오랜만에 하는 포스팅.
개강을 하고 이것저것 벌려놓은 일이 많아서 열심히 수습 중이다.
올해는 뭐라도 저지르자가 목표였는데 그와 동시에 잘 수습하자는 목표가 생겼다.
교내 동아리 GDSC의 인공지능 스터디에 참여하게 되어 매주 포스팅할 예정.
개강 첫 포스팅으로 Pandas에 대해 작성해보았다.
import pandas as pd1. DataFrame - Pandas가 다루는 데이터의 종류
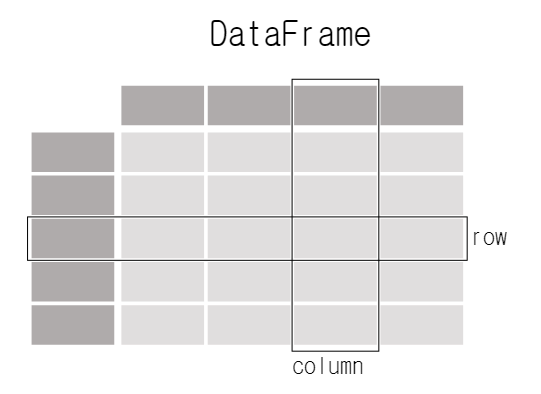
In [2]: df = pd.DataFrame(
...: {
...: "Name": [
...: "Braund, Mr. Owen Harris",
...: "Allen, Mr. William Henry",
...: "Bonnell, Miss. Elizabeth",
...: ],
...: "Age": [22, 35, 58],
...: "Sex": ["male", "male", "female"],
...: }
...: )
Out[3]:
Name Age Sex
0 Braund, Mr. Owen Harris 22 male
1 Allen, Mr. William Henry 35 male
2 Bonnell, Miss. Elizabeth 58 female- 2차원 데이터 구조
- spreadsheet, SQL table 등과 비슷
- DataFrame의 각 열 =
Series
Series

In [4]: df["Age"]
Out[4]:
0 22
1 35
2 58
Name: Age, dtype: int64DataFrame의 열은 Pandas의 Series 형식으로 출력된다.
아래와 같이 Series를 생성할 수 있다.
In [5]: ages = pd.Series([22, 35, 58], name="Age")
Out[6]:
0 22
1 35
2 58
Name: Age, dtype: int64Series는 column labels를 갖지 않고 row labels를 가진다.
df["Age"].max()
ages.max()In [9]: df.describe()
Out[9]:
Age
count 3.000000
mean 38.333333
std 18.230012
min 22.000000
25% 28.500000
50% 35.000000
75% 46.500000
max 58.000000Pandas의 대부분은 DataFrame이나 Series를 반환한다.
2. Tabular data를 읽고 쓰는 방법

read_*: read data to pandas
to_*: store data
titanic = pd.read_csv("data/titanic.csv")csv 외에도 excel, sql, json 등을 read_*로 읽을 수 있다.
In [3]: titanic
Out[3]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
.. ... ... ... ... ... ... ...
886 887 0 2 ... 13.0000 NaN S
887 888 1 1 ... 30.0000 B42 S
888 889 0 3 ... 23.4500 NaN S
889 890 1 1 ... 30.0000 C148 C
890 891 0 3 ... 7.7500 NaN Q
[891 rows x 12 columns]DataFrame은 default로 처음과 마지막 5행이 보여진다.
처음 또는 끝의 n행 을 확인하고 싶다면 아래와 같이 작성한다.
titanic.head(n)
titanic.tail(n)각 열의 타입을 확인하고 싶다면 dtypes() 사용하기
In [5]: titanic.dtypes
Out[5]:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object여기서 object는 string을 의미한다.
데이터를 spreadsheet로 변환하는 방법은 to_*()
titanic.to_excel("titanic.xlsx", sheet_name="passengers", index=False)index=False : row index label이 저장되지 않음.
DataFrame의 technical summary 확인할 때는 info() 사용.
In [9]: titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB3. DataFrame 일부 선택하기
특정 열 선택하기
single columns
titanic[col1]
return type : Series (1차원)
titanic["Age"].shape # (891,)multiple columns
titanic[[col1, col2]]
inner [ ] : python list
outer [ ] : selecting data
return type : DataFrame
titanic[["Age", "Sex"]].shape # (891, 2)특정 행 선택하기
titanic[inner_condition] : inner condition이 True인 행만 출력.
ex) titanic[titanic["Age"] > 35]
In [14]: titanic["Age"] > 35
Out[14]:
0 False
1 True
2 False
3 False
4 False
...
886 False
887 False
888 False
889 False
890 False
Name: Age, Length: 891, dtype: boolPclass 열의 값이 2 또는 3인 행 선택할 때는 DataFrame.isin() 사용.
In [16]: class_23 = titanic[titanic["Pclass"].isin([2, 3])]
In [17]: class_23.head()
Out[17]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
2 3 1 3 ... 7.9250 NaN S
4 5 0 3 ... 8.0500 NaN S
5 6 0 3 ... 8.4583 NaN Q
7 8 0 3 ... 21.0750 NaN S
[5 rows x 12 columns]= titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
Age 열의 값이 Null이 아닌 행을 선택할 때는 notna()
In [20]: age_no_na = titanic[titanic["Age"].notna()]
In [21]: age_no_na.head()
Out[21]:
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]특정 열과 행 선택하기
loc[선택할 행, 선택할 열]
iloc[9:25, 2:5]
아래와 같이 새로운 값 할당도 가능.
titanic.iloc[0:3, 3] = “anonymous”4. 새로운 열 추가하기
그냥 새로 선언해주면 된다.
air_quality[new_columns_name] = air_quality[existing_columns] * 123
air_quality[new_col] = (
air_quality[exist_col1] / air_quality[exist_col2]
)추가 심화 로직은 python의 DataFrame.apply(func, axis,) 사용.
func : numpy가 제공하는 함수, lambda 함수, 사용자 지정 함수 등
apply(np.int64)로 데이터 타입을 변경할 수도 있다. astype()을 쓰는 방법도 있음.
열 이름 바꾸기
df.columns = ['a', 'b']
또는
rename(columns)
air_quality_renamed = air_quality.rename(
columns={
old1 : new1
old2 : new2
old3 : new3
}
)
air_quality_renamed = air_quality.rename(columns=str.lower)5. 통계 계산하기
titanic["Age"].mean()titanic[["Age", "Fare"]].median()titanic[["Age", "Fare"]].describe()In [7]: titanic.agg(
...: {
...: "Age": ["min", "max", "median", "skew"],
...: "Fare": ["min", "max", "median", "mean"],
...: }
...: )
...:
Out[7]:
Age Fare
min 0.420000 0.000000
max 80.000000 512.329200
median 28.000000 14.454200
skew 0.389108 NaN
mean NaN 32.204208그룹화 이용하기
groupby()
- Split the data into groups
- Apply a function to each group independently
& Combine the results into a data structure
In [8]: titanic[["Sex", "Age"]].groupby("Sex").mean()
Out[8]:
Age
Sex
female 27.915709
male 30.726645In [10]: titanic.groupby("Sex")["Age"].mean()
Out[10]:
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64In [11]: titanic.groupby(["Sex", "Pclass"])["Fare"].mean()
Out[11]:
Sex Pclass
female 1 106.125798
2 21.970121
3 16.118810
male 1 67.226127
2 19.741782
3 12.661633
Name: Fare, dtype: float64각 범주의 레코드 개수 세기
value_counts()
In [12]: titanic["Pclass"].value_counts()
Out[12]:
3 491
1 216
2 184
Name: Pclass, dtype: int64열 별로 개수를 센다.
위 코드는 사실 아래의 코드의 지름길.
count()
In [13]: titanic.groupby("Pclass")["Pclass"].count()
Out[13]:
Pclass
1 216
2 184
3 491
Name: Pclass, dtype: int64size와 count가 비슷해 보이지만,
size는 NaN을 포함하고(=테이블의 사이즈), count는 NaN을 포함하지 않는다.
6. 테이블 레이아웃 reshape
정렬하기
sort_values()
titanic.sort_values(by="Age")
titanic.sort_values(by=['Pclass', 'Age'], ascending=False)reshape long → wide (pivot)
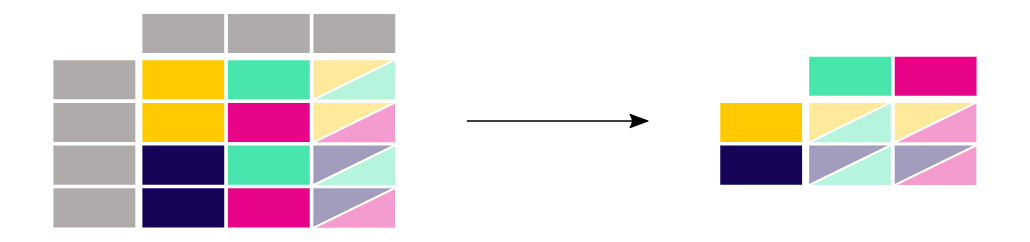
DataFrame.pivot()
In [11]: no2_subset.pivot(columns="location", values="value")
Out[11]:
location BETR801 FR04014 London Westminster
date.utc
2019-04-09 01:00:00+00:00 22.5 24.4 NaN
2019-04-09 02:00:00+00:00 53.5 27.4 67.0
2019-04-09 03:00:00+00:00 NaN NaN 67.0index 파라미터가 정의되지 않았다면 row label이 사용된다.
pandas.pivot_table()
pivot()은 데이터를 단순히 rearrange했다면, pivot_table()은 여러 값들이 aggregate되어야 할 때 사용된다.
In [14]: air_quality.pivot_table(
....: values="value", index="location", columns="parameter", aggfunc="mean"
....: )
Out[14]:
parameter no2 pm25
location
BETR801 26.950920 23.169492
FR04014 29.374284 NaN
London Westminster 29.740050 13.443568In [15]: air_quality.pivot_table(
....: values="value", index="location", columns="parameter", aggfunc="mean",
....: margins=True
....: )
Out[15]:
parameter no2 pm25 All
location
BETR801 26.950920 23.169492 24.982353
FR04014 29.374284 NaN 29.374284
London Westminster 29.740050 13.443568 21.491708
All 29.430316 14.386849 24.222743margins = True를 지정하면 행과 열 별로 계산을 수행한다.
reshape wide → long (melt)

DataFrame.melt(id_vars, value_vars, value_name, var_name,)
In [18]: no_2 = no2_pivoted.melt(id_vars="date.utc")
Out[19]:
date.utc location value
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5열의 헤더 → 변수 이름
가장 끝의 열은 디폴트로 value라는 이름을 가진다.
In [20]: no_2 = no2_pivoted.melt(
....: id_vars="date.utc",
....: value_vars=["BETR801", "FR04014", "London Westminster"],
....: value_name="NO_2",
....: var_name="id_location",
....: )
Out[21]:
date.utc id_location NO_2
0 2019-04-09 01:00:00+00:00 BETR801 22.5
1 2019-04-09 02:00:00+00:00 BETR801 53.5
2 2019-04-09 03:00:00+00:00 BETR801 54.5
3 2019-04-09 04:00:00+00:00 BETR801 34.5
4 2019-04-09 05:00:00+00:00 BETR801 46.5value_vars: melt될 열value_name: value 자리를 지정할 열의 이름, default - valuevar_name: 열의 헤더 이름을 모은 열의 이름, default - index name of variable
⇒ value_name , var_name : 유저가 정의한 이름
⇒ id_vars , value_vars : melt될 열
7. 테이블 합치기
pandas.concat(objs, axis, keys,)
air_quality = pd.concat([df1, df2], axis=0)axis=0 : combine the rows (default)
axis=1 : combine the columns
In [15]: air_quality_ = pd.concat([air_pm25, air_no2], keys=["PM25", "NO2"])
In [16]: air_quality_.head()
Out[16]:
date.utc location parameter value
PM25 0 2019-06-18 06:00:00+00:00 BETR801 pm25 18.0
1 2019-06-17 08:00:00+00:00 BETR801 pm25 6.5
2 2019-06-17 07:00:00+00:00 BETR801 pm25 18.5
3 2019-06-17 06:00:00+00:00 BETR801 pm25 16.0
4 2019-06-17 05:00:00+00:00 BETR801 pm25 7.5pandas.merge()
DataBase의 join과 비슷.
In [20]: air_quality = pd.merge(air_quality, stations_coord, how="left", on="location")
In [21]: air_quality.head()
Out[21]:
date.utc ... coordinates.longitude
0 2019-05-07 01:00:00+00:00 ... -0.13193
1 2019-05-07 01:00:00+00:00 ... 2.39390
2 2019-05-07 01:00:00+00:00 ... 2.39390
3 2019-05-07 01:00:00+00:00 ... 4.43182
4 2019-05-07 01:00:00+00:00 ... 4.43182
[5 rows x 6 columns]how = "left" : 좌측 열인 air_quality의 location 열을 기준으로 조인, default - ‘inner’ {’left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}
참고로 left는 왼쪽 열을 기준으로 join하고, inner는 두 데이터 모두 포함하는 값만 가져온다. 이 한 끗 차이로 결과가 달라지는 듯.
on : join할 열
In [24]: air_quality = pd.merge(air_quality, air_quality_parameters,
....: how='left', left_on='parameter', right_on='id')
....:
In [25]: air_quality.head()
Out[25]:
date.utc ... name
0 2019-05-07 01:00:00+00:00 ... NO2
1 2019-05-07 01:00:00+00:00 ... NO2
2 2019-05-07 01:00:00+00:00 ... NO2
3 2019-05-07 01:00:00+00:00 ... PM2.5
4 2019-05-07 01:00:00+00:00 ... NO2
[5 rows x 9 columns]left_on : air_quality의 merge 대상 열
right_on : air_quality_parameters의 merge 대상 열
merge할 두 열의 이름이 다를 때 사용한다.
8. 시간 데이터 관리하기
datetime
pd.to_datetime() : string to datetime (pandas.Timestamp)
pd.read_csv("../data/air_quality_no2_long.csv", parse_dates=["datetime"])와 같이, 읽을 때 date를 형성할 수도 있다.
dt accessor를 사용하여 min(), max(), 뺄셈 등의 계산 적용이 가능해 유용하다.
air_quality["month"] = air_quality["datetime"].dt.month로 month에만 접근할 수도 있다. hour, day, second, weekday 등.
DatetimeIndex
In [18]: no_2 = air_quality.pivot(index="datetime", columns="location", values="value")
In [19]: no_2.head()
Out[19]:
location BETR801 FR04014 London Westminster
datetime
2019-05-07 01:00:00+00:00 50.5 25.0 23.0
2019-05-07 02:00:00+00:00 45.0 27.7 19.0
2019-05-07 03:00:00+00:00 NaN 50.4 19.0
2019-05-07 04:00:00+00:00 NaN 61.9 16.0
2019-05-07 05:00:00+00:00 NaN 72.4 NaNdt accessor 필요없다.
In [20]: no_2.index.year, no_2.index.weekday
Out[20]:
(Int64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
...
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='datetime', length=1033),
Int64Index([1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
3, 3, 3, 3, 3, 3, 3, 3, 3, 4],
dtype='int64', name='datetime', length=1033))resample()
- time-based 그룹화 (M, D, 5H 등)
- aggregation function(
mean,max…)를 요구
9. textual data 다루기
string type에 적용되므로 str accessor 필요.
str.lower()
titanic["Name"].str.lower()element-wise하게 적용
str.split()
titanic["Name"].str.split(",").str.get(0)str.contains()
해당 문자를 포함하는지 안 하는지
return type : boolean
str.len()
titanic["Name"].str.len().idxmax()로 최대 길이의 이름을 가진 index 출력.
replace({from:to})
titanic["Sex"].replace({'male' : 'M', 'female' : 'F'})+) 추가
DataFrame.isna()
Null의 개수 구하기
DataFrame.drop(columns)
해당 열 삭제하기
DataFrame.copy(deep)
데이터프레임 복사하기
deep = True : deep copy, 원본과 별개인 복사본 생성 (default)
deep = False : shallow copy, 원본이 수정되면 사본도 수정됨, 반대도 마찬가지
