Project - BankMate(대상 수상)
0. 프로젝트 개요
- 소속 교육기관: (주)에프앤이노에듀
- 과정명: 현장 전문가 육성을 위한 인공지능(AI) 창의융합형 인재 양성과정(2021.06.17 ~ 2021.11.30)
- 프로젝트 기간 : 2021.10.13 ~ 2021.11.30 (약 7주)
- 프로젝트 내용 : 금융업무의 편의성 및 효율성 증진을 위한 안면인증 시스템과 업무용 챗봇 구현
- 프로젝트 담당 부분
- 프로젝트 기획
- 1D CNN을 사용한 챗봇 모델 생성
- Django를 이용한 VGG FACE 안면인증 시스템 및 Chabot 서비스를 홈페이지에 구현 - 프로젝트 기획 배경
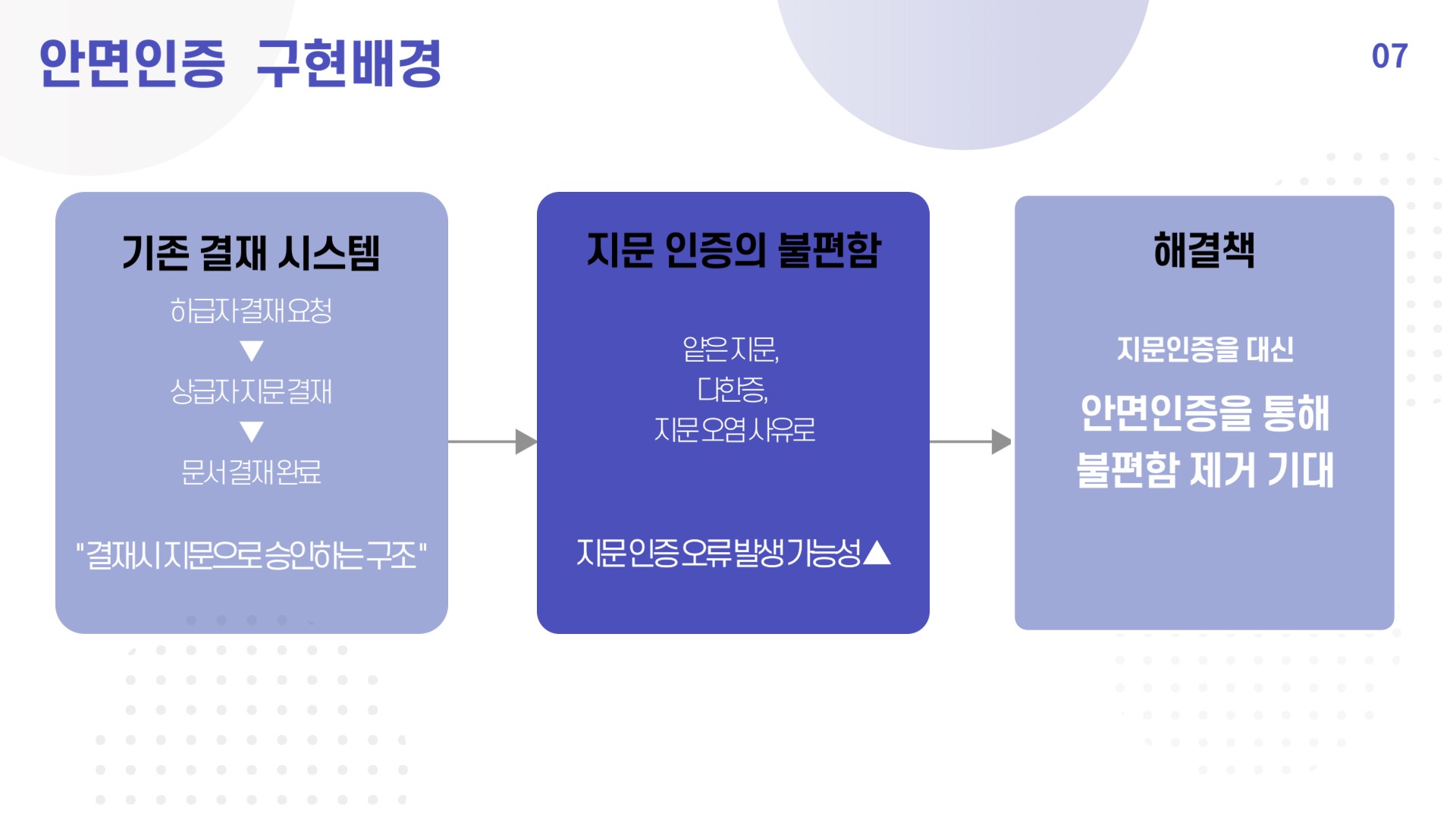
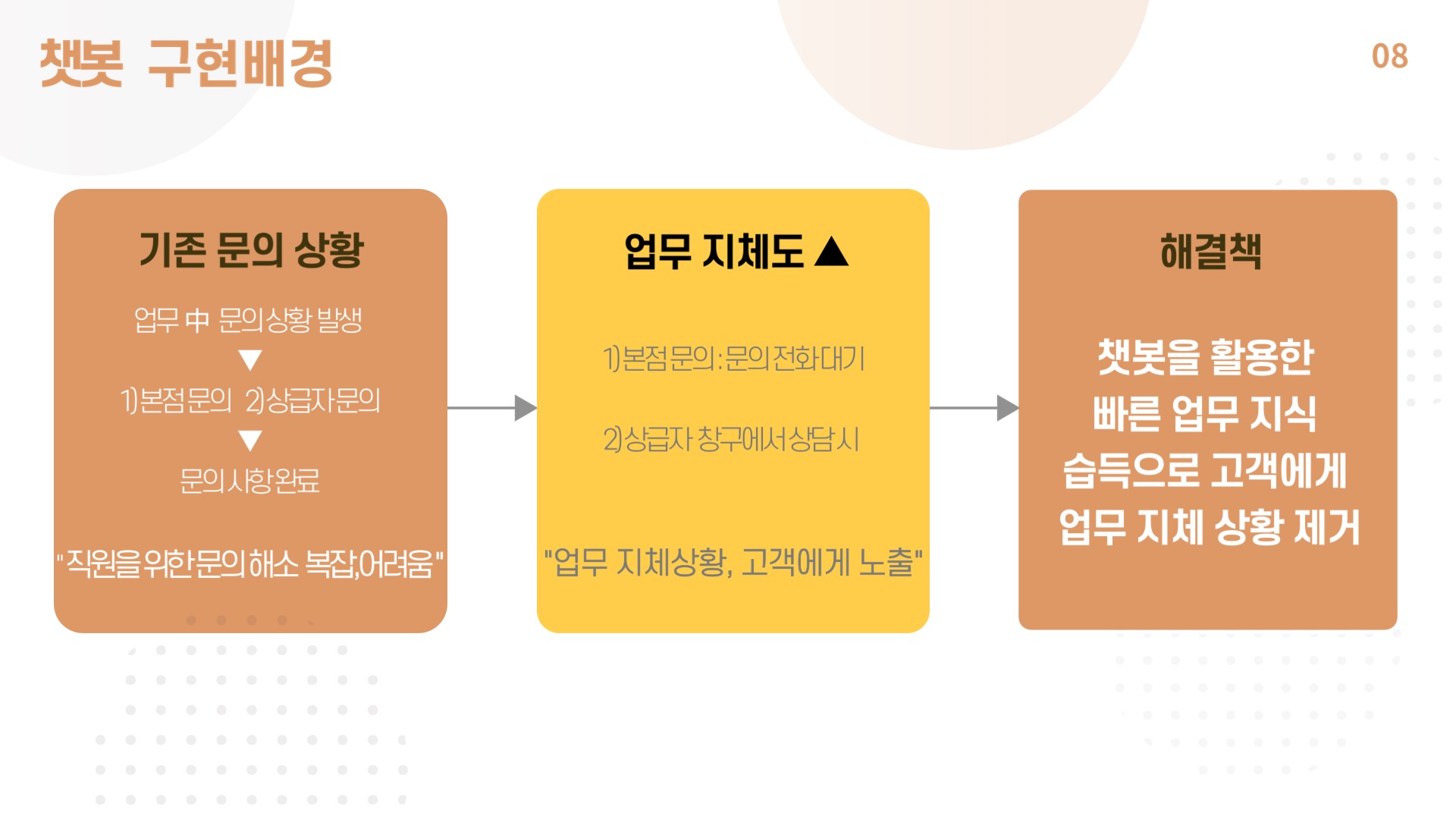
- 현재 금융권에서 사용되는 대부분의 AI 서비스는 고객 중심에 머물러 있음. 반대로 우리는 직원들 역시 AI 서비스를 제공받는 대상이 될 수 있다고 생각함.
- 따라서 직원들에게 업무 효율성을 증진시킬 수 있는 업무용 챗봇과 안면인증 서류 결재 시스템을 생각하게 됨.
1. 프로젝트 구현배경
2. 현황분석


3. 안면인증 구현과정
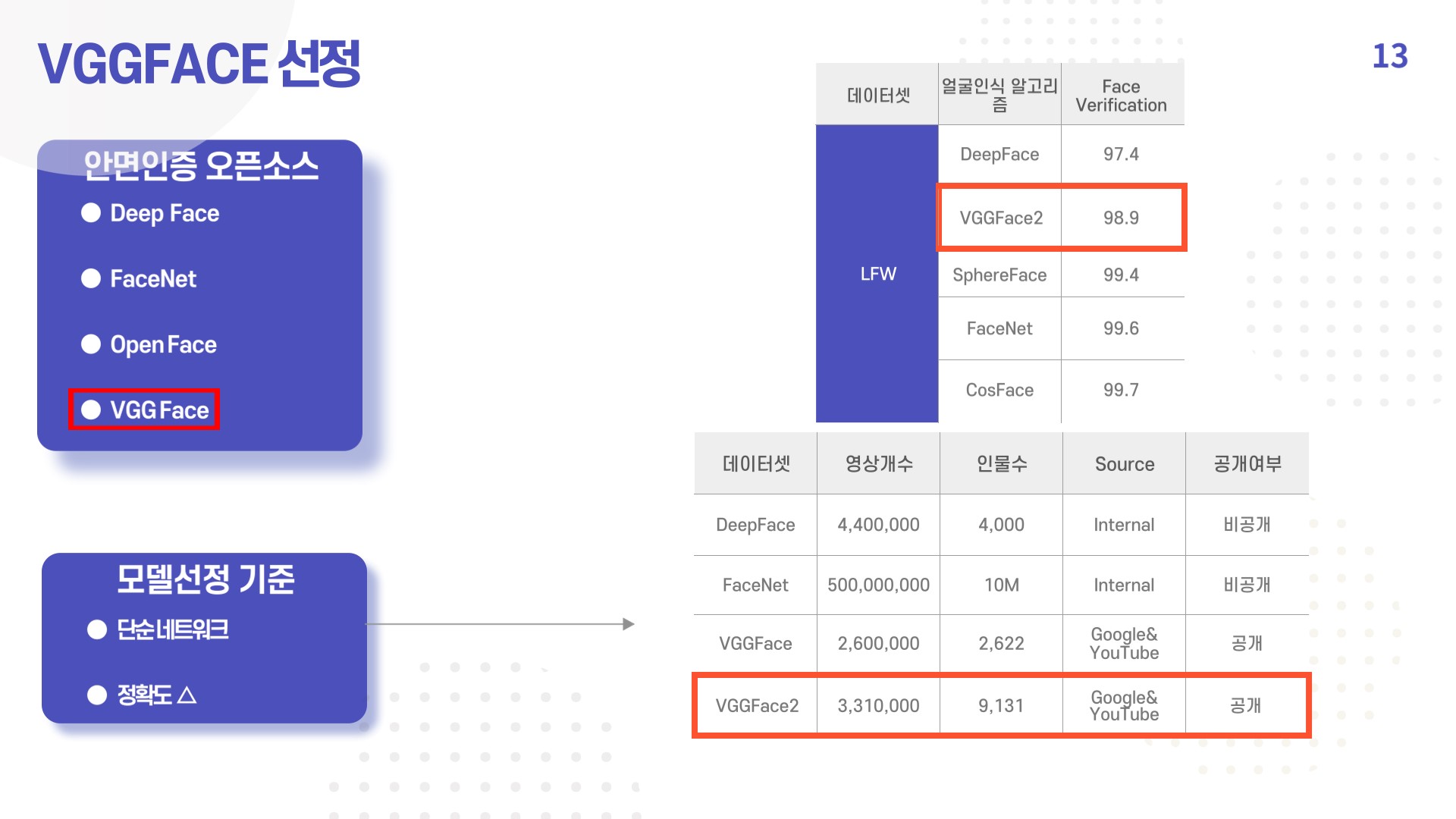
1) VGGFACE 선정 이유
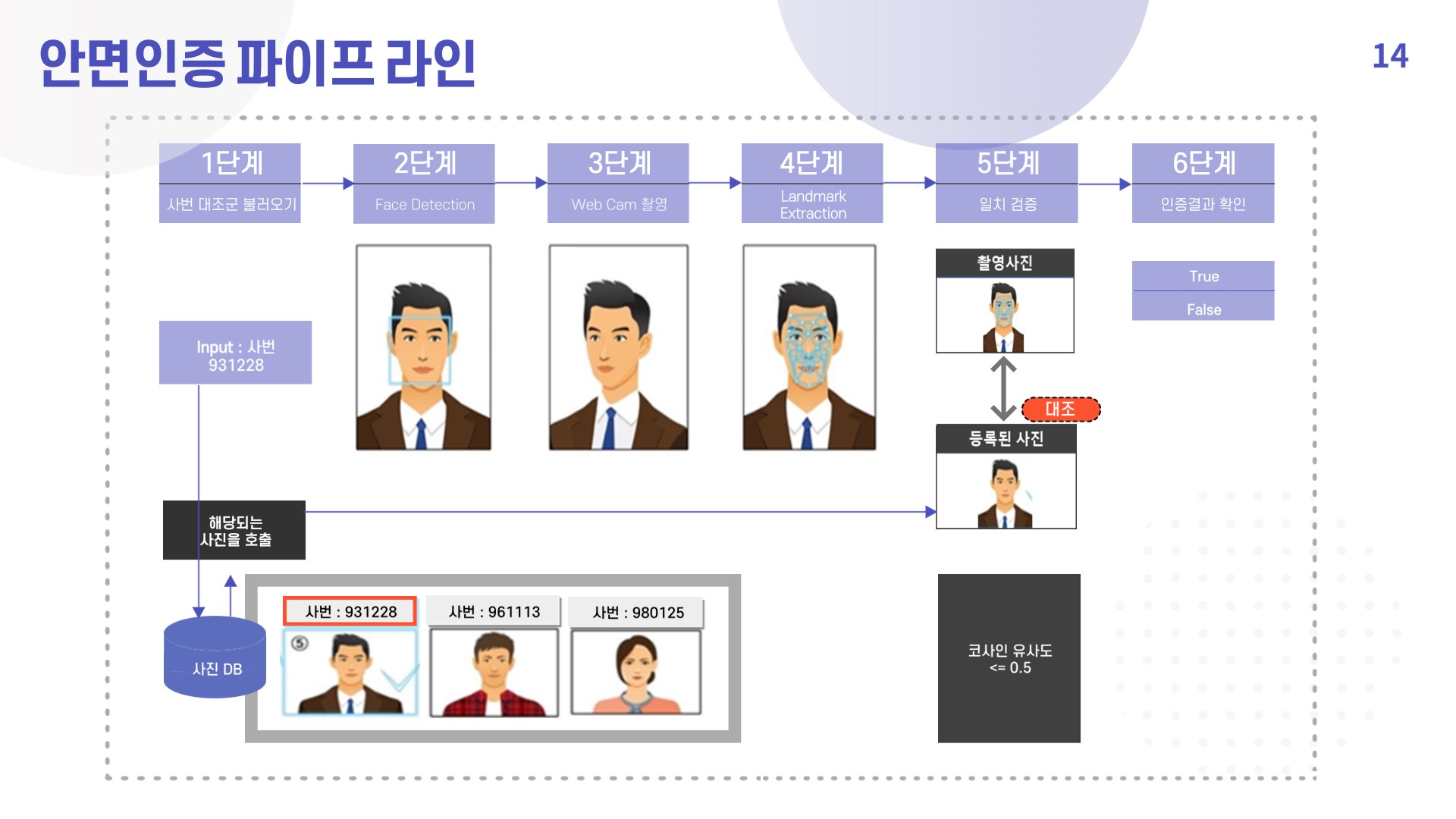
2) 안면인증 파이프라인
3) 안면인증 코드 구현


4. 챗봇 구현과정
1) 챗봇 모델
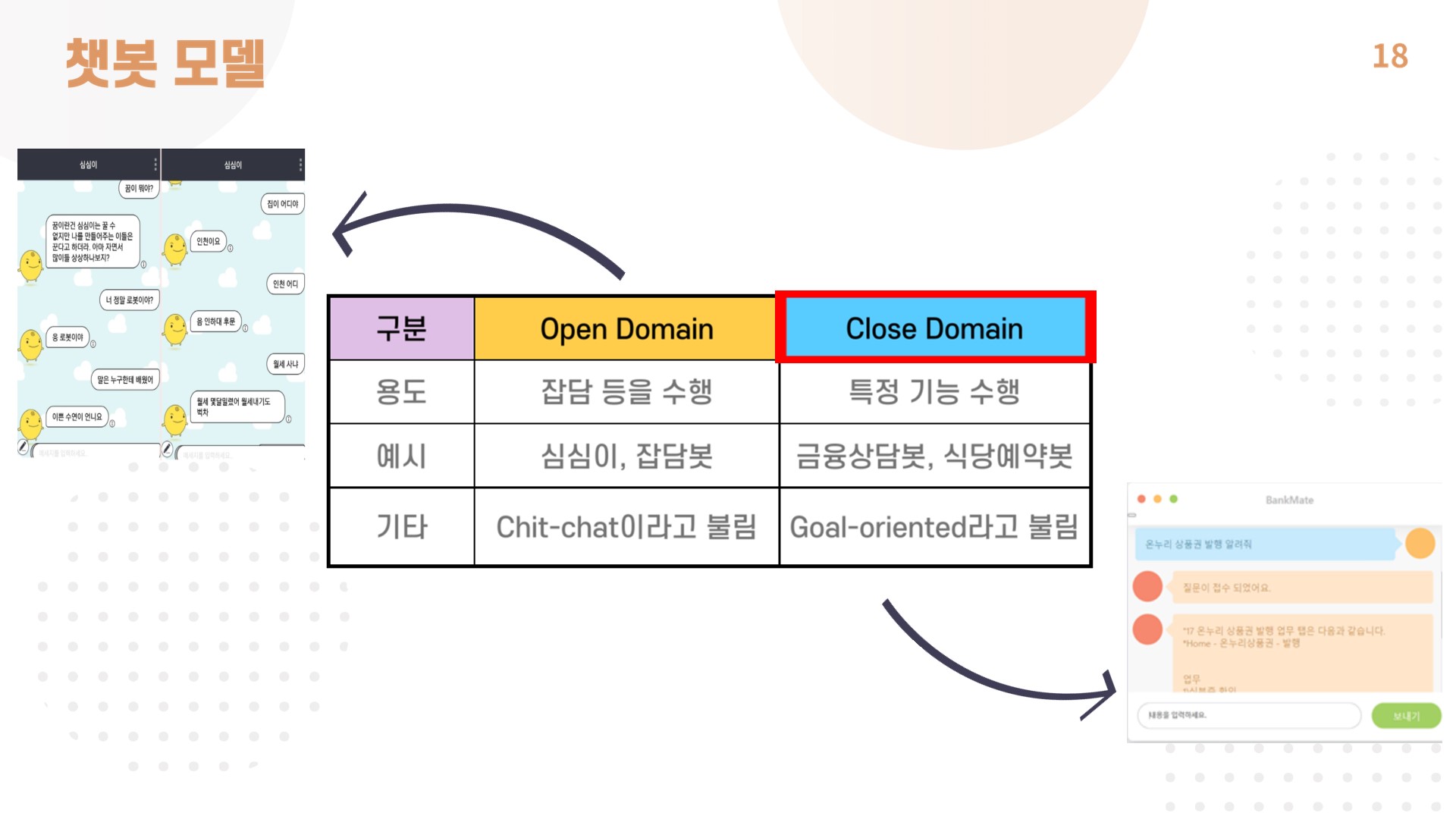
- BankMate 챗봇은 업무 수행이라는 한정된 대화 범위 안에서 사용자가 원하는 목적을 달성하기 위한 챗봇이기 때문에 close domain에 속함.
2) 챗봇 파이프라인

3) 챗봇 지식범위 및 분류 체계
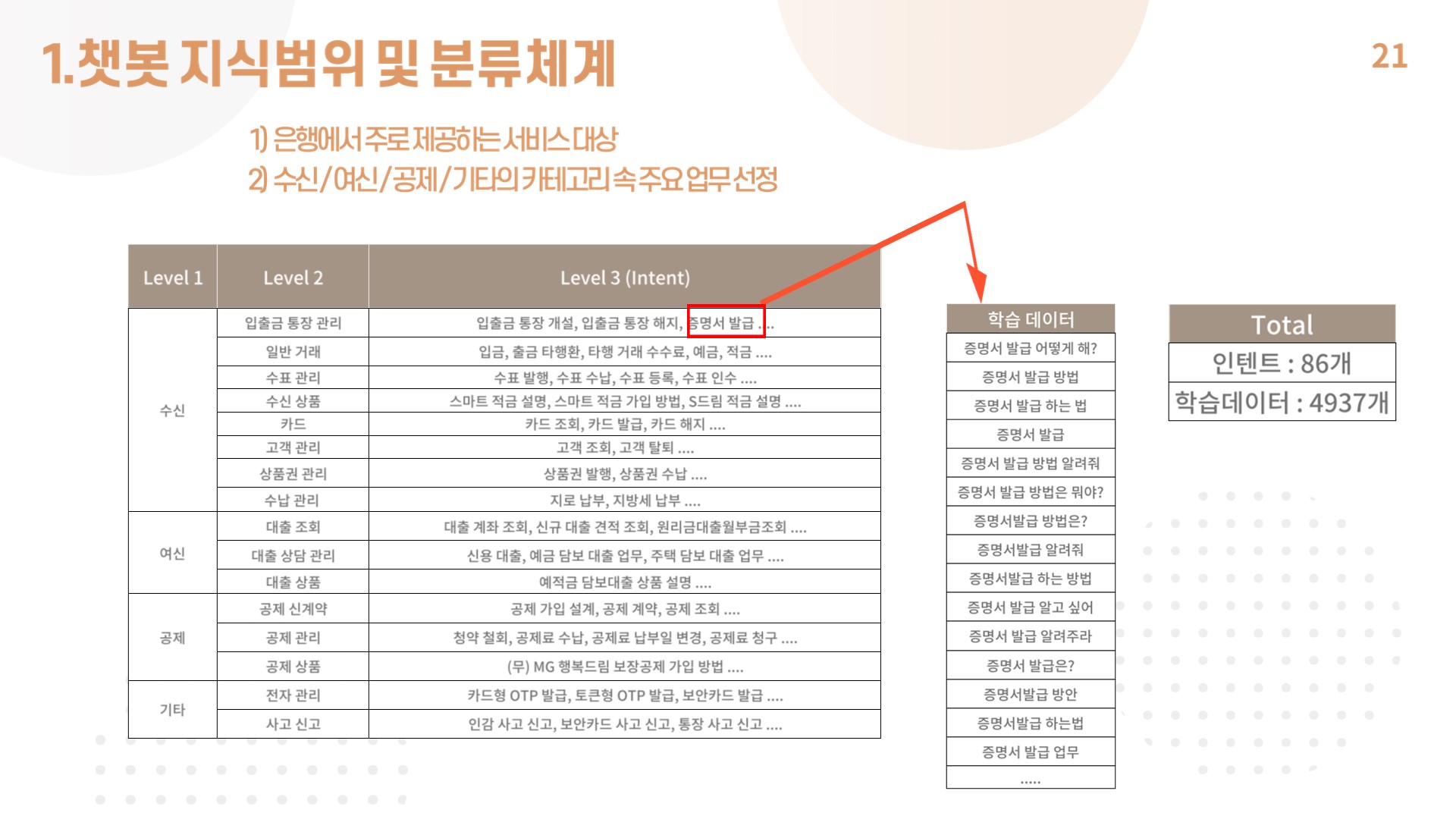
- BankMate에 필요한 인텐트와 답변부분은 전직 은행원이었던 조원 2명을 통해 수집함.
4) KoNLPy Kkma
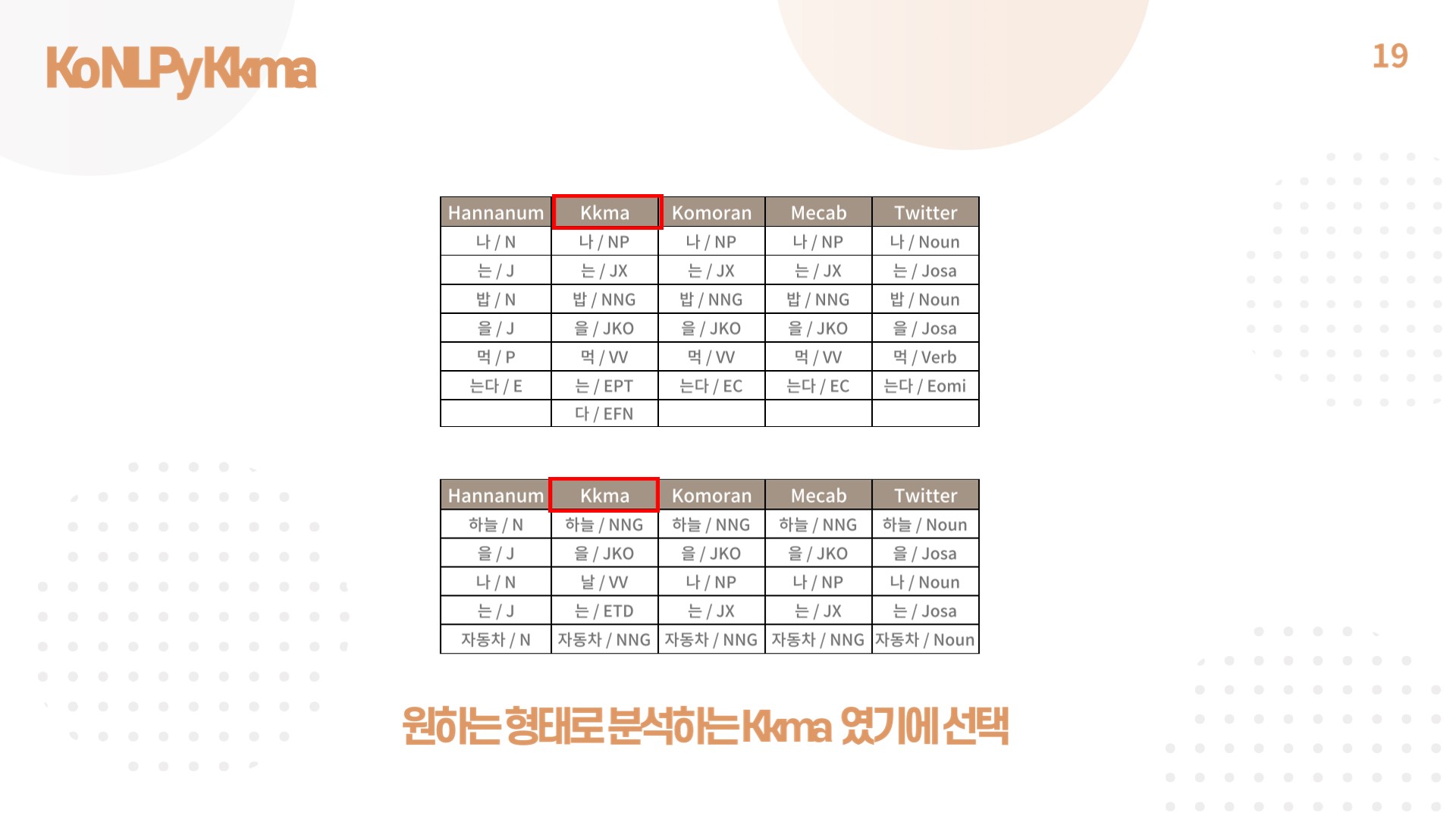
- 챗봇 자연어 처리를 위해 KoNLPy Kkma 형태소 분석기를 사용함.
- 문자가 많을수록 실행시간이 증가하는 단점이 있지만, 수집한 데이터를 가장 정확하게 분석해 주기 때문에 선택함.

- Kkma 딕셔너리의 경우 기존의 명사 사전이 은행 업무 용어를 포함하지 않는 경우가 많아 새로 업무용 딕셔너리를 작성, 적용함.
5) 복합어 후처리
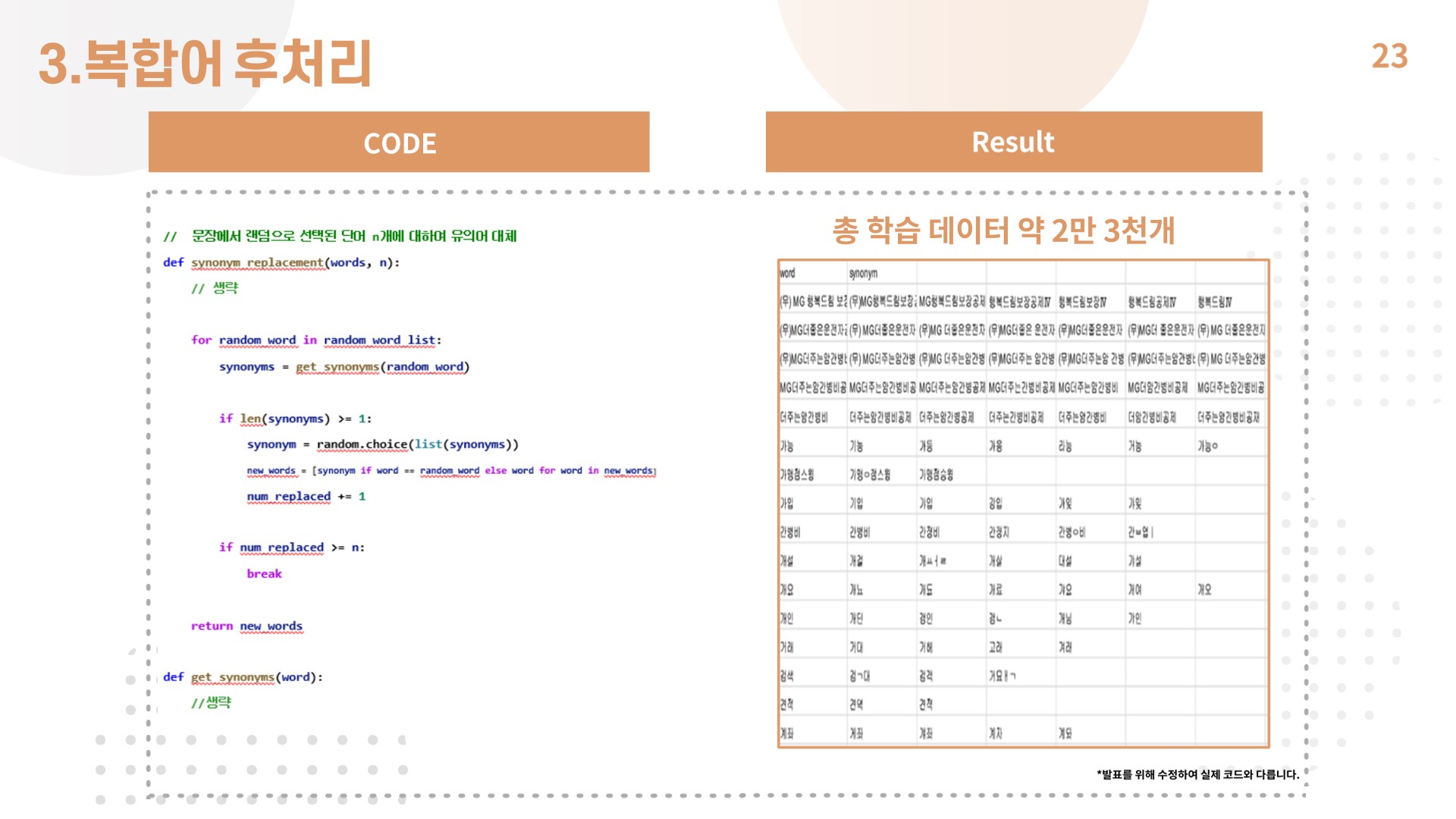
- 데이터를 증대하고 띄어쓰기, 오타를 방지하기 위해 복합어 처리를 진행함.
- synonym 사전을 새로 만들어 중요 업무 용어에 대해 유의어를 정의함.
Code 구현
# !pip install gensim
from gensim.models import Word2Vec
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Embedding, Dropout, Conv1D, GlobalMaxPooling1D, Dense, Input, Flatten, Concatenate
import csv
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import preprocessing
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences# 문장에서 랜덤으로 선택된 단어 n개에 대하여 유의어 대체
def synonym_replacement(words, n):
new_words = words.copy()
np.random.seed(1103)
random_word_list = list(set([word for word in words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(list(synonyms))
new_words = [synonym if word == random_word else word for word in new_words]
num_replaced += 1
if num_replaced >= n:
break
return new_words
def get_synonyms(word):
synomyms = []
try:
for syn in synonym_dict[word]:
synomyms.append(syn)
except:
pass
return synomyms# 유의어 사전 생성
synonym_dict = {}
with open("data\synonym.csv",'r', encoding="UTF-8") as f:
reader = csv.reader(f)
next(reader)
for lines in reader:
while '' in lines:
lines.remove('') # '' 삭제
synonym_dict[lines[0]] = lines[1:]
tokenized_expand_data=list()
f = open("data\save.csv", 'r', encoding='utf-8')
rea = csv.reader(f)
for row in rea:
while '' in row:
row.remove('') # '' 삭제
tokenized_expand_data.append(row)
f.close
label_expand_data=list()
f = open("data\save2.csv", 'r', encoding='utf-8')
rea = csv.reader(f)
for row in rea:
while '' in row:
row.remove('') # '' 삭제
label_expand_data.append(row)
f.close
def csv2list(filename):
import csv
file = open(filename, 'r', encoding="UTF-8")
csvfile = csv.reader(file)
lists = []
for items in csvfile:
lists.append(items)
return lists
tokenized_data = csv2list('data\kkma_tokenized_data.csv')
tokenized_nouns = csv2list('data\kkma_tokenized_nouns.csv')6) Tokenizing & Word2Vec

- 새로 정의된 사전을 바탕으로 문장을 꼬꼬마 토크나이저를 사용해 토큰화함.
- 이 때 문장을 명사만 토큰화한 데이터, 문장 전체를 토큰화한 데이터로 나누어 저장했음.
- 그런 다음 토큰화한 데이터를 word2vec모델에 적용, CNN모델에서 가중치 행렬로 사용할 임베딩 행렬을 생성함.
Code 구현
# 임베딩 단계
model_wv = Word2Vec(sentences = tokenized_expand_data, vector_size = 100, window = 2, min_count = 10, workers = 2, sg = 1, epochs=50)7) 1D CNN모델 생성
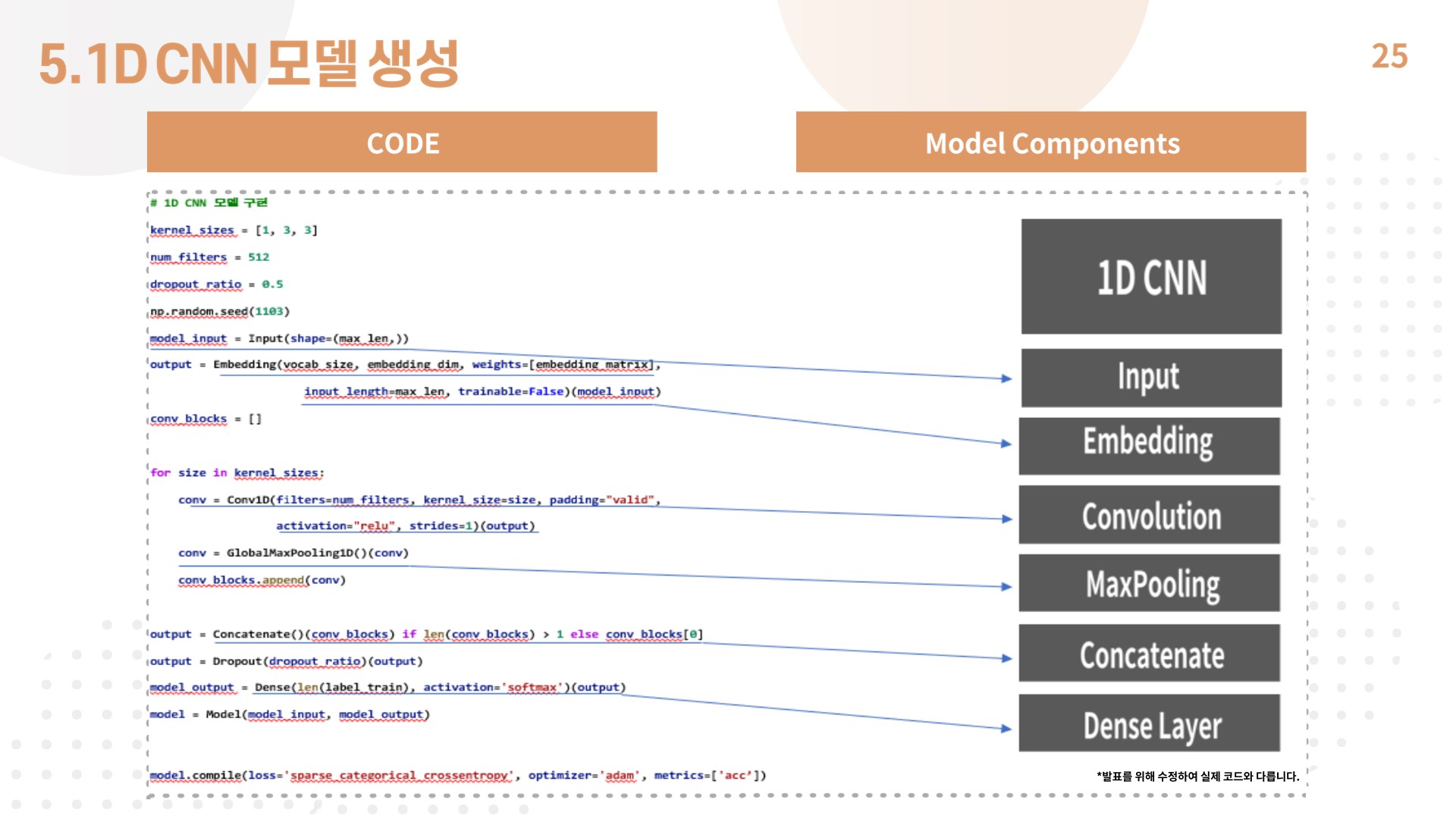
- 1D CNN 모델의 구성은 인풋 레이어, 임베딩 레이어, 사이즈 [1, 3, 3]의 컨볼루션 레이어 3개로 구성되어 있음.
- 각 벡터에 대해 맥스 풀링을 한 후에는 스칼라 값을 얻는데, 이렇게 얻은 스칼라값들은 전부 연결(concatenate)하여 하나의 벡터로 만들어줌.
- 드롭아웃까지 거친 후 얻은 벡터는 1D CNN을 통해서 문장으로부터 얻은 최종 특성 벡터로 뉴런이 2개인 출력층에 완전 연결시키므로서(Dense layer를 사용) 텍스트 분류를 수행함.
Code 구현
# 1D CNN
train_data=[]
for i in range(0, len(tokenized_expand_data)):
train_data.append(' '.join(tokenized_expand_data[i]))
label_data = pd.read_csv('data\\bankmate_train2.csv', encoding="UTF-8")['label']
label_data = label_data.tolist()# 레이블 인코딩. 레이블에 고유한 정수를 부여
idx_encode = preprocessing.LabelEncoder()
idx_encode.fit(label_expand_data)
label_expand_data = idx_encode.transform(label_expand_data) # 주어진 고유한 정수로 변환
label_idx = dict(zip(list(idx_encode.classes_), idx_encode.transform(list(idx_encode.classes_))))
tokenizer = Tokenizer(oov_token="OOV")
tokenizer.fit_on_texts(train_data)
sequences = tokenizer.texts_to_sequences(train_data)
word_index = tokenizer.word_index
vocab_size = len(word_index) + 2
max_len = 17
question_train = pad_sequences(sequences, maxlen = max_len)
indices = np.arange(question_train.shape[0])
np.random.seed(1103)
np.random.shuffle(indices)
question_train = question_train[indices]
label_train = label_expand_data[indices]
n_of_val = int(0.2 * question_train.shape[0])C:\Users\User\anaconda3\lib\site-packages\sklearn\preprocessing\_label.py:98: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
C:\Users\User\anaconda3\lib\site-packages\sklearn\preprocessing\_label.py:133: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)# 훈련, 검증 데이터 분리
X_train = question_train[:-n_of_val]
y_train = label_train[:-n_of_val]
X_val = question_train[-n_of_val:]
y_val = label_train[-n_of_val:]
embedding_dim = 100
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for i in range(len(model_wv.wv.vectors)):
embedding_vector = model_wv.wv.vectors[i]
if embedding_vector is not None:
embedding_matrix[i+1] = embedding_vector# 모델 구성
kernel_sizes = [1, 3, 3]
num_filters = 512
dropout_ratio = 0.5
np.random.seed(1103)
model_input = Input(shape=(max_len,))
output = Embedding(vocab_size, embedding_dim, weights=[embedding_matrix],
input_length=max_len, trainable=False)(model_input)
conv_blocks = []
for size in kernel_sizes:
conv = Conv1D(filters=num_filters, kernel_size=size, padding="valid",
activation="relu", strides=1)(output)
conv = GlobalMaxPooling1D()(conv)
conv_blocks.append(conv)
output = Concatenate()(conv_blocks) if len(conv_blocks) > 1 else conv_blocks[0]
output = Dropout(dropout_ratio)(output)
model_output = Dense(len(label_train), activation='softmax')(output)
model = Model(model_input, model_output)
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['acc'])
# 구성 끝# 모델 학습 및 결과 확인
history = model.fit(X_train, y_train,
batch_size=64,
epochs=10,
validation_data=(X_val, y_val))Epoch 1/10
308/308 [==============================] - 113s 362ms/step - loss: 1.2397 - acc: 0.7515 - val_loss: 0.1506 - val_acc: 0.9565
Epoch 2/10
308/308 [==============================] - 108s 350ms/step - loss: 0.0868 - acc: 0.9804 - val_loss: 0.0404 - val_acc: 0.9921
Epoch 3/10
308/308 [==============================] - 111s 361ms/step - loss: 0.0398 - acc: 0.9907 - val_loss: 0.0256 - val_acc: 0.9941
Epoch 4/10
308/308 [==============================] - 125s 405ms/step - loss: 0.0281 - acc: 0.9932 - val_loss: 0.0190 - val_acc: 0.9961
Epoch 5/10
308/308 [==============================] - 126s 409ms/step - loss: 0.0234 - acc: 0.9943 - val_loss: 0.0169 - val_acc: 0.9957
Epoch 6/10
308/308 [==============================] - 117s 380ms/step - loss: 0.0240 - acc: 0.9943 - val_loss: 0.0231 - val_acc: 0.9931
Epoch 7/10
308/308 [==============================] - 112s 362ms/step - loss: 0.0221 - acc: 0.9948 - val_loss: 0.0539 - val_acc: 0.9850
Epoch 8/10
308/308 [==============================] - 113s 366ms/step - loss: 0.0248 - acc: 0.9946 - val_loss: 0.0189 - val_acc: 0.9951
Epoch 9/10
308/308 [==============================] - 112s 363ms/step - loss: 0.0238 - acc: 0.9942 - val_loss: 0.0212 - val_acc: 0.9957
Epoch 10/10
308/308 [==============================] - 131s 425ms/step - loss: 0.0231 - acc: 0.9954 - val_loss: 0.0232 - val_acc: 0.9955plt.figure(figsize=(16, 5))
plt.subplot(1,2,1)
epochs = range(1, len(history.history['acc']) + 1)
plt.plot(epochs, history.history['acc'])
plt.plot(epochs, history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='lower right')
plt.subplot(1,2,2)
epochs = range(1, len(history.history['loss']) + 1)
plt.plot(epochs, history.history['loss'])
plt.plot(epochs, history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend(['train', 'test'], loc='upper right')
plt.show()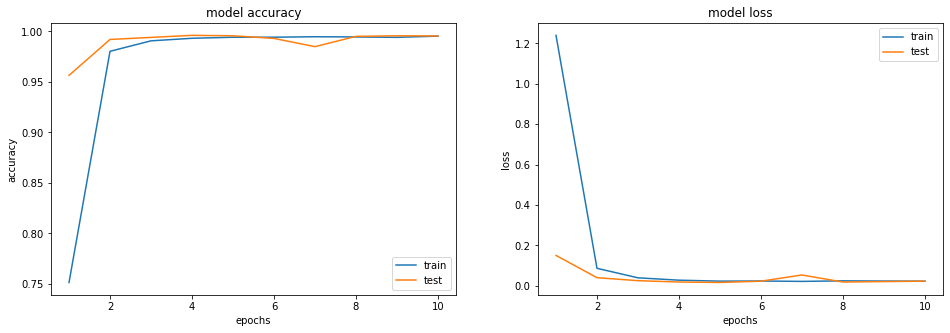
8) 답변 처리 과정
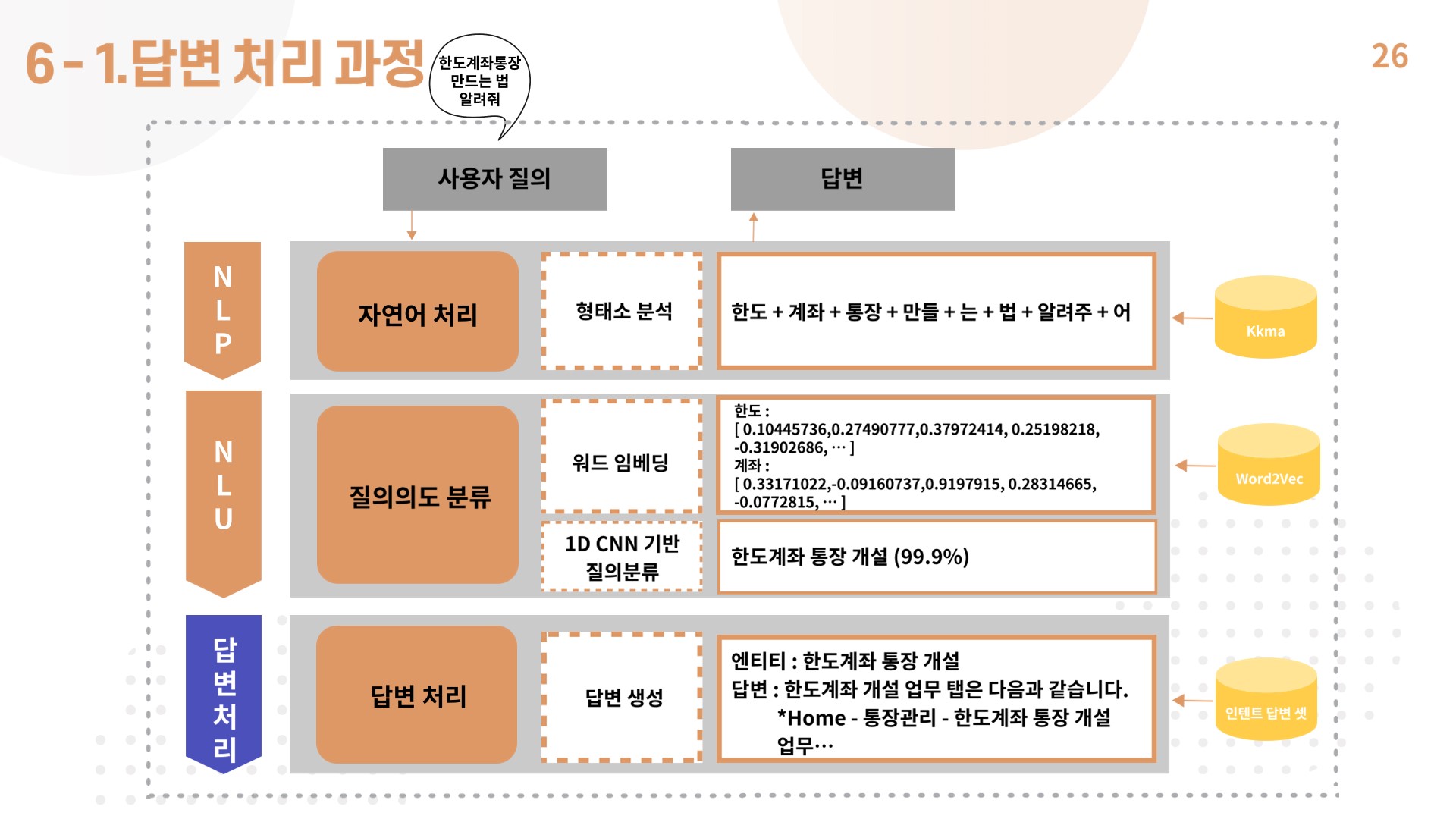

- 답변 처리는 두가지 경우로 분류함.
- 입력된 질문을 명사만 토큰화했을 때, 데이터 베이스에 일치하는 문장이 있다면, 이에 해당하는 인텐트를 출력, 답변을 찾아서 반환하도록 했음.
- 그렇지 않은 경우, 입력된 질문을 문장 단위로 토큰화하여 cnn 모델에 적용하여 인텐트를 출력, 답변을 반환하도록 구현함.
5. 시연영상

