
썸네일이미지 출처: http://www.topstarnews.net/news/articleView.html?idxno=852600
각설하고 바로 이어가겠다.
02 본격적인 코드
3) 이제부터
: 이전 포스팅에서까지 url을 뽑았다. 이제부터는 구체적인 전략을 말하겠다.
- 해당 영화 url에서 댓글, 날짜, 사용자 크롤링 예정
- 댓글 페이지 수에 따른 구분
# 원하는 댓글 페이지 수가 10개이하일 때와
# 10~ 20개 이상일 때 그리고
# 20개 이상일 때로 나눈다.- 댓글 페이지 수에 따른 구분 사유
# '다음10개' 버튼의 xpath 가 다르다.
# 처음 page 1 ~10 옆의 xpath 값의 뒤쪽의 숫자가 11인데
# page 11 ~20 , page 21 ~30, ... 등 옆의 '다음 10개'의 xpath 숫자가 13이다.- 구체적인 전략
# 원하는 댓글 페이지의 숫자가 10단위로 끝나지 않기 때문에 다음과 같이 나눌 것이다.
# end_page_num = 자신이 원하는 댓글 페이지 숫자# 예시
end_page_num = 56
moc = end_page_num // 10 # moc = 5
rest = end_page_num % 10 # rest = 6- 상세
# moc == 0 인 경우
# page 1 ~10일 때를 의미
# 자유롭게 댓글 페이지 크롤링 가능
# moc == 1
# 11 페이지부터 20페이지까지 크롤링 가능
# moc >= 2 인 경우
# 21 페이지부터 moc*10 페이지까지 모든 댓글 정보 크롤링 가능
# (moc*10 + rest) 페이지까지 크롤링4) 크롤링 페이지가 10page 이하인 경우
## moc < 0 인 경우
## 코드 재사용을 위해 함수화
## 리턴값은, 댓글별, 날짜별, 사용자별 리스트로
## 원하는 페이지부터 원하는 페이지까지 댓글 크롤링 가능한 함수
def cgv_rep_duc(n, m):
# page n ~ m까지 크롤링
# n, m 모두 1 이상, 10이하 숫자.
driver = webdriver.Chrome()
driver.get(movie_url)
# 이전 페이지 내용 참고: 영화 제목 검색으로 영화 상세 페이지 접속 url 크롤링
# movie_url = search_cgv(movie_name)
# movie_url로 cgv 영화 상세 페이지 접속
print("cgv 영화 상세 페이지 접속 ")
# 댓글을 담을 리스트
comment_list = []
# 사용자 정보를 담을 리스트
user_list = []
# 날자 리스트
date_list = []
# 원하는 페이지의 범위의 댓글을 for문으로 크롤링
for num in range(n, m+1):
# 영화 상세 페이지에서 댓글 페이지의 url을 url_n으로.
# 댓글 페이지마다 xpath 값 중 {} 위치의 숫자가 바뀐다.
# 아래처럼 for 문의 num이 들어오도록 설정.
url_n = '//*[@id="paging_point"]/li[{}]/a'.format(num)
driver.find_element_by_xpath(url_n).click()
print(f"댓글 {num}번째 page 접속 중") # 진행상황 보여주기
time.sleep(0.03)
# 비동기식 호출이라, 0.03초 대기.
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.box-comment p')))
# 댓글 크롤링 가능할 때까지, 최대 10초가지 기다리도록 하는 코드
print("댓글 로딩 기다리는 중") # 진행상황 보여주기
# time.sleep(0.03)
# 0.03초 대기를 줘도 되고 안 줘도 상관없다.
# 페이지 소스를 크롤링 할 수 있도록 함
src = driver.page_source
# BeautifulSoup으로 받는다.
soup = BeautifulSoup(src)
# 다음과 같이 해도 무방하다.
# soup = BeautifulSoup(src, 'html.parser')
# soup = BeautifulSoup(src, 'lxml')
print("댓글 크롤링") # 진행상황 보여주기
# comments
# 위 댓글 리스트에 댓글을 순서대로 담는 for 문이다.
# 댓글 페이지당 6개씩 담길 것이다.
for i in range(len(soup.select("div.box-comment p"))):
comment=soup.select("div.box-comment p")[i].get_text()
comment_list.append(comment)
# user
# 사용자 리스트에 사용자 정보를 순서대로 담는 for문
for j in range(len(soup.select("a.commentMore"))):
user = soup.select("a.commentMore")[j].text
user_list.append(user)
# date
# 날짜 리스트에 날짜를 순서대로 담는 for문
for k in range(len(soup.select("span.day"))):
yyyy, mm, dd = [int(x) for x in soup.select("span.day")[k].text.split(".")]
day_form = dt.date(yyyy, mm, dd)
date_list.append(day_form)
# 드라이버 종료
driver.quit()
print("완료 및 셀레니움 브라우저 종료")
# 위 리스트 3개를 반환.
return date_list, user_list, comment_list그래서 이 또한 테스트를 하면, 다음과 같다.

실제 CGV '블랙위도우' 댓글 페이지 1, 2를 보면
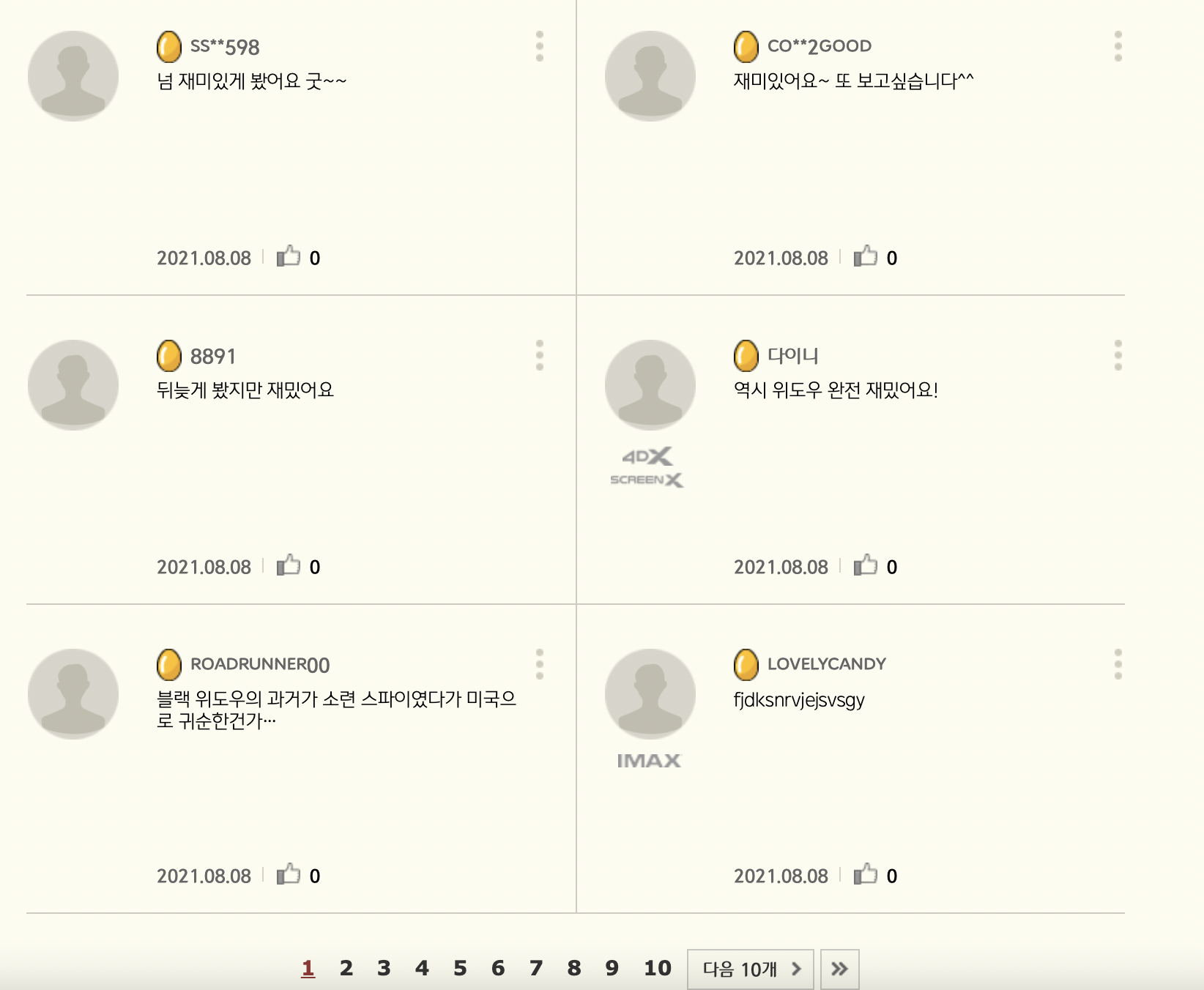
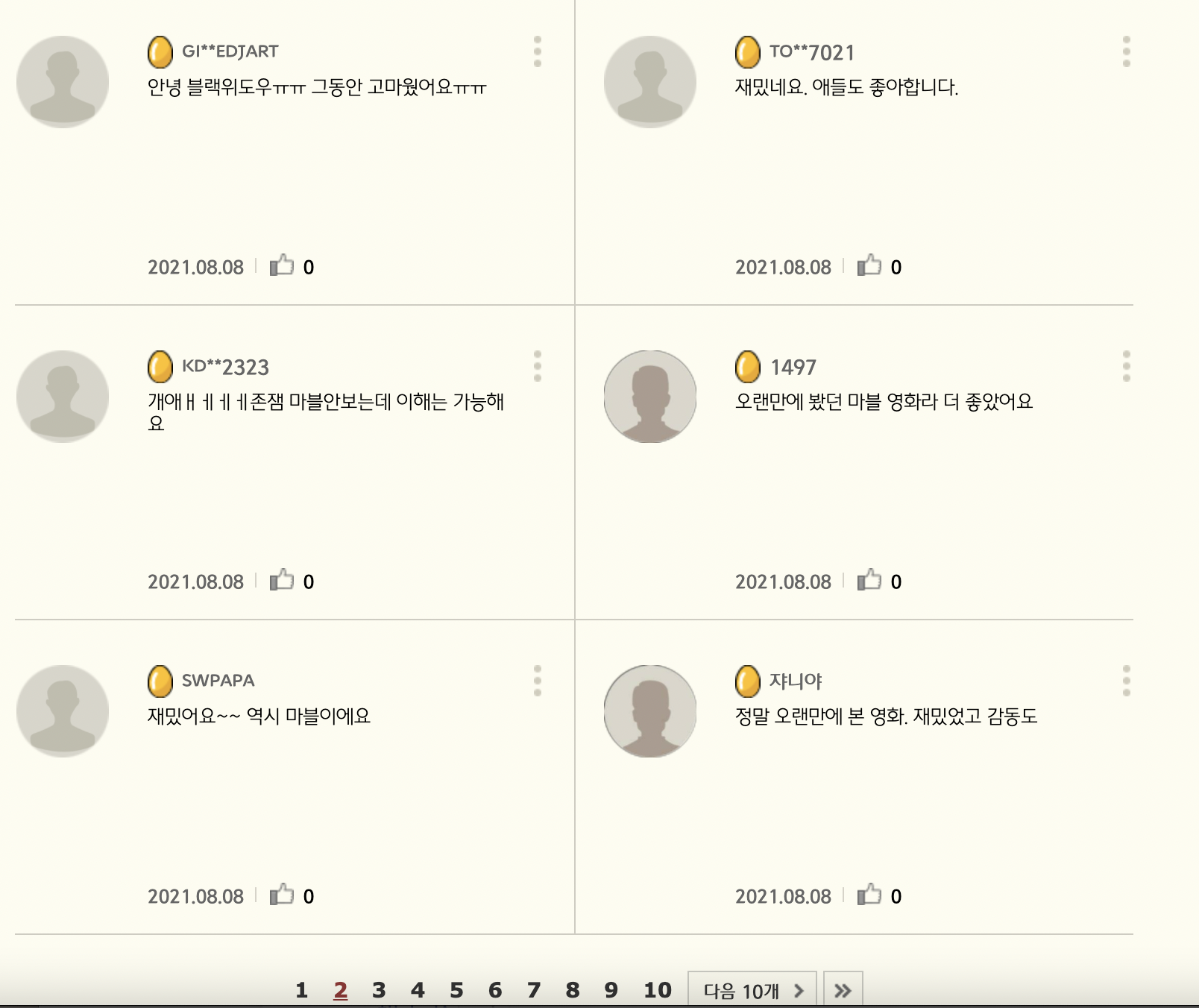
동일한 결과가 나온 것을 알 수 있다.
5) 크롤링 페이지가 11 ~ 20 이하인 경우
: 위 4번처럼 동일한 방식으로 코드를 짤 것이다. 자세한 설명 중 이전에 했던 설명과 중복되는 코드들은 생략하겠다.
## moc == 1 일 때
## page(10+n) ~ page(10+m)까지 크롤링 하는 코드
def cgv_rep_duc1(n, m):
driver = webdriver.Chrome()
driver.get(movie_url)
print("cgv 영화 정보 페이지 접속")
comment_list = []
user_list = []
date_list = []
url_11 = '//*[@id="paging_point"]/li[{}]/button'.format(11)
# 먼저 처음 '다음 10개'를 클릭하여 댓글 페이지 11 ~ 20 있는 곳으로 이동
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, url_11)))
pg_btn= driver.find_element_by_xpath(url_11)
pg_btn.click()
print("11번째 page 접속을 위해 최초 '다음 10개' 클릭 완료")
print()
time.sleep(0.03)
a = n+2
b = m+3
# xpath 값이 이전과는 다르게, 2씩 증가한다.
#'이전 10개' 버튼과 '처음으로' 버튼 때문에
# 따라서, 2씩 증가
# b의 경우, m+3인데 그 이유는 m+2+1 이기 때문이다.
# range 함수에서 마지막 숫자 포함안 되기 때문이다.
for num in range(a, b):
# 실제적으로는 page(10+n) ~ page(10+m)까지
url_n = '//*[@id="paging_point"]/li[{}]/a'.format(num)
driver.find_element_by_xpath(url_n).click()
# 실제적으로 10+n+num 페이지 접속 중
print(f"{num+10-2}번째 page 접속 중")
time.sleep(0.03)
# 이전과 동일
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.box-comment p')))
print("댓글 로딩 기다리는 중")
src = driver.page_source
soup = BeautifulSoup(src)
print("댓글 로딩 크롤링")
print()
# comments
for i in range(len(soup.select("div.box-comment p"))):
comment=soup.select("div.box-comment p")[i].get_text()
comment_list.append(comment)
# user
for j in range(len(soup.select("a.commentMore"))):
user = soup.select("a.commentMore")[j].text
user_list.append(user)
# date
for k in range(len(soup.select("span.day"))):
yyyy, mm, dd = [int(x) for x in soup.select("span.day")[k].text.split(".")]
day_form = dt.date(yyyy, mm, dd)
date_list.append(day_form)
driver.quit()
print("완료 및 셀리니움 크롬 브라우저 종료")
return date_list, user_list, comment_list
이 또한 테스트를 해보자.
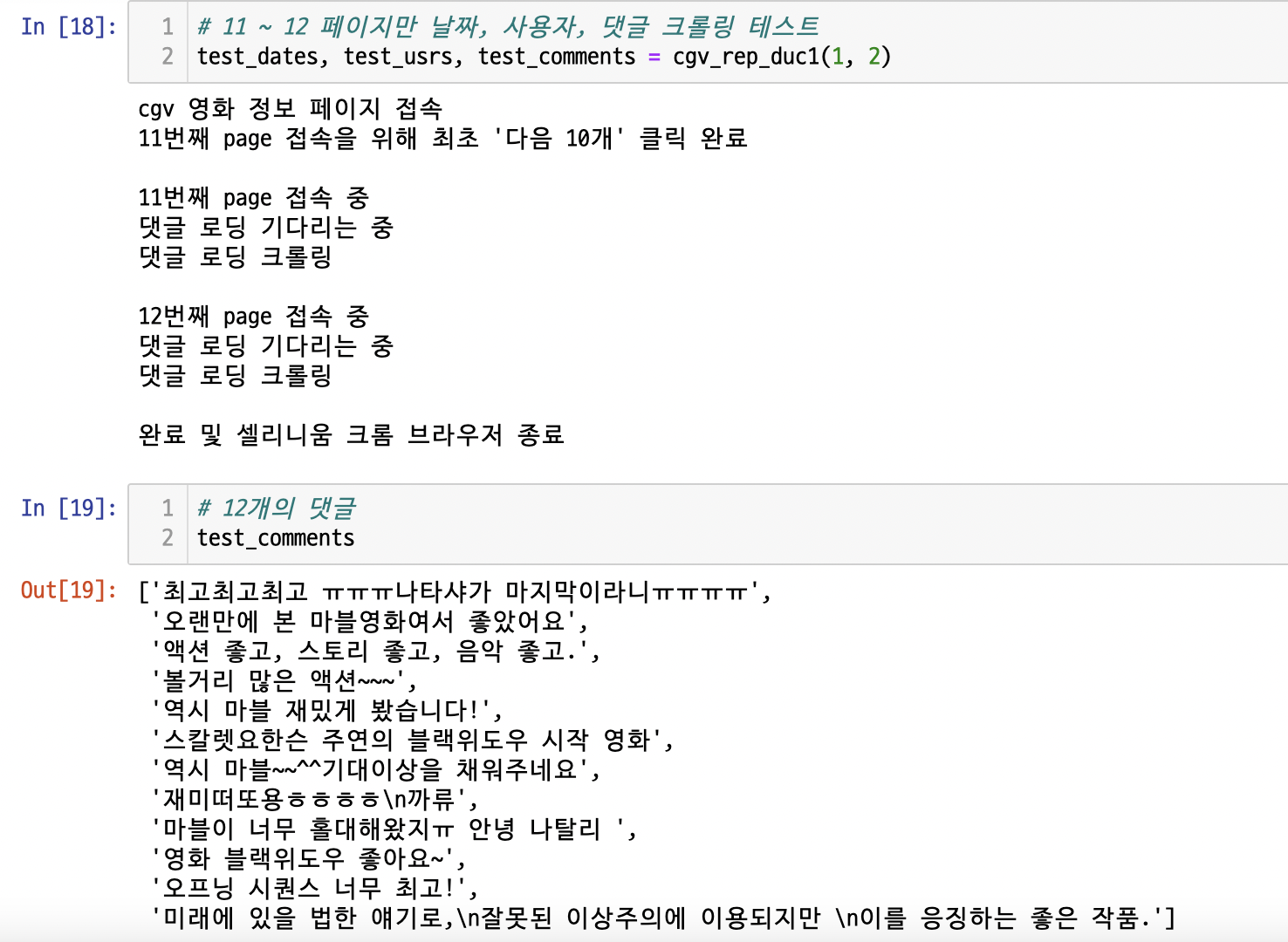
실제 해당 페이지를 조회하면,
(11 페이지는 생략 너무 스크롤압박이 생길 것 같아서, 12 페이지만)
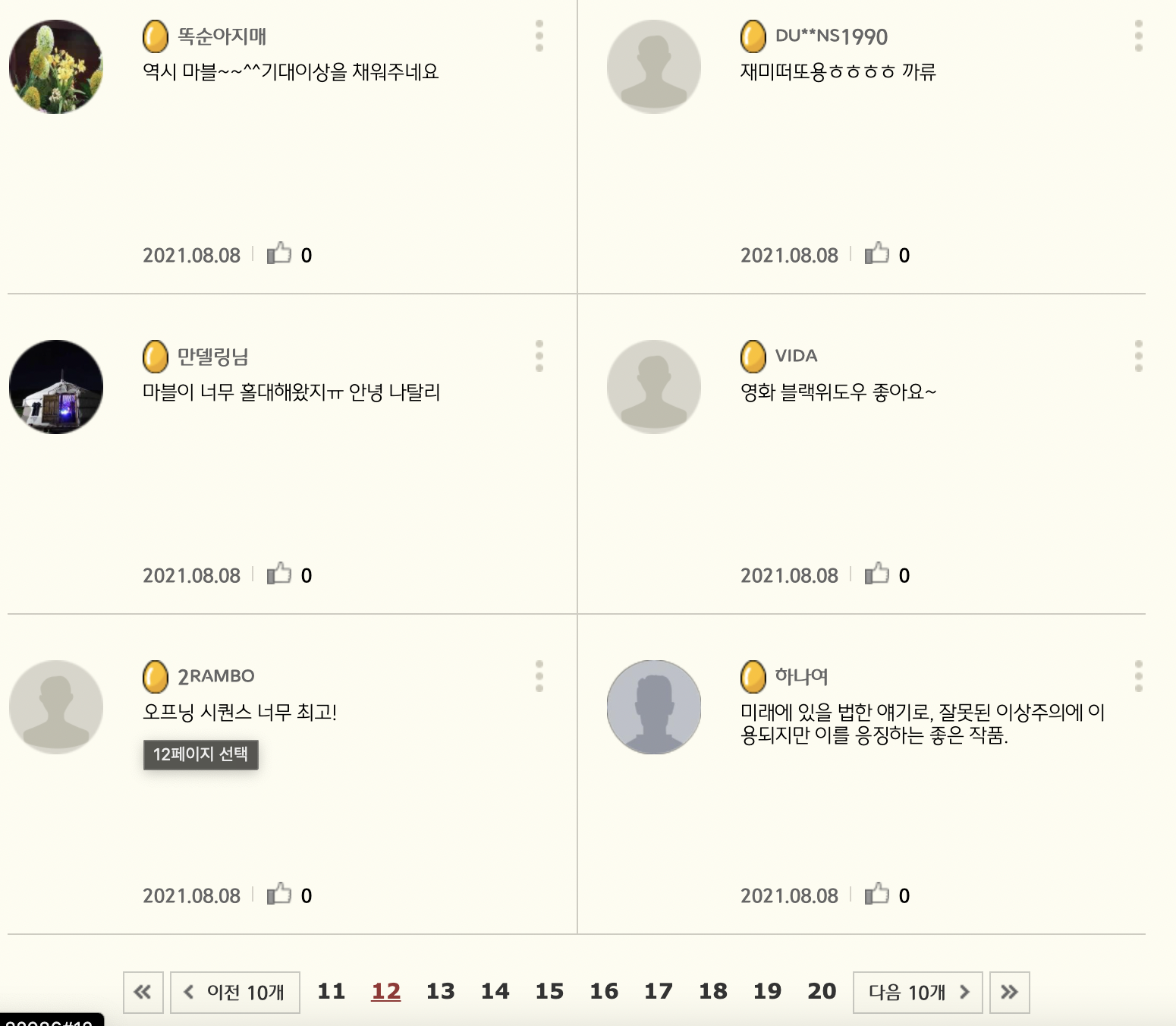
동일한 결과가 나온 것을 보면, 크롤링이 잘 된 것을 알 수 있다.
6) 크롤링 페이지가 20 이상일 때 - 몫
# moc >= 2 인 경우, page 21부터 moc*10 page까지의 댓글
def cgv_rep_duc_moc(moc):
# moc = end_page_num // 10
# moc으로 받는 함수를 작성
# 지금은 end_page_num 이 없으나 나중에 보일 것이다.
driver = webdriver.Chrome()
driver.get(movie_url)
print("cgv 영화 정보 페이지 접속")
comment_list = []
user_list = []
date_list = []
# 처음 '다음 10개' 의 xpath
url_11 = '//*[@id="paging_point"]/li[{}]/button'.format(11)
#2번째부터의 '다음 10개' 의 xpath
url_13 = '//*[@id="paging_point"]/li[{}]/button'.format(13)
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, url_11)))
pg_btn= driver.find_element_by_xpath(url_11)
pg_btn.click()
print("11번째 page 접속을 위해 최초 '다음 10개' 클릭 완료")
print()
time.sleep(0.01)
# 몫이 1인 경우는 댓글 페이지가 11 ~ 20까지 인 경우다.
# moc이 1인 경우는 아래 for문에 의하면,
# for times in range(1, 0)이 되어버리므로, 같이 구현이 힘들기에
# 이전 4)에서와 같이 따로 작성해둔 것이다.
for times in range(1, moc-1):
# 여기서부터는 2번째부터 '다음 10개' 버튼을 몫에 따라
# 얼마나 누를 지 작성한 for문.
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, url_13)))
pg_btn= driver.find_element_by_xpath(url_13)
pg_btn.click()
print(f"{(times+1)*10+1}번째 page 접속을 위해 {times+1}번째 '다음 10개' 클릭 완료")
print()
time.sleep(0.01)
# 이중 for문으로 각 몫에 해당한는 댓글 10페이지를 모두 크롤링.
for num in range(3, 13):
url_n = '//*[@id="paging_point"]/li[{}]/a'.format(num)
driver.find_element_by_xpath(url_n).click()
print(f"{times*10 + num+10-2}번째 page 접속 중")
time.sleep(0.03)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.box-comment p')))
print("댓글 로딩 기다리는 중")
src = driver.page_source
soup = BeautifulSoup(src)
print("댓글 로딩 크롤링")
print()
# comments
for i in range(len(soup.select("div.box-comment p"))):
comment=soup.select("div.box-comment p")[i].get_text()
comment_list.append(comment)
# user
for j in range(len(soup.select("a.commentMore"))):
user = soup.select("a.commentMore")[j].text
user_list.append(user)
# date
for k in range(len(soup.select("span.day"))):
yyyy, mm, dd = [int(x) for x in soup.select("span.day")[k].text.split(".")]
day_form = dt.date(yyyy, mm, dd)
date_list.append(day_form)
driver.quit()
print("완료 및 셀리니움 크롬 브라우저 종료")
return date_list, user_list, comment_list
이를 또 테스트해보자.

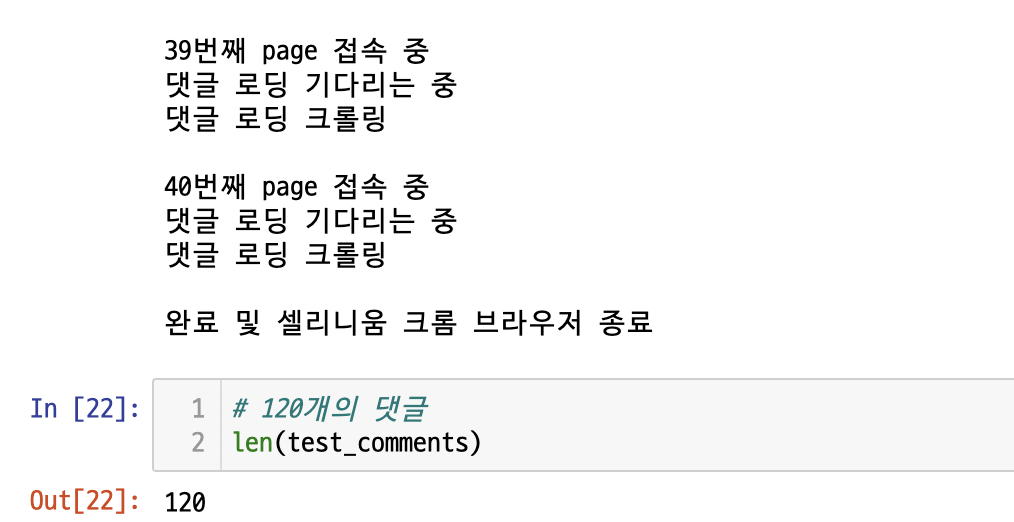
잘 된 것을 알 수 있다.
(댓글을 다 뽑기에도 애매해서, 생략하였다.)
7) 크롤링 페이지가 20 이상일 때 - 나머지
# moc>=2 인 경우, page (moc*10+1) 부터 page(moc*10 + rest) 값까지의 목록 긁어오는 코드
def cgv_rep_duc_rest(moc, n, m):
# rest는 어디값인지 알 수 없기에 n, m으로 먼저 받고 테스트.
# n = moc * 10 + 1
# m = moc * 10 + rest
driver = webdriver.Chrome()
driver.get(movie_url)
print("cgv 영화 정보 페이지 접속")
print()
comment_list = []
user_list = []
date_list = []
url_11 = '//*[@id="paging_point"]/li[{}]/button'.format(11)
url_13 = '//*[@id="paging_point"]/li[{}]/button'.format(13)
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, url_11)))
pg_btn= driver.find_element_by_xpath(url_11)
pg_btn.click()
print("최초 '다음 10개' 클릭 완료")
time.sleep(0.01)
for times in range(1, moc):
WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, url_13)))
pg_btn= driver.find_element_by_xpath(url_13)
pg_btn.click()
print(f"{times+1}번째 '다음 10개' 클릭 완료")
print()
time.sleep(0.01)
# moc*10+1 페이지부터 moc*10+rest 페이지까지 댓글 크롤링.
# 알겠지만, xpath 값 때문에 +2씩 추가.
# m+2+1 부분은 range 함수 특성상 마지막값 미포함하기 때문.
for num in range(n+2, m+2+1):
url_n = '//*[@id="paging_point"]/li[{}]/a'.format(num)
driver.find_element_by_xpath(url_n).click()
print(f"{moc*10 + num-2}번째 page 접속 중")
time.sleep(0.03)
print("댓글 로딩 기다리는 중")
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.box-comment p')))
print("댓글 로딩 크롤링")
print()
src = driver.page_source
soup = BeautifulSoup(src)
# comments
for i in range(len(soup.select("div.box-comment p"))):
comment=soup.select("div.box-comment p")[i].get_text()
comment_list.append(comment)
# user
for j in range(len(soup.select("a.commentMore"))):
user = soup.select("a.commentMore")[j].text
user_list.append(user)
# date
for k in range(len(soup.select("span.day"))):
yyyy, mm, dd = [int(x) for x in soup.select("span.day")[k].text.split(".")]
day_form = dt.date(yyyy, mm, dd)
date_list.append(day_form)
driver.quit()
print("완료 및 셀리니움 크롬 브라우저 종료")
return date_list, user_list, comment_list
테스트!


이번엔 CGV 댓글을 확인해보자
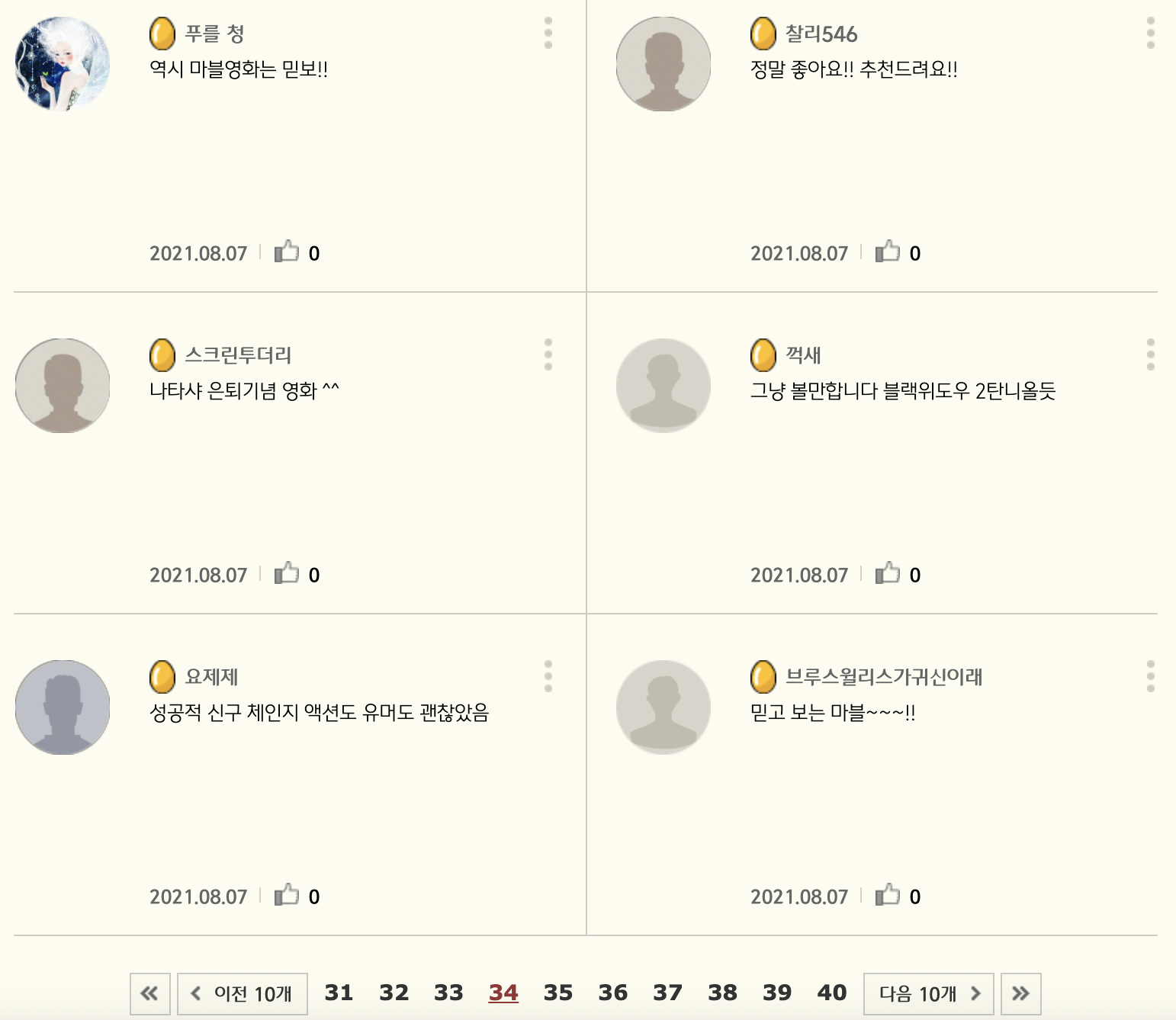
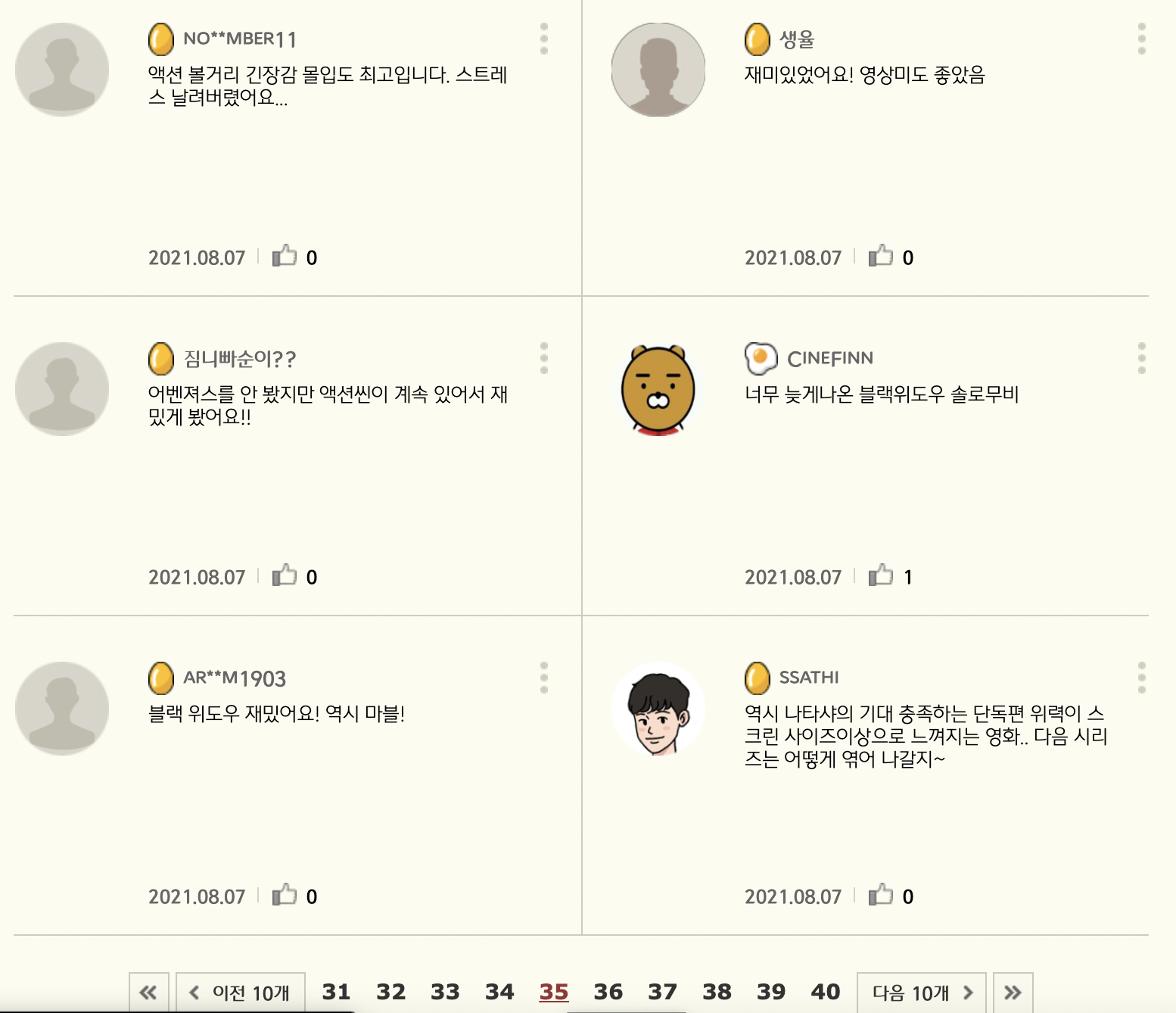
잘 된 것을 확인할 수 있다.
너무 글이 길어졌다.
다음 파트에서 마무리짓겠다.
: )

weird