Custom Dataset이란?
사용자가 정한 만큼의 데이터 양과 형식의 세팅
DataLoader이란?
Dataset을 iterator와 index를 이용하여 batch size만큼의 데이터를 꺼내서 사용하는 객체
Custom Dataset의 기본 형태
- init : 변수 선언 및 데이터 전처리
- len : 데이터셋의 길이 반환
- getitem : 해당하는 index의 데이터를 가져오는 함수
def __init__(self):
def __len__(self):
def __getitem(self,idx):실습
titanic dataset
타이타닉 승객들의 데이터로 생존 여부 예측
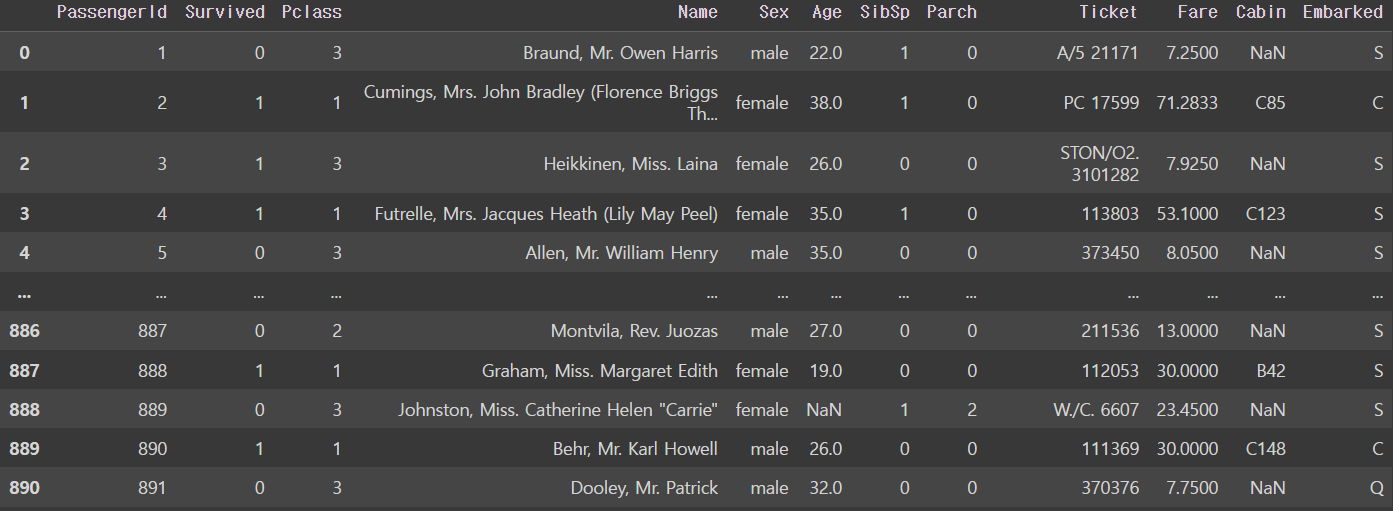
preprocessing 전
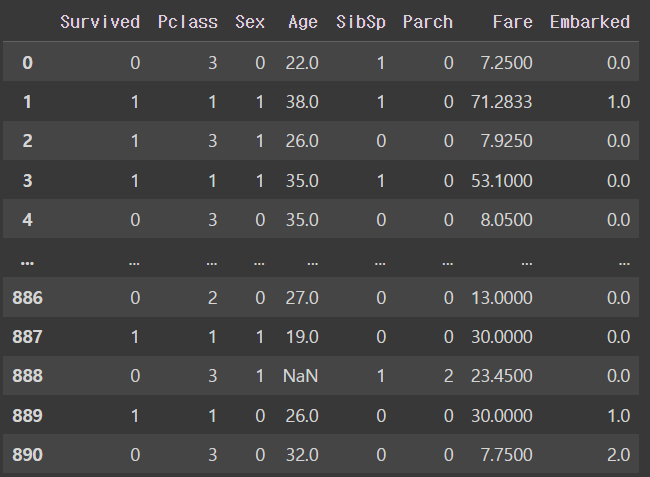
preprocessing 후
class TitanicDataset(Dataset):
def __init__(self, path, drop_features, train=True): #train은 train, test data 구분
self.data = pd.read_csv(path) # csv파일을 파라미터를 통해 데이터셋을 불러옴
self.data['Sex'] = self.data['Sex'].map({'male':0, 'female':1}) # 'Sex' series를 숫자화
self.data['Embarked'] = self.data['Embarked'].map({'S':0, 'C':1, 'Q':2}) # 'Embarked' series를 숫자화
self.data = self.data.drop(drop_features, axis=1) # drop_features 파라미터로 받은 series를 drop
self.X = self.data # 예측하기 위해 필요 data
self.y = self.data.pop('Survived') # 답
self.features = list(self.data.columns)
self.classes = ['Survived', 'Dead'] # 답 분류
self.train = train
def __len__(self):
len_dataset = len(self.data)
return len_dataset
def __getitem__(self, idx):
X = self.X.loc[idx]
if self.train:
y = self.y.loc[idx] # 학습 데이터일 경우
# print("getitefm:: ",X, y)
return torch.tensor(X), torch.tensor(y)
반갑습니다.
너무 도움됐습니다 !