Redshift
1. 특징
- AWS에서 지원하는 데이터 웨어하우스 서비스
- 2PB의 데이터까지 처리 가능
- Still OLAP
- 컬럼 기반 스토리지
- 고정 용량/비용 SQL 엔진 (최근 가변 비용 옵션인 Redshift Serverless도 제공함, free trial은 얘만 가능)
- 다른 데이터 웨어하우스의 경우와 마찬가지로 Primary key uniqueness를 보장하지 않음
- 포트넘버 5439
2. 스케일링 방식
용량이 부족할 때마다 새로운 노드를 추가하는 방식으로 스케일링.
Snowflake, BigQuery의 방식과는 굉장히 다름. (이 친구들은 가변 비용 옵션, 이에 따라 비용 예측 불가능하다는 단점 존재)
3. 레코드 분배와 저장 방식
Redshift가 두 대 이상의 노드로 구성되면, 그 시점부터 테이블 최적화가 중요함 (한 테이블의 레코드들을 어떻게 다수의 노드로 분배할지 고민)
- 예시
CREATE TABLE my_table (
column1 INT,
column2 VARCHAR(50)
column3 TIMESTAMP
column4 DECIMAL(18, 2)
) DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3);여기서 my_table의 레코드들은 column1 값 기준으로 분배,
같은 노드(슬라이스)로 보내지는 레코드의 경우, 이 안에서는 column3의 값을 기준으로 sort. (보통 sort는 TIMESTAMP로 하는 편)
- 만약 Diststyle이 key인 경우 컬럼 선택이 잘못된다면 → 레코드 분포에 Skew 발생
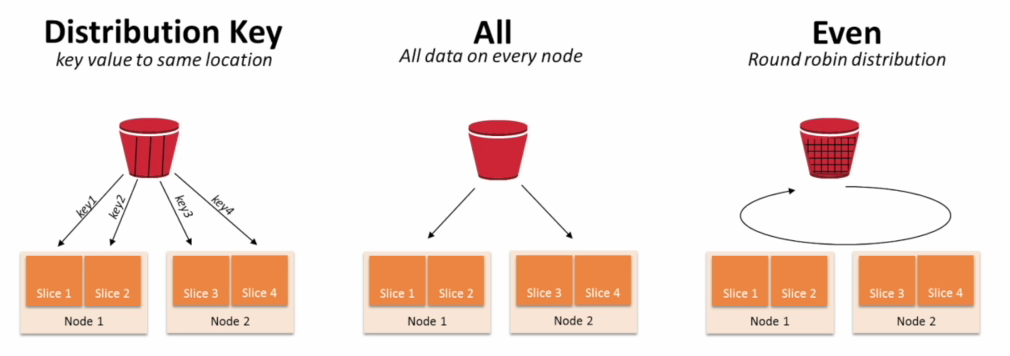
이 경우는 default를 Even 방식으로 하는 게 좋을 수 있음 (레코드가 노드에 균등하게 분배되는 방식)
그러나 GROUPBY / JOIN하게 되면 병렬처리 이점 사라짐
Copy SQL
-
COPY 명령 실행 중에 에러가 난다면
SELECT * FROM stl_load_errors ORDER BY starttime DESC;
