
썸네일 이미지 출처: https://content.techgig.com/3-mini-project-ideas-for-computer-science-students/articleshow/78109217.cms
미니EDA 프로젝트 리뷰
지난 번 웹크롤링 Toy 프로젝트에 이어서 두 번째 프로젝트이다. EDA로서는 첫 프로젝티이기도 하다. 머신러닝을 이용하여 분석 및 예측까지 가지 않는, 데이터 전처리이전까지만 완료해도 되는 EDA 프로젝트이다.
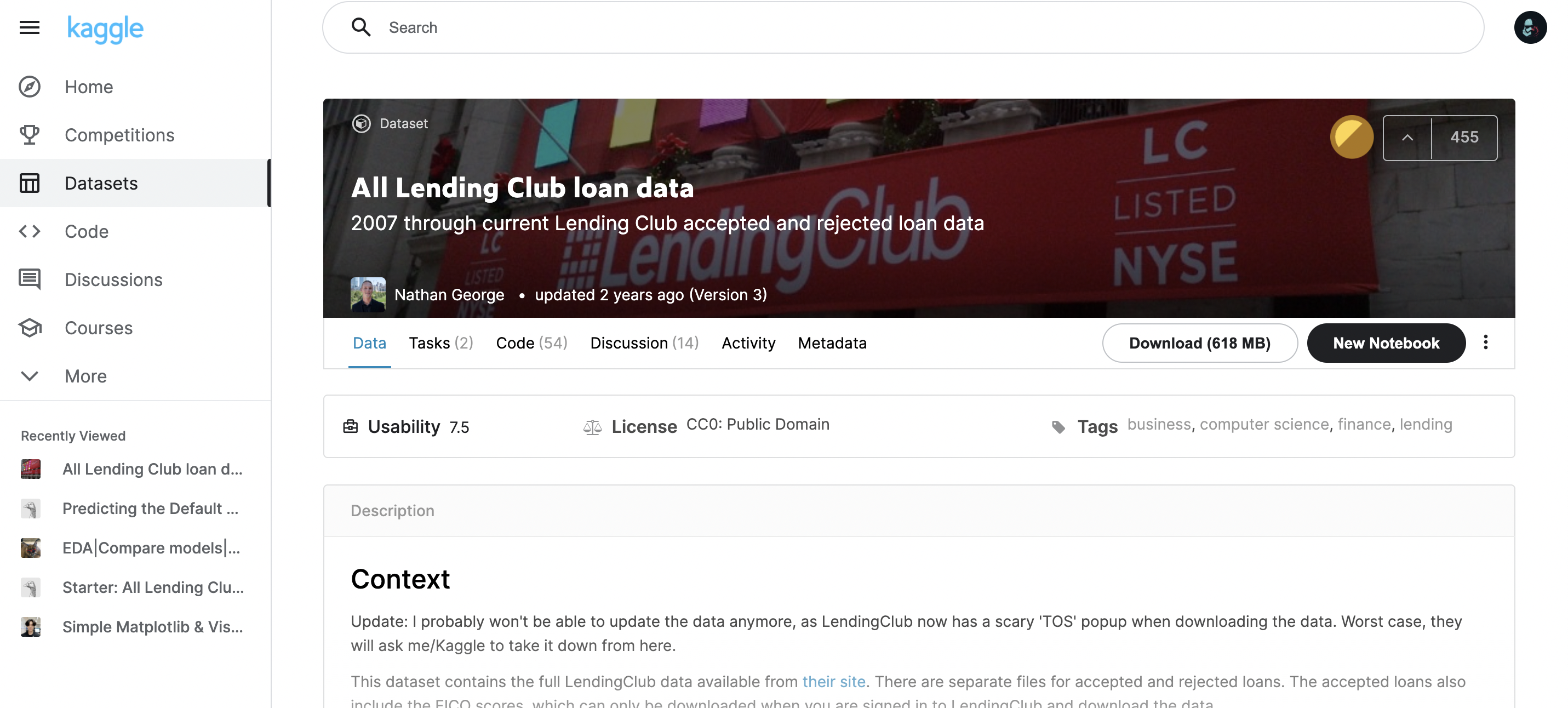
- Project: kaggle - All Lending Club loan data (사용자 대출 여부 예측 대회)
- 목표: EDA 를 통해 타겟과 상관관계가 있는 column 탐색
- IDE: GoogleColab
- 필자가 진행한 EDA Colab Notebook
- 참고한 EDA 노트
: 일부 코드필사 + 필자의 코드 - Google Drive 'Mount'
: 드라이브 마운트 방법 참고
예상을 못 했던
- 큰 용량의 데이터셋
: 데이터셋의 용량이 '618MB'라고 기재 되어있으나, 실제로 총 '2.5GB'를 훌쩍 넘는다. 그래서 Colab에서도 RAM이 자주 차서, '런타임 다시 시작'이 되거나 다운되거나 하였다. 필자의 경우, 그래서 중간중간에 데이터 중간결과물을 pd.to_csv() 코드로 csv 파일로 저장해두었다.
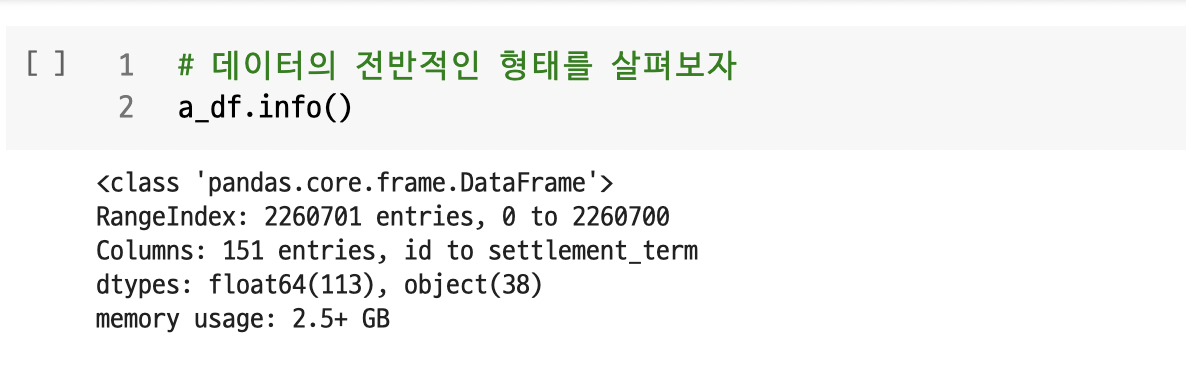
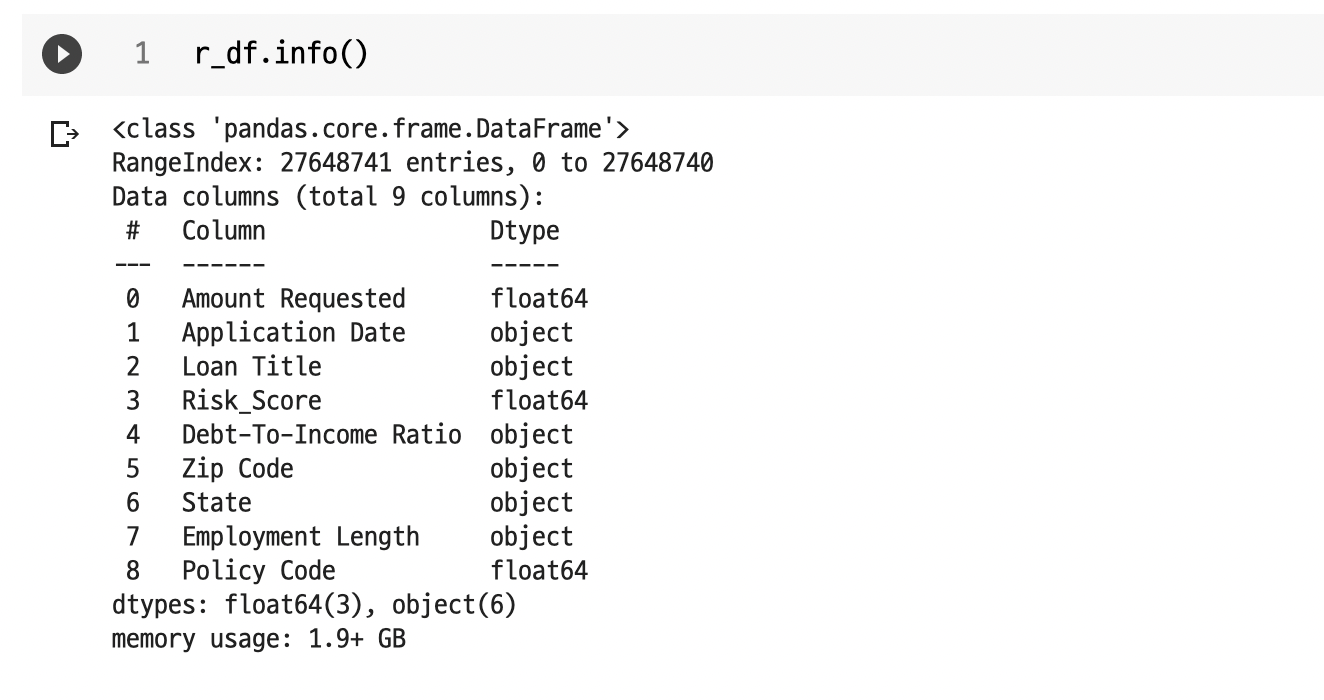
- 150 columns
: 150개나 되는 컬럼을 어떻게 선별해야하나 막막했다. colab이라도 용량이 커서 안 그래도 버거울 것 같았다. 또한, 이 데이터셋의 경우 타겟(종속변수)도 없기에 필자가 찾아야했다. 하지만, kaggle에서 필자가 참고한 EDA 노트 로 이러한 문제를 어느 정도 해결하였다. 참고한 EDA 노트 저자가 타겟을 잡는 것과 column을 어느 정도 필터링해주었기에 이를 참고하여 작성하였다.
EDA Review
01. 어떻게 생겼을까?
: 보통 csv 파일을 읽어서 pandas 형태로 받아서 'df'라는 이름의 변수에 저장한다. 그리고 (위에 기재했던 스크린샷처럼) df.shape, df.describe(), df.info() 등 함수로 전반적인 형태를 관찰한다. 행(row)과 열(column, feature)의 개수를 확인하거나 데이터의 형태(value)를 확인하기도 한다.
- 데이터셋은 총 2개의 csv 파일이었으며, Google Drive에 올려서, Mount 시킨 뒤, pd.read_csv() 를 이용하여 a_df, r_df 변수로 받았다.

02. 1차 컬럼(column) 선별
1) 실패한 필자의 '결측치를 통한 제거'
a_df.isnull().sum()null_list= []
for col in a_df.columns:
if a_df[col].isnull().sum() > 1260701:
null_list.append(col)
print(len(null_list))
null_list 생각보다 결측치가 많은 컬럼이 많다. 전체 행의 수(=데이터의 수)의 절반(1260701개) 이상이 결측치인 컬럼도 있었다. 그래서 1차적으로 필자의 자력으로 결측치가 많이 있는 컬럼부터 제거하려고 했다. EDA 노트 참고하지 않고 시도하려 했다. 하지만, 수차례 시도했으나, 끝까지 Google Colab의 RAM이 허락해주지를 않았다.
어쩔 수 없이, EDA 노트를 참고하게 되었다. 그런데, 노트 저자는 초반부터 쏘쿨하게 150개의 컬럼 중 약 23개의 컬럼만을 고르고 나머지는 버렸다. 무슨 근거로, 어떤 코드로 버렸는지 궁금해서 유심히 살펴보니, 다음 스크린샷과 같은 표로 정리해두었다. (길이가 많이 길어서 일부만 스크린샷을 촬영했다.)

그래서 결론적으로는 다음 스크린샷처럼 필자도 EDA 노트 저자처럼 똑같이 컬럼을 선별하였다.
 또한 RAM 보존을 위해, 다음 코드를 실행하여, 이전 변수들을 제거하였다.
또한 RAM 보존을 위해, 다음 코드를 실행하여, 이전 변수들을 제거하였다.
del a_df, r_df2) 타겟컬럼 컬럼 설정
이 부분도 EDA 노트의 덕을 안 봤다고 하면 거짓말일 것이다. EDA 노트 저자가 선별한 컬럼을 'df'에 pandas DataFrame으로 할당하였다. 그리고 직후에, 'loan_status' 컬럼을 대상을 value_counts() 로 value 값들의 종류와 각 value 별로 몇 개가 있는지 살펴 보았다.
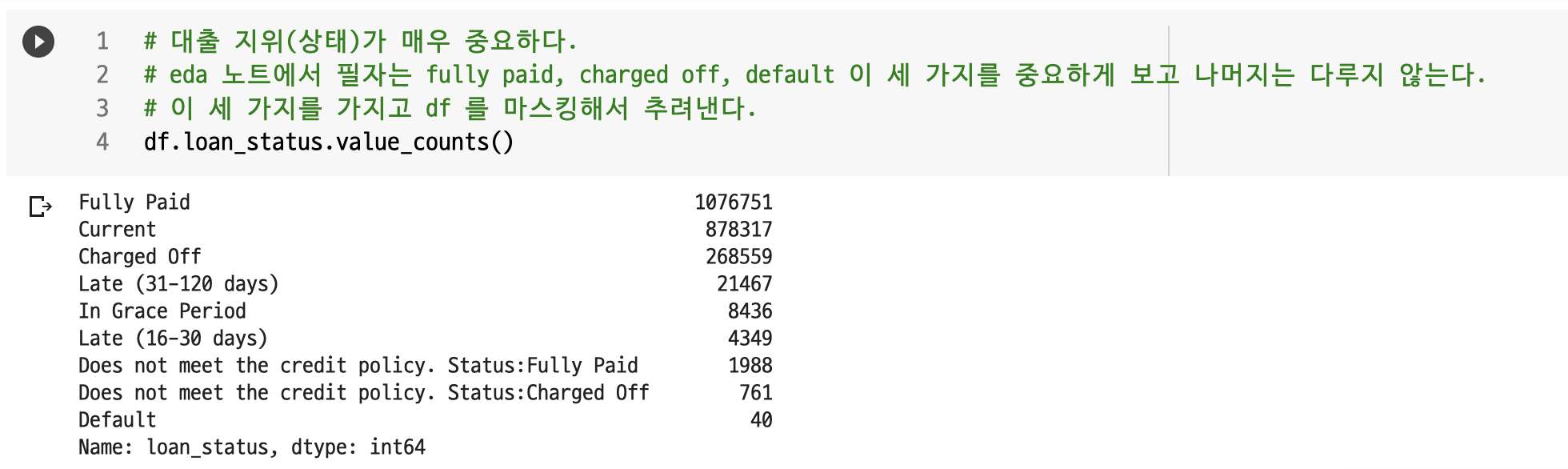
위 스크린샷처럼 나오는데, EDA 노트 저자는 value 값 중, 'Fully Paid', 'Charged Off', 'Default' value 값에 집중하였다. loan_status 중에서 위 세 항목이 가장 이 All Lending Club loan data (사용자 대출 여부 예측 대회)의 목적과 잘 부합하며, 나머지 value 값들은 의미가 없기 때문이다.
- Fully Paid : 완납
- Charged Off : (은행에 의한 불량 채권 따위의) 상각
- default : 채무 불이행, 특히 채무를 이행하지(변제하지) 않다, 체납하다
따라서 저자는, default 값 중, 'Fully Paid', 'Charged Off', 'Default'에 해당하는 데이터들을 조회하기 위해 다음과 같이 마스킹했다.
df = df[df.loan_status.isin(['Fully Paid', 'Charged Off', 'Default'])]
# 같은 코드이다.
df = df[df['loat_status'].isin(['Fully Paid', 'Charged Off', 'Default'])]
그리고 새로운 컬럼 'default'를 다음과 같이 타겟컬럼으로 만들었다. apply(), lambda 함수를 이용해서, loan_status 컬럼의 value 값들인 'Fully Paid', 'Default', 'Charged Off' 을 숫자 0과 1로 바꾸었다.
df['default'] = df.apply(lambda a: 1 if a.loan_status in ['Default', 'Charged Off'] else 0, axis = 1)
df['default']'Fully Paid'의 경우 '1'로 바꾸고, 'Charged Off', 'Default'의 경우에는 '0'으로 바꾸었다. 머신러닝에서는 문자열연산은 힘들기 때문에 숫자로 (숫자만을 인식하고 연산할 수 있기 때문) 변환해야 한다. 이러한 작업은 '원핫인코딩'이라고도 하며, get_dummies() , Tensorflow(keras) 함수로는 to_categorical() 가 있다.
그리고 저자는 위와 같이 카테고리화 한 다음, 'loan_status' 컬럼은 쿨하게 버렸다. (RAM을 위해서였던 듯... 같은 고통 속에 있었나보다.)
df = df.drop('loan_status', axis=1)정리를 하자면, EDA 노트 저자는 묻혀있던 '타겟 컬럼'을 찾고 끄집어내면서, 분류문제로 가시화한 것.
- 원래 keras 단독 패키지로 존재했었는데, keras 개발자가 Google에 입사하면서, keras가 tensorflow 로 흡수되었다.
from tensorflow import keras
from tenrsorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPool2D, Dropout, BatchNormalization
from tensorflow.keras.optimizers import Adam, SGD
from keras.layers.advanced_activations import LeakyReLU
딥러닝을 하게 되면 보게 될 것이다. ^^
3) Heatmap으로 상관계수를 살펴볼까?
: EDA 노트 저자는 그렇게 선별하고 마스킹한 df의 각 컬럼간의 상관관계를 살펴보기 위해 pandas corr()와 seaborn의 HEATMAP을 사용했다.
sns.set(style = 'whitegrid', font_scale = 1)
plt.figure(figsize = (12, 12))
plt.title("pearson corr matrix", fontsize = 24)
sns.heatmap(df.corr(), linewidths = 0.25, vmax= 0.7, square = True,
cmap = 'RdPu', linecolor='w',
annot=True, annot_kws = {'size':10},
cbar_kws={'shrink': .7})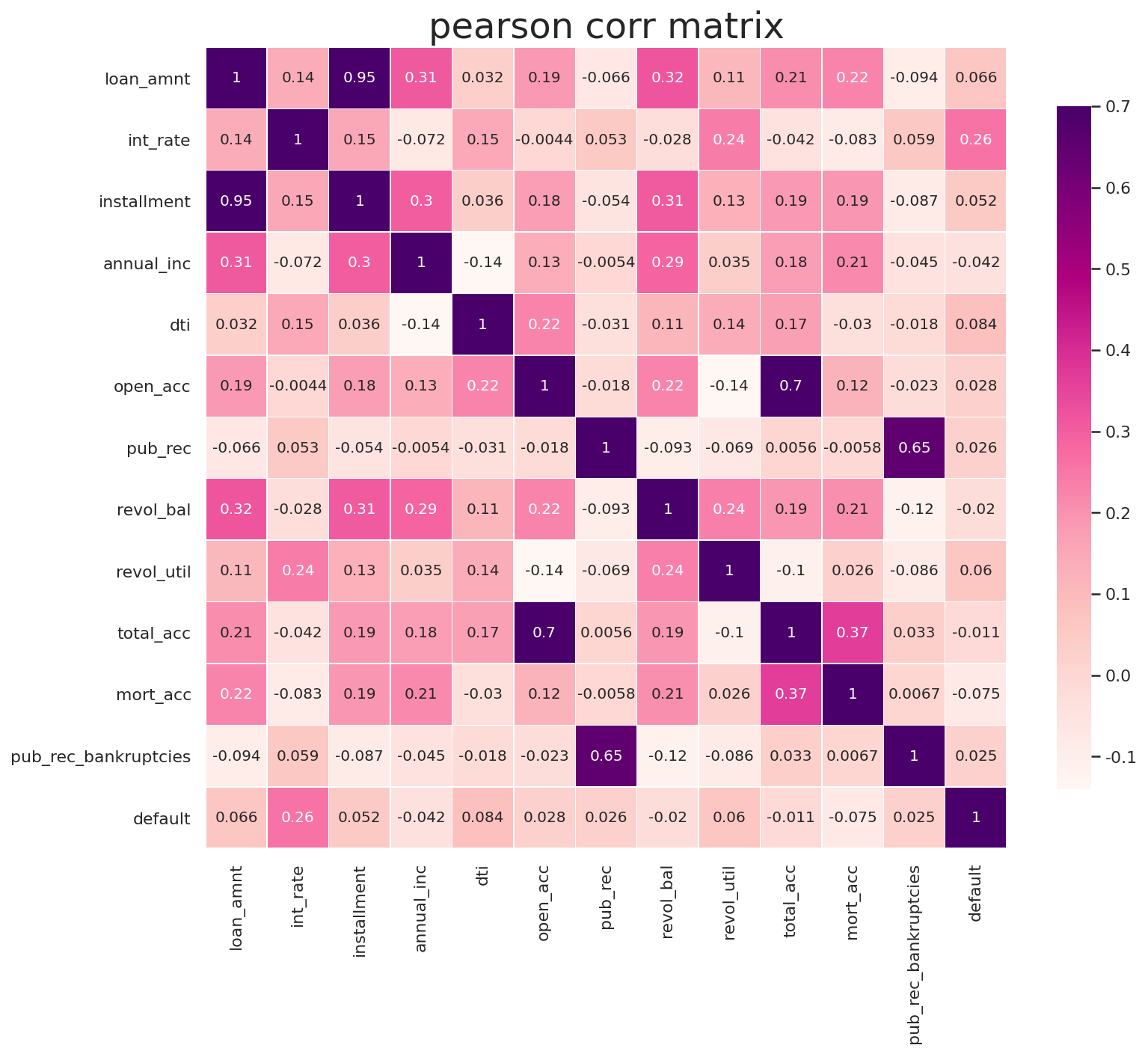
4) 상관계수
'상관계수'라는 보편적인 개념은 'x가 증가할 때, y가 얼마나 증가(혹은 감소)하는 정도'를 말한다.
- 필자가 들었던 의문
: EDA 노트 저자의 EDA 단계까지를 필사하면서, 이를 바탕으로 필자 자력으로 혼자서 EDA를 진행해보았다. 처음 필사 단계에서는 전혀 생각을 못 했으나, 혼자 EDA 진행시에는 이런 생각이 들었다. - 분류문제? 회귀문제?
: 분류문제는 이 문제처럼 우리가 예측해야할 값이 default 컬럼의 1, 0처럼 특정 개수로 정해져있는 문제를 말한다. scikit-learn의 iris 데이터셋과 tensorflow에선 cifar 문제가 있다.
반면, '회귀문제'라고 하면, 정해져있지 않는 범주의 값을 주어진 컬럼들만을 가지고 예측하는 것이다. 실생활로 말하자면, 부동산 가격이나 주가예측을 예로 들 수 있다. scikit-learn에서 Boston 집값 예측 문제가 있다. - '상관계수는 분류문제보다 회귀문제에 더 적합하지 않을까?'
: 분류문제, 특히, 이 데이터셋의 default 라는 타겟에서는 value가 1 아니면 0 둘 중 하나로 정해져있다. 이러한 문제보다는 상관계수는 회귀문제에서 상관계수가 더 큰 의미를 지닐 것이다. 주어진 컬럼들을 가지고 타겟이 얼마나 증가하는 지 알 수 있기 때문이다. 그래서 강사님께 이에 대한 문의를 했고, 강사님께서도 실제로 '상관계수라는 개념은 회귀문제에 조금 더 적합하다'고 답변해주셨다.
** 추가: '상관계수만으로 분류하는 것은 위험할 수 있습니다.' 라고도 해주심. 이게 다는 아니니까.
03. 2차 컬럼(column) 선별
EDA 노트 저자의 다음 액션으로는 거르고 거른 컬럼들과 'default' 라는 타겟컬럼(새로 만든)간의 관계를 살펴보기 위해서 seaborn의 'boxplot'과 'barplot'을 이용하였다.
원래 EDA 노트 저자는 아래 두 코드를 elif 문을 이용하여 하나로 합쳤었는데, 한 번에 여러개 나오는 게 오래걸리기도 하고, Colab에서 보기도 힘들어서 필자 임의로 데이터 타입 type에 따라 나누었다.
1) data type = float64 인 경우
: 특정되지 않은, 연속적인 숫자를 value로 가지는 컬럼의 경우는 boxplot을 사용하였다. 전반적인 분포와 평균, 분산 등을 대략적으로 살펴볼 수 있다.
for col in df.columns:
if df[col].dtype =='float64':
fig, ax = plt.subplots(figsize = (6, 6))
sns.boxplot(ax = ax, y=col, x='default', data=df, showfliers = False)
else:
passfor문을 돌렸기 때문에, 여러 그래프가 나오는 게 맞다. 하지만, 스크롤압박의 부담을 줄여주기 위해서 다음과 같이 한 개의 그래프만을 첨부한다.
'int_rate'컬럼과 'default' 간의 관계를 boxplot으로
.png)
2) data type = object 인 경우
: 데이터 타입이 object인 경우와 컬럼에 담긴 value 값의 종류가 52가지 미만인 경우는, 범주형 컬럼일 가능성이 매우 크다. 그래서, 이러한 범주형 컬럼에서는 barplot으로 살펴보았다.
for col in df.columns:
if (df[col].dtype == 'object') and (len(df[col].unique())< 52):
fig, ax = plt.subplots(figsize = (6, 6))
data = df.groupby(col)['default'].value_counts(normalize=True).mul(100).rename('percent').reset_index()
sns.barplot(data=data, y='percent', x=col, hue='default', ax= ax)
else:
pass'sub_grade'컬럼과 'default' 간의 관계를 boxplot으로
.png)
여기까지가 필자가 참고한 EDA 노트 저자의 EDA 단계까지 내용이다. 이후의 저자는 또 쏘쿨하게 위의 시각화를 바탕으로 상관관계가 없어보이는 컬럼 몇 개를 버리고(이것도 참고함...), 다음에 전처리를 하고 Logistic Regression 단계에 돌입한다.
필자가 필요했던 부분은 EDA 단계이기 때문에, 여기까지 참고를 했다. 나머지는 이어서 작성하겠다. 이후부터는 이를 바탕으로, 필자가 진행했던 EDA를 리뷰하겠다.
