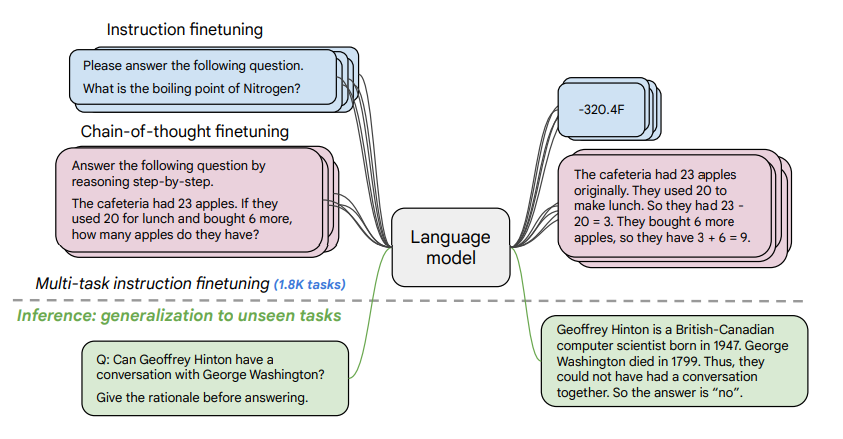
unseen task에 대한 인공지능 모델의 추론 능력을 향상시키는 것이 중요한 goal이죠. NLP에서는 사전학습 모델을 통해 상당한 성취가 이뤄졌는데요, 특히 instruction tuning은 few-shot examplars의 개수를 감소시키는 데 중요한 역할(모델이 적은 예시로도 unseen task를 추론할 수 있도록 향상시켰다는 의미)을 하며 추가적인 발전을 가져왔습니다. 본 논문은 이러한 instruction tuning을 여러 방식으로 발전시키고자 합니다.
논문은 다음 3가지에 집중합니다.
1. instruction tuning 태스크 갯수가 성능에 미치는 영향
2. 모델의 사이즈가 성능에 미치는 영향
3. CoT 포맷의 데이터로 Instruction finetuning
여기서 지난 글에서 리뷰한 논문에서 강조한 바를 다시 짚고 넘어가겠습니다. 해당 연구에서는 특정 규모 이상의 모델에서 instruction tuning을 진행했을 때 그렇지 않은 경우에 비해 성능 향상을 이룰 수 있다고 하였습니다. 이 부분을 기억한 채로 읽어나가겠습니다.
CoT Prompting
CoT(chain-of-thougth) 프롬프팅은, 모델의 reasoning 능력을 향상시키기 위해 사용되는 프롬프팅 방법입니다. 100B 이상의 라지 언어 모델은 강력한 성능을 성취했으나, 이러한 라지 언어 모델도 수학문제나 상식 추론과 같은 reasoning 태스크에서는 어려움을 겪습니다. 연구진들은 reasoning tasks를 잘 수행할 수 있도록 Chain-of-Thougth prompting 방법을 적용했습니다. CoT 프롬프팅은 모델이 다단계의 복잡한 추론 문제를 중간 단계 스텝들로 분해하여 각각의 스텝들을 독립적으로 이해하고 해결할 수 있도록 합니다.
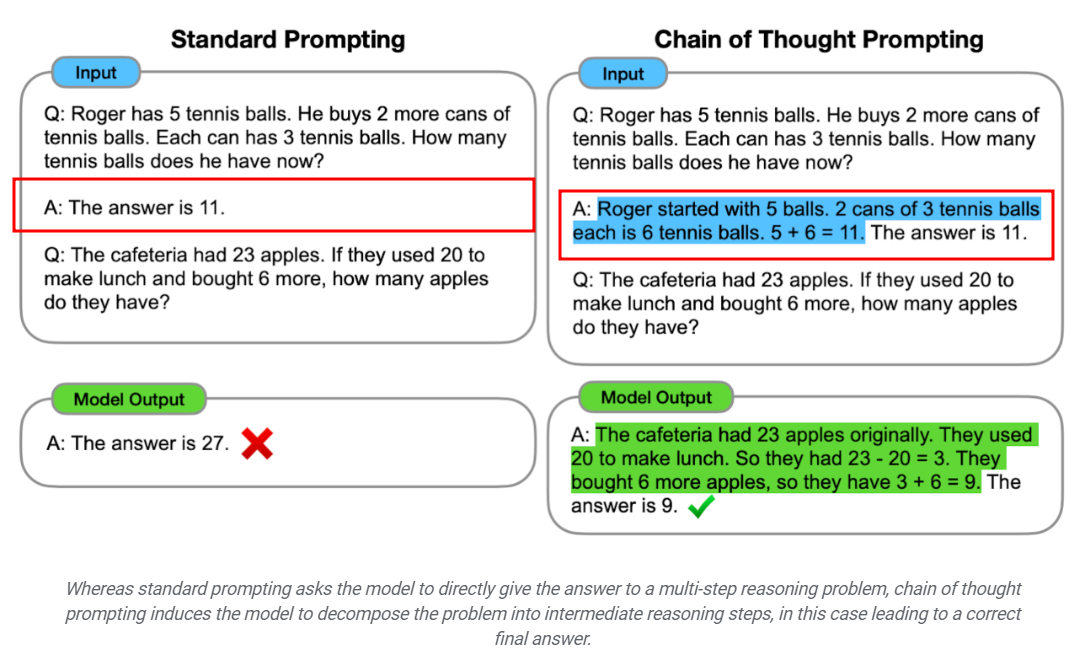
standard prompting과 비교하면 cot prompting의 포맷이 확연히 대비가 됩니다. CoT는 모델에게 퀘스천에 대한 답변을 주기 전에, 중간 단계의 reasoning 스텝을 제공합니다. 모델이 생성한 Chain of Thought가 다단계 추론 문제를 해결하는 직관적인 thought process를 모사할 것이라는 아이디어입니다. 이전에는 파인튜닝을 통해 thought process를 생산했지만, 프롬프팅을 통해 몇 가지의 chain of thought 예시를 포함시킴으로써 모델로부터 thought process를 유도하는 방식입니다. 이 방식을 사용하면 가중치 수정이나 대규모의 학습데이터셋이 필요하지 않습니다.
CoT 자체가 언어 기반이기 때문에 인간이 언어를 통해 해결하는 모든 태스크에 CoT를 적용할 수 있습니다. 다만 CoT의 이점은 충분한 수의 모델 파라미터(약 100B)가 있어야만 얻을 수 있습니다. 연구에서는 chain of thought prompting이 모델 규모의 emergent property라고 합니다. 모델 규모가 커야만 얻을 수 있다는 것이죠.
Finetuning Data
다시 원래 논문으로 돌아오겠습니다. 이미지 우측 박스가 CoT 포맷으로 변환된 데이터입니다.

연구에서는 examplar와 함께 튜닝한 경우와 아닌 경우, 그리고 CoT 포맷 데이터와 함께 튜닝한 경우와 아닌 경우 모두 테스트해보았다고 합니다. 또한 instructions없이 few-shot examplar만으로 포맷팅한 데이터도 존재합니다.
CoT 형식을 사용한 데이터셋은 수많은 데이터셋 중 9개이며, 9개의 데이터셋은 arithmetic reasoning, multi-hop reasoning, and natural language inference 태스크를 포함하고 있습니다.
templates and formatting
이전 글에서 리뷰한 연구와 동일하게 각 태스크 별로 10개의 instruction templates를 구성합니다. templates과 포맷팅은 지난 포스팅에서 설명한 방식과 동일한데요, 다만 본 논문에서는 작업-반전 템플릿에 대한 언급은 없습니다. 작업-반전 템플릿을 사용하지 않은 것 같네요.
Procedure
본 연구에서는 T5(encoder-decoder), PaLM(decoder-only), U-PaLM의 model families에 instruction tuning을 적용합니다. model families는 80M 파라미터부터 540B 파라미터까지 다양한 범위의 크기를 가지고 있습니다. lr, batchsize, dropout, finetuning steps을 제외하고 동일한 학습 절차를 적용했습니다.
Evaluation protocol
지난 포스팅의 연구와 다른 점은 데이터셋인데요, 이전에는 전체 클러스터 중 특정 태스크에 대한 evaluation을 진행할 때 그 태스크가 속한 클러스터 전체를 finetuning 데이터셋에서 완전히 제외하는 방식이었습니다. 이번 연구는 애초에 데이터셋을 구성할 때 모든 모델에게 동일하게 투입될 Tuning에 사용할 finetuning tasks-datasets을 마련하고 성능 평가는 Held-out tasks 박스에 있는 벤치마크로 진행합니다. evaluation은 언어 모델에게 challenging한 벤치마크(Held-out tasks-MMLU, BBH, TyDiQA, MGSM)를 사용합니다.
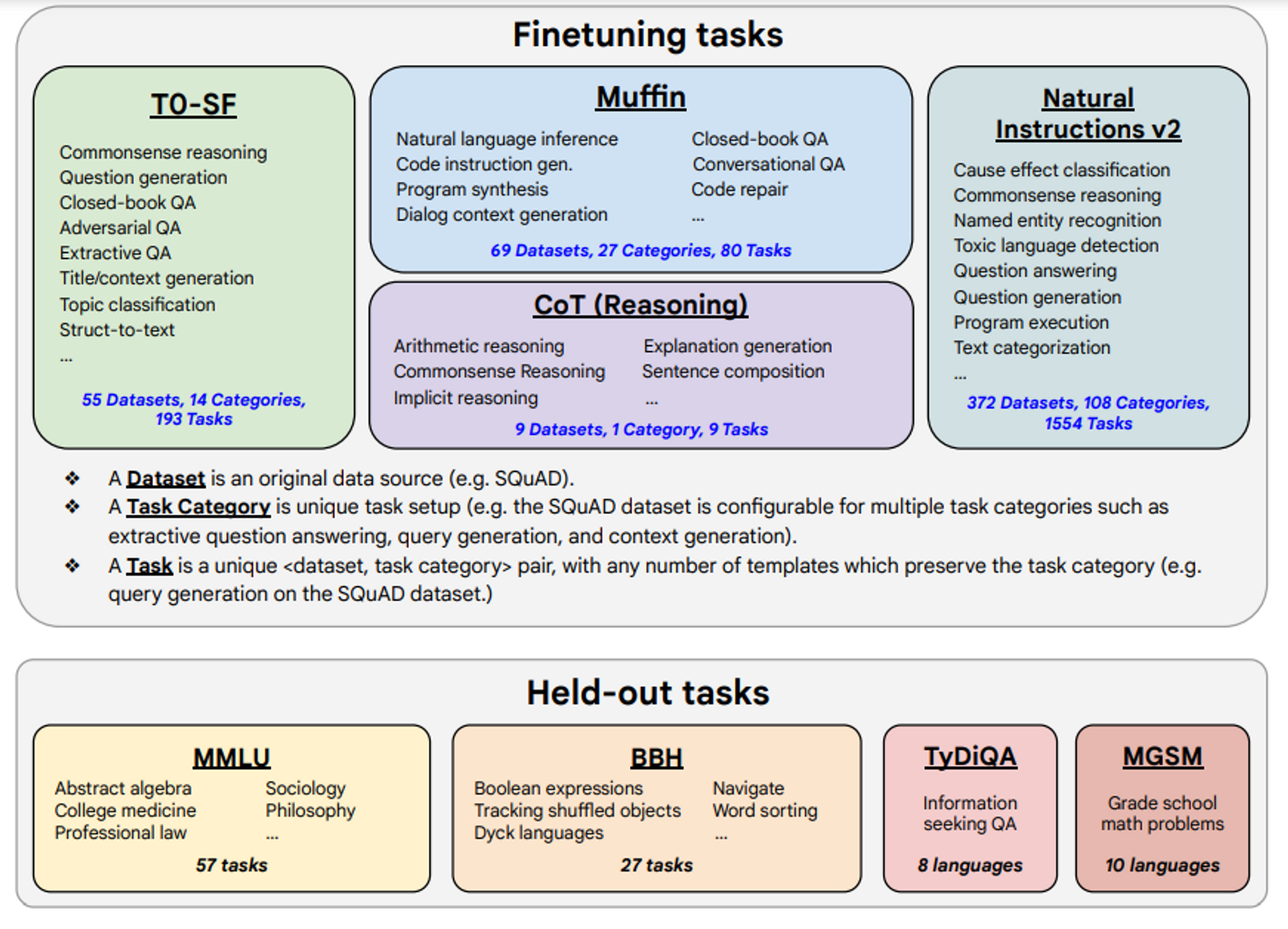
Scailing to 540B parameter and 1.8K tasks
논문은 다음의 3가지를 알아내려고 합니다.
1. instruction tuning 태스크 갯수가 성능에 미치는 영향 2. 모델의 사이즈가 성능에 미치는 영향 3. CoT 포맷의 데이터로 Instruction finetuning
이 파트는 1번과 2번을 설명합니다.
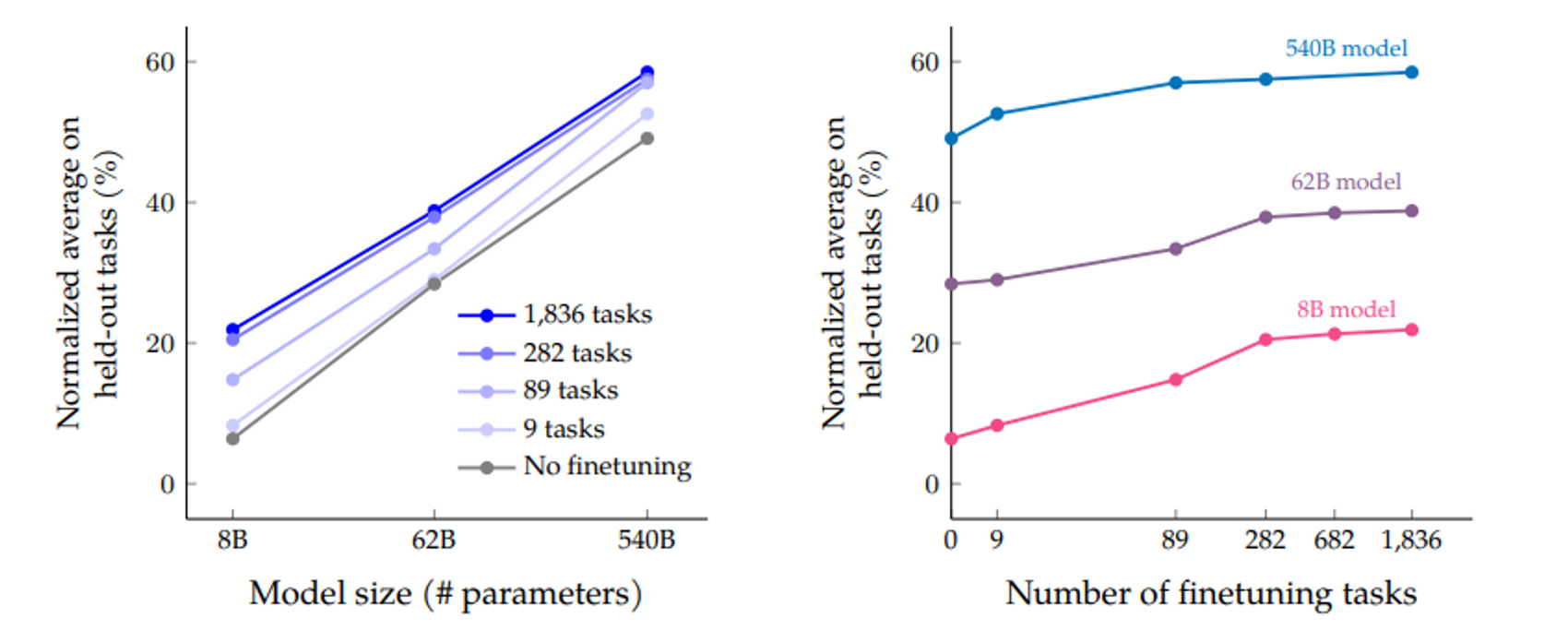
➕ 좌측 그래프
세 가지 모델 크기(8B, 62B, 540B)를 보면, instruction finetining을 진행하였을 때 아닌 경우 대비 성능이 크게 향상된 것을 확인할 수 있습니다. 이는 모델의 사이즈가 성능에 미치는 영향을 설명합니다.
instruction finetuning을 진행하든 아니든 성능이 향상되긴 했지만, 정말 향상된 게 맞다고 결론내리기엔 좀 복잡합니다. 그 이유는 error rate의 경우 540B 사이즈의 모델보다 8B 사이즈의 모델이 더 낮기 때문입니다.
➕ 우측 그래프
finetuning 태스크는 1.8K까지 테스트되었는데요, 파인튜닝 작업 수를 늘리면 성능이 향상되는 것은 맞습니다. 그러나 282개의 태스크 이상부터는 성능 향상이 미미합니다.
이에 대한 이유로 다음을 제시합니다.
(1) 282개에 플러스되는 추가 태스크가 이전 태스크에 비해 특별히 다양하지 않기 때문에 모델에게 새로운 지식을 제공하지 않는다.
(2) pretraining 데이터는 780B tokens으로 구성되어 있지만, instruction finetuning은 사전 훈련 토큰의 0.2%인 1.4B 토큰만 사용한다.
Finetuning with CoT annotations
이 파트는 3번 주제인 CoT 포맷의 데이터를 포함시켜 instruction tuning을 진행하면 성능이 향상되는가에 대해 설명합니다.
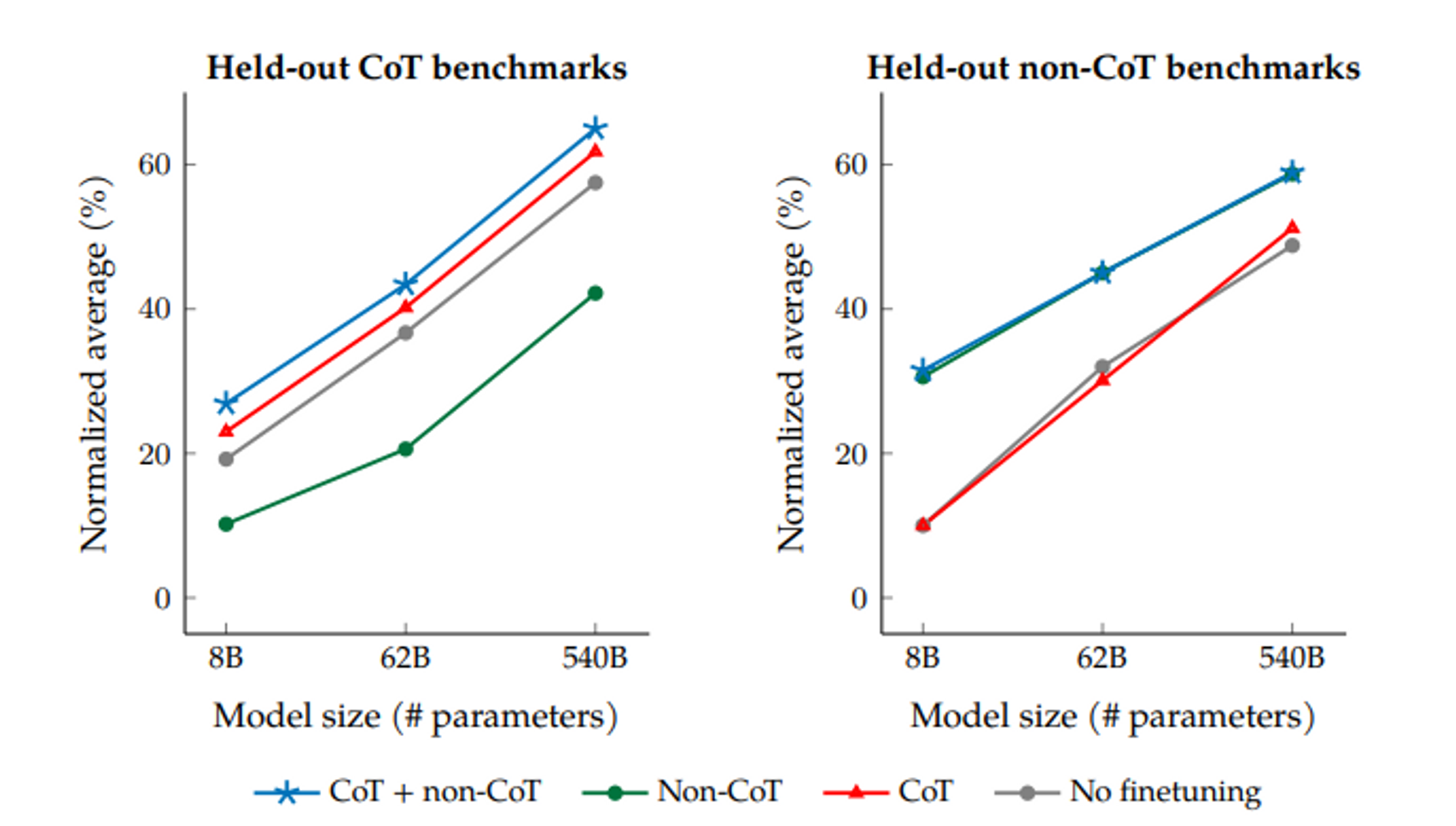
좌측 박스를 보면 CoT 벤치마크로 evaluation을 진행했을 때, 파인튜닝을 아예 진행하지 않은 모델이 CoT포맷을 제외하여 튜닝을 진행한 모델보다 성능이 좋게 나타났습니다.
CoT포맷으로만 튜닝을 진행한 모델의 경우 non-CoT 튜닝보다 성능이 더 좋네요. 여기서 주목할 점은 제가 처음에 이전 연구에서 강조했던 부분과 이어집니다.
이전 연구에서는 "instruction tuning은 unseen task에서의 성능을 향상시킨다."고 밝혔습니다.
초록색 선은 cot포맷의 데이터는 제외되어있지만 instruction tuning을 진행한 모델입니다. 그럼에도 모든 모델 스케일 범주에서 instruction tuning을 진행하지 않은 모델보다 성능이 낮습니다. 이전 연구와 대조적인 결과네요.
우측과 좌측 박스 모두에서 CoT 포맷과 non-CoT 포맷 모두를 사용하여 튜닝을 진행한 모델이 모든 모델 사이즈에서 우세한 성능을 보였습니다. 결국 3번 주제에 대한 답은 모델 능력 향상에는 non-CoT데이터와 CoT 데이터 모두가 필요하다는 결론으로 귀결됩니다.
instruction tuning 관련 논문 리뷰를 마무리하겠습니다. 많이 돌아갔네요.. (^_ㅠ) 다음 글에서는 LLaMA 논문을 리뷰하도록 하겠습니다.
