시계열 데이터란❓
일정한 시간동안 수집 된 일련의 순차적으로 정해진 데이터 셋의 집합을 의미
-> 시간 축을 따라 신호가 변하는 동적 데이터
시계열 데이터의 특징으로는 시간에 관해 순서가 매겨져 있다는 점과 연속한 관측치는 서로 상관관계
시계열 데이터의 특성
- 요소의 순서가 중요
- 샘플의 길이가 다름(짧은 발음, 긴 발음)
- 문맥 의존성
- 계절성(상추 판매량, 항공권 판매량 등)
시계열 데이터를 다루기 위해 필요한 개념!
인코딩(Encoding)
- 기계는 자연어(영어, 한국어 등)을 이해할 수 없음
- 데이터를 기계가 이해할 수 있도록 숫자 등으로 변환해주는 작업이 필요
-> 이러한 작업을 인코딩이라고 함, 텍스트 처리에서는 주로 정수 인코딩, 원 핫 인코딩을 사용
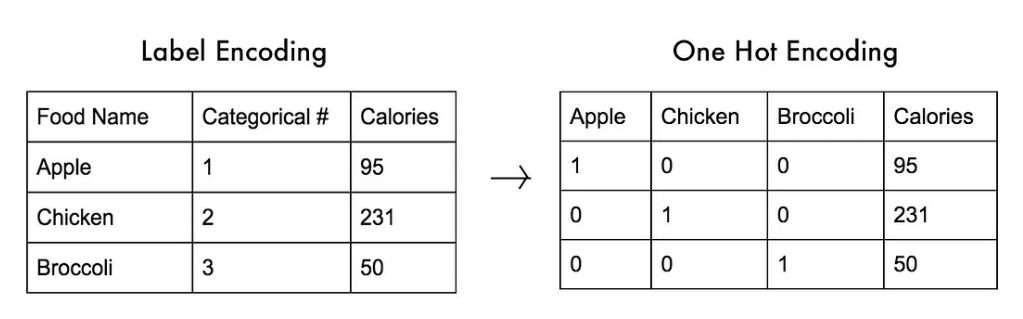
- 정수 인코딩
- dicionary를 이용 (각 단어와 정수 인덱스를 연결하고 토큰을 변환해주는 정수 인코딩)
- 원 핫 인코딩
- 원 핫 인코딩은 정수 인코딩한 결과를 벡터로 변환한 인코딩
- 원 핫 인코딩은 전체 단어 개수 만큼의 길이를 가진 배열에 해당 정수를 가진 위치는 1, 나머지는 0을 가진 벡터로 변환
- 신경망에 숫자 리스트를 주입할 수는 없음
- 리스트를 텐서로 바꾸는 방법
원 핫 인코딩하여 벡터로 변환
워드 임베딩
워드 임베딩❓
텍스트 내의 단어들을 밀집 벡터로 만드는 것
영어나 한국어 등 자연어들은 수치화되어있지 않기 때문에 특징들을 뽑아내서 수치화하게 되는 과정을 워드 임베딩이라고 함.
원 핫 벡터는 대부분이 0의 값을 가지고 단 하나의 1의 값을 가지는 벡터이며 벡터의 차원이 대체적으로 크다는 성질을 가지고 있는데 단어 집합의 크기만큼 벡터의 차원을 가지며 단어 벡터 간의 유의미한 유사도를 구할 수 없다는 단점이 있음
-> 워드 임베딩으로부터 얻은 임베딩 벡터는 상대적으로 저차원을 가지며 모든 원소의 값이 실수 값

블로그 내용은 Easy ABAP과 SAP에서 교육용으로 제공하는 자료를 참고하였습니다.