
개발을 하다 보면 단순히 쿼리튜닝만으로 해결할 수 없는 경우가 있다. 이런 경우는
- 캐시를 둔다
- 더 작은 테이블로 분할한다
같은 방법으로 해결하게 된다. 하지만 1번의 경우 추가적인 개발 공수가 필요하고 여러 건을 읽어오는 경우 구현하기 어렵거나 캐시 히트율이 매우 떨어져 비효율적인 선택이 되고는 한다.
시간을 되돌려 좋았던 시절을 떠올려보자. 테이블을 풀스캔해도 아무런 성능 문제가 없던, 비즈니스의 초창기말이다. 데이터 자체가 적었기 때문에 모든 쿼리가 빠르게 실행되었다. 이제와서 우리 데이터를 적게 사용할 수 있을까?
가능하다. 테이블을 파티셔닝한다면 말이다.
테이블 파티셔닝
PostgreSQL의 테이블 파티셔닝은 다음과 같이 두 가지 방법으로 나눌 수 있다.
- 상속 파티셔닝 (Partitioning Using Inheritance)
- 선언적 파티셔닝 (Declarative Partitioning)
원래 PostgreSQL 상속을 활용한 파티셔닝을 이용했으나, PostgreSQL 10 이후로는 선언적 파티셔팅을 통해 좀 더 쉽게 테이블 파티셔닝을 구현할 수 있다. 이 글에서는 2, 선언적 파티셔닝에 대해서만 다룬다.
데이터 준비
version: "3.7"
services:
postgres:
image: postgres:13.5
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=github-actions
ports:
- "5432:5432"위와 같이 실습을 위한 DB를 간단히 구성해두자.
CREATE TABLE tokens
(
id SERIAL PRIMARY KEY,
code VARCHAR(32) NOT NULL,
created_at TIMESTAMP WITH TIME ZONE NOT NULL,
confirmed_at TIMESTAMP WITH TIME ZONE,
PRIMARY KEY (id, created_at)
) PARTITION BY RANGE (created_at);위와 같이 파티션될 테이블을 생성하자.
-- Generate default partition
CREATE TABLE tokens_default
PARTITION OF tokens
DEFAULT;
-- Generate partition for 2023
CREATE TABLE tokens_2023
PARTITION OF tokens
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- Generate partition for 2022
CREATE TABLE tokens_2022
PARTITION OF tokens
FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');이렇게 선언함으로써 파티션을 생성했다. 다음과 같이 이제 단순한 스크립트로 데이터를 밀어넣자.
-- Insert 1M rows
DO $$
DECLARE
i INT := 1;
random_code VARCHAR(32);
random_date TIMESTAMP;
BEGIN
FOR i IN 1..1000000 LOOP
-- Generate random code
random_code := md5(random()::text);
-- Generate random date between '2022-01-01' and now
random_date := timestamp '2022-01-01' + random() * (NOW() - timestamp '2022-01-01');
-- Insert into tokens table
INSERT INTO tokens (code, created_at) VALUES (random_code, random_date);
-- Print progress every 10000 rows
IF i % 10000 = 0 THEN
RAISE NOTICE 'Inserted % rows out of 1000000', i;
END IF;
END LOOP;
END $$;결과 확인
이제 실제 쿼리를 날려보며 결과를 확인해보자.
SELECT * FROM tokens WHERE id = 1024;위 쿼리는 잘 실행되고, 실행 플랜을 확인하면

이렇게 세 개의 파티셔닝된 테이블에서 읽어오는 것을 확인할 수 있다. 조건절에 쓰인 id로는 어떤 파티션인지 특정할 수 없기 때문이다. 그러면 파티션의 조건인 created_at을 쿼리에 추가해보자.
SELECT *
FROM tokens
WHERE
id = 1024
AND created_at > '2024-01-01';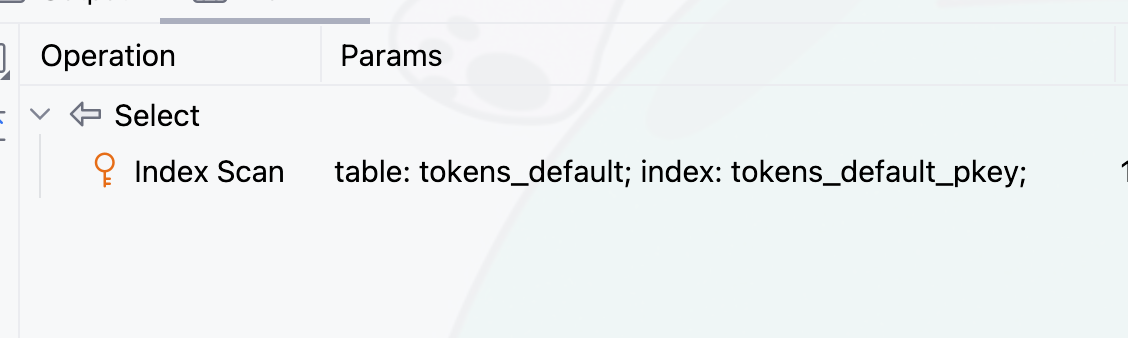
당연하지만, created_at을 통해 스캔할 파티션의 범위를 좁힐 수 있어 하나의 파티션만 확인했고 이에 따라 쿼리의 비용도 1/3으로 감소했다.
Dual Write
위의 과정을 통해 새로 생성하는 테이블은 파티셔닝을 잘 할 수 있었다. 하지만 다운타임 없이, 기존 테이블을 새 테이블로 옮겨야한다면 어떻게 잘 할 수 있을까? 양 쪽 테이블에 쓰기를 유지한 후 읽기를 전환하는 것이 자연스러운 흐름일 것이다.
그러면 다시 이중쓰기 전략은 두 가지로 나뉜다. 애플리케이션단에서 쓰기를 하든지 DB 단에서 이중 쓰기를 하든지. 여태까지는 개발자다보니 DB보다 애플리케이션 단에서 이중 쓰기를 하는 것에 익숙해져 있었다. 하지만 애플리케이션 단 이중 쓰기의 경우 코드의 복잡도를 증대시키고 전체적 오버헤드가 좀 더 심해지는 경향이 있다. 따라서 DB에서 트리거를 통해 작업을 처리할 줄도 알아야 한다.
앞선 상황을 조금 바꾸어, tokens_old 라는 테이블이 기존 테이블이고 이걸 새로 파티셔닝한 테이블인 tokens 라는 테이블에 이중 쓰기를 하고 싶다고 해보자. 문제를 단순화하기 위해 update는 없다고 가정한다.
우선 다음과 같이 아까의 데이터를 정리하자.
DROP TABLE tokens;CREATE TABLE tokens_old
(
id SERIAL,
code VARCHAR(32) NOT NULL,
created_at TIMESTAMP WITH TIME ZONE NOT NULL,
confirmed_at TIMESTAMP WITH TIME ZONE,
PRIMARY KEY (id)
);비슷하게, 옛날 테이블에 데이터를 인입하자.
-- Insert 1M rows to old table
DO
$$
DECLARE
i INT := 1;
random_code VARCHAR(32);
random_date TIMESTAMP;
BEGIN
FOR i IN 1..1000000
LOOP
-- Generate random code
random_code := MD5(RANDOM()::TEXT);
-- Generate random date between '2022-01-01' and now
random_date := TIMESTAMP '2022-01-01' + RANDOM() * (NOW() - TIMESTAMP '2022-01-01');
-- Insert into tokens table
INSERT INTO tokens_old (code, created_at) VALUES (random_code, random_date);
-- Print progress every 10000 rows
IF i % 10000 = 0 THEN
RAISE NOTICE 'Inserted % rows out of 1000000', i;
END IF;
END LOOP;
END
$$;
CREATE TABLE tokens
(
id SERIAL,
code VARCHAR(32) NOT NULL,
created_at TIMESTAMP WITH TIME ZONE NOT NULL,
confirmed_at TIMESTAMP WITH TIME ZONE,
PRIMARY KEY (id, created_at)
) PARTITION BY RANGE (created_at);
-- Generate default partition
CREATE TABLE tokens_default
PARTITION OF tokens
DEFAULT;
-- Generate partition for 2023
CREATE TABLE tokens_2023
PARTITION OF tokens
FOR VALUES FROM ('2023-01-01') TO ('2024-01-01');
-- Generate partition for 2022
CREATE TABLE tokens_2022
PARTITION OF tokens
FOR VALUES FROM ('2022-01-01') TO ('2023-01-01');새 테이블을 준비해두자.
SELECT
(select count(*) from tokens_old) as old_table_count,
(select count(*) from tokens) as new_table_count;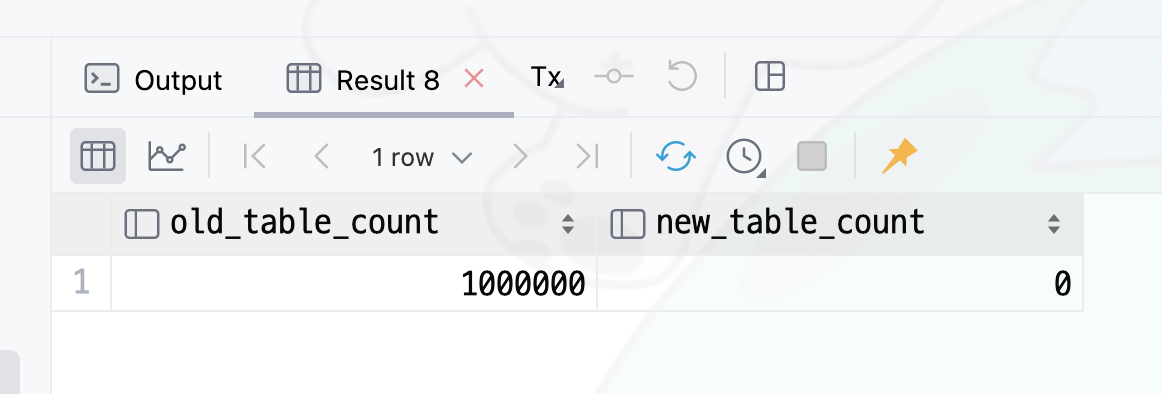
쿼리로 확인해보면 개수가 다르게 잘 들어간 것을 볼 수 있다.
이제 트리거를 만들고 등록해보자.
-- Create dual write function
CREATE OR REPLACE FUNCTION dual_write_token()
RETURNS TRIGGER AS
$$
BEGIN
INSERT INTO tokens VALUES (NEW.*);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- Attach function to old table
CREATE TRIGGER dual_write_token_trigger
AFTER INSERT
ON tokens_old
FOR EACH ROW
EXECUTE FUNCTION dual_write_token();이제 Insert를 하며 잘 동작하는지 검증해보자.
-- Insert record for test
INSERT INTO
tokens_old (code, created_at)
VALUES
('test', NOW());
-- Check if record is in both tables
SELECT *
FROM tokens_old, tokens
WHERE tokens_old.code = 'test';
결과를 잘 검증했다. 이제 기존 데이터를 복사하자.
-- Copy data from old table to new table
INSERT INTO
tokens (id, code, created_at, confirmed_at)
SELECT
id,
code,
created_at,
confirmed_at
FROM tokens_old
ON CONFLICT DO NOTHING;Dual write로 인해 이미 new table에 적재된 레코드가 있을 수 있어 충돌 시에는 아무것도 하지 않도록 해야한다.
이 과정을 마치고 나면 둘의 싱크가 맞는 상태이다. 이제 읽기를 전환한 후에 기존 테이블과 트리거를 모두 제거하면 마이그레이션도 끝이 난다.
참고문헌
