
컨테이너에서 실행하는 애플리케이션에 있어 투명성은 매우 중요한 요소다.
투명성을 확보하지 못하면 애플리케이션이 뭘 하고 있는지 또는 어떤 상태에 있는지, 문제가 있다면 어떤 부분이 원인인지 알 수 없다.
이번 장의 주제는 도커를 이용한 체계적인 모니터링이다. 프로메테우스를 사용해 애플리케이션 컨테이너에서 측정된 수치를 수집하고 그라파나를 사용해 수치를 시각화해 이해하기 쉬운 대시보드 형태로 구성한다.
9.1 컨테이너화된 애플리케이션에서 사용되는 모니터링 기술 스택
컨테이너 이전의 전통적인 애플리케이션 모니터링
- 서버의 목록과 현재 동작 상태(잔여 디스크 공간, 메모리와 CPU 사용량 등) 가 표시된 대시보드가 있다.
- 과부하가 걸리거나 응답하지 않는 서버가 발생하면 경보가 울린다.
컨테이너화된 애플리케이션 환경
- 수십 개에서 수백 개에 이르는 컨테이너에 걸쳐 실행된다.
- 플랫폼에 의해 끊임 없이 생성됐다가 삭제되기를 반복한다.
=> 컨테이너를 다룰 수 있으며 컨테이너 플랫폼과 연동해 정적인 컨테이너 혹은 IP 주소 목록 없이도 실행 중인 애플리케이션을 속속들이 들여다 볼 수 있는 도구를 갖춘 새로운 모니터링 방식이 필요하다. 그게 바로 프로메테우스!

프로메테우스
- 컨테이너에서 동작하기 때문에 분산 애플리케이션에 어렵지 않게 모니터링을 추가할 수 있다.
컨테이너에서 동작하는 프로메테우스를 사용해 도커 엔진과 다른 컨테이너를 모니터링 하기
<도커 엔진>
컨테이너의 상태를 측정하는 API를 제공하도록 도커 엔진을 설정한다.
<프로메테우스>
- 애플리케이션의 측정값을 외부로 공개하는 API를 포함해 컨테이너를 만든다.
- 애플리케이션의 프로메테우스 역시 컨테이너에서 실행되며 도커 엔진과 그 외 애플리케이션 컨테이너로부터 데이터를 수집한다.
수집된 데이터를 수집 시각과 함께 저장된다. 측정값을 외부로 공개하는 API를 포함해 컨테이너를 만든다.
프로메테우스 장점
-
모니터링의 중요한 측면인 일관성이 확보된다. 윈도 컨테이너의 닷넷 애플리케이션이든 리눅스 컨테이너의 Node.js 애플리케이션이든 모든 애플리케이션을 똑같은 표준적인 형태로 모니터링 할 수 있다.
측정 값을 추출하기 위한 쿼리 언어도 한가지만 익히면 되고, 전체 애플리케이션 스택에 똑같은 모니터링을 적용할 수 있다. -
도커 엔진의 측정값도 같은 형식으로 추출할 수 있다. 이를 통해 컨테이너 플랫폼에서 벌어지는 일도 파악할 수 있다. 이 기능을 사용하려면 도커 엔진 설정에서 프로메테우스 측정 기능을 명시적으로 활성화 해야한다.

이 설정을 추가하면 포트 9323 번을 통해 측정 값이 공개된다.
http://localhost:9323/metrics에서 도커 엔진의 상태 정보를 볼 수 있다.
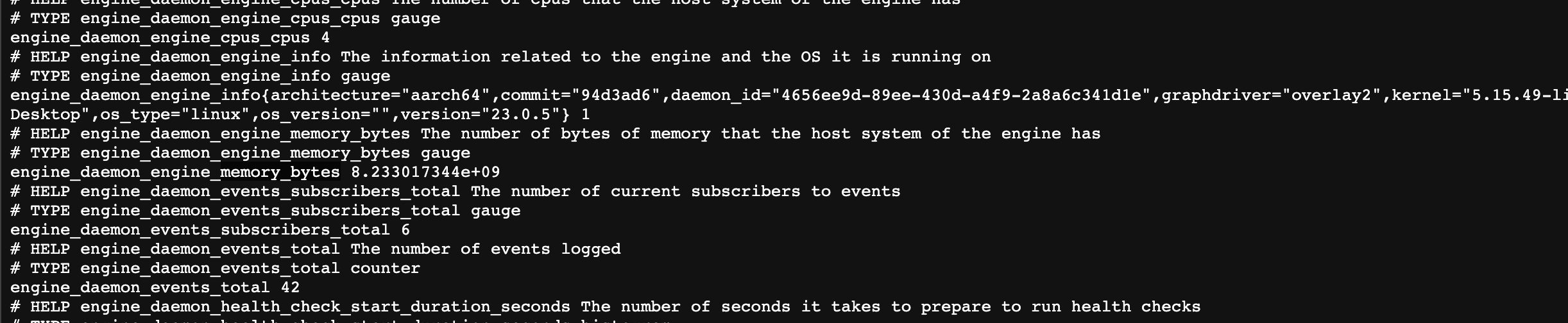
현재 컨테이너의 상태별 개수 처럼 지속적으로 변화하는 정보가 있음
제공되는 상태 정보 중에는 도커를 실행중인 시스템의 설치된 메모리 용량 같은 정적인 정보가 있다.
- 정보 항목마다 별도의 엔드포인트를 통해 실시간으로 값을 제공한다.
- 프로메테우스는 이 값을 수집하면서 타임스탬프 값을 덧붙여 저장하므로 저장된 값을 정리해 시간에 따른 값의 변화를 추적할 수 있다.
실습
프로메테우스를 컨테이너에서 실행해 현재 도커를 실행 중인 컴퓨터의 정보를 수집해 보자.
이를 위해서는 먼저 현재 로컬 컴퓨터의 IP 주소를 확인해야한다. 컨테이너는 자신이 실행중인 서버의 IP를 알 수 없으므로 이 정보를 컨테이너에 환경 변수 형태로 직접 전달해야한다.
# 로컬 컴퓨터의 IP 주소를 확인해 환경 변수로 정의하기 (macOS)
hostIP=$(ifconfig en0 | grep -e 'inet\s' | awk '{print $2}')
# 환경 변수로 로컬 컴퓨터의 IP 주소를 전달해 컨테이너를 실행
docker container run -e DOCKER_HOST=$hostIP -d -p 9090:9090 diamol/prometheus:2.13.1프로메테우스가 포함된 diamol/prometheus 이미지의 설정중 DOCKER_HOST 환경 변수를 사용해 호스트 컴퓨터와 통신하고 도커 엔진의 상태 측정 값을 수집한다.
주기적으로 도커 호스트에서 측정값을 수집한 다음, 타임스탬프를 덧붙여 데이터 베이스에 저장한다.
수집된 데이터를 열람할 수 있는 간단한 웹 인터페이스가 실행됐다. 이 웹 인터페이스를 통해 /metrics 엔드포인트로 제공되는 모든 정보를 확인할 수 있다.
-
프로메테우스의 웹 인터페이스를 통하면 어떤 정보가 수집 됐는지 일목 요연하게 볼 수 있고, 간단한 쿼리를 사용할 수 있다.
-
이들 정보는 각 상태별 컨테이너 수나 실패한 헬스 체크 횟수 같은 고수준 정보부터 도커 엔진이 점유 중인 메모리 용량 같은 저수준 정보까지 다양하다.
-
호스트 컴퓨터에 설치된 CPU 수와 같은 인프라스트럭처의 정적인 정보도 포함된다.
⭐️ 우리가 해야할 일
애플리케이션 또한 자신의 상태 정보를 제공하는데, 이들 정보의 자세한 정도는 애플리케이션 마다 다르다.
컨테이너마다 측정값을 수집할 엔드포인트를 만들고 프로메테우스가 이들 엔드포인트에서 주기적으로 정보를 수집하게 하는 것이다. 그러면 전체 시스템의 상태를 한 눈에 알 수 있는 대시보드를 만들 수 있다.
9.2 애플리케이션의 측정값 출력하기
애플리케이션의 유용한 정보를 측정값으로 구성하려면 이들 정보를 생성하는 코드를 작성해 HTTP 엔드포인트로 출력해야 하기 때문에 이미 만들어진 도커 엔진의 측정값을 수집하는 것 보다 수고스럽다.
그러나, 주요 프로그래밍 언어에는 프로메테우스의 라이브러리가 제공되므로 이를 사용하면 그리 어렵지 않다.
🙆♀️ 이번 장의 예제
NASA 오늘의 천체 사진 애플리케이션에 프로메테우스 측정값 생성 코드를 추가한 것이다. 자바, GO 언어용 프로메테우스 공식 클라이언트, Node.js 용 비공식 클라이언트 라이브러리를 사용한다.
각 컨테이너에 프로메테우스 클라이언트가 함께 패키징 되어있다. 이 클라이언트가 측정값을 출력하고 수집한다.
그림 9-5 (p204)
- 프로메테우스 클라이언트 라이브러리를 사용해 각 컨테이너에 측정값을 출력하는 엔드포인트를 만든다.
- 애플리케이션의 각 컴포넌트에 측정값을 출력하는 HTTP 엔드포인트가 추가된다. 이 측정값의 정보는 런타임 종류마다 다르지만, 프로메테우스의 포맷을 따른다.
- 웹 애플리케이션은 Go로 구현됐다. 프로메테우스를 지원하는 promhttp 모듈을 추가했다.
- 자바로 구현된 REST API에는 micrometer 패키지가 추가됐다. 이 패키지는 스프링 애플리케이션에서 프로메테우스 지원을 제공한다.
- Node.js 의 prom-client 패키지가 프로메테우스 지원을 제공한다.
💭 프로메테우스 클라이언트 라이브러리를 통해 수집된 정보
- 런타임 수준의 측정값으로, 해당 컨테이너가 처리하는 작업이 무엇이고, 이 작업의 부하가 어느정도 인지에 대한 정보가 런타임의 관점에서 표현돼있다.
- Go 애플리케이션의 측정값에는 현재 활성 상태인 고루틴의 개수가 포함돼있고, 자바 애플리케이션의 측정값에는 JVM이 사용중인 메모리 용량 정보가 들어있다.
- 각각의 런타임은 중요도가 높은 측정값을 갖고있으며 해당 클라이언트 라이브러리도 이러한 정보를 수집해 외부로 제공한다.

실습
이번 장의 연습 문제에는 image-gallery 애플리케이션의 프로메테우스 클라이언트가 적용된 새로운 버전을 사용하는 도커 컴포즈 파일이 들어있다. 이 애플리케이션을 실행해 측정값을 제공하는 엔드포인트에 접근해 보자.
version: "3.7"
services:
accesslog:
image: diamol/ch09-access-log
ports:
- "8012:80"
networks:
- app-net
iotd:
image: diamol/ch09-image-of-the-day
ports:
- "8011:80"
networks:
- app-net
image-gallery:
image: diamol/ch09-image-gallery
ports:
- "8010:80"
depends_on:
- accesslog
- iotd
networks:
- app-net
prometheus:
image: diamol/ch09-prometheus
ports:
- "9090:9090"
environment:
- DOCKER_HOST=${HOST_IP}
networks:
- app-net
# 모든 컨테이너를 제거한다
docker container rm -f $(docker container ls -aq)
# 도커 네트워크 nat을 생성한다
# 같은 이름의 기존 네트워크가 있다면 경고 메시지가 나오지만, 무시해도 좋다
docker network create nat
# 애플리케이션을 시작한다.
docker-compose up -d
# 웹 브라우저에서 http://localhost:8010에 접근하면 애플리케이션 화면이 나타난다
# http://localhost:8010/metrics 에서는 측정값을 볼 수 있다.
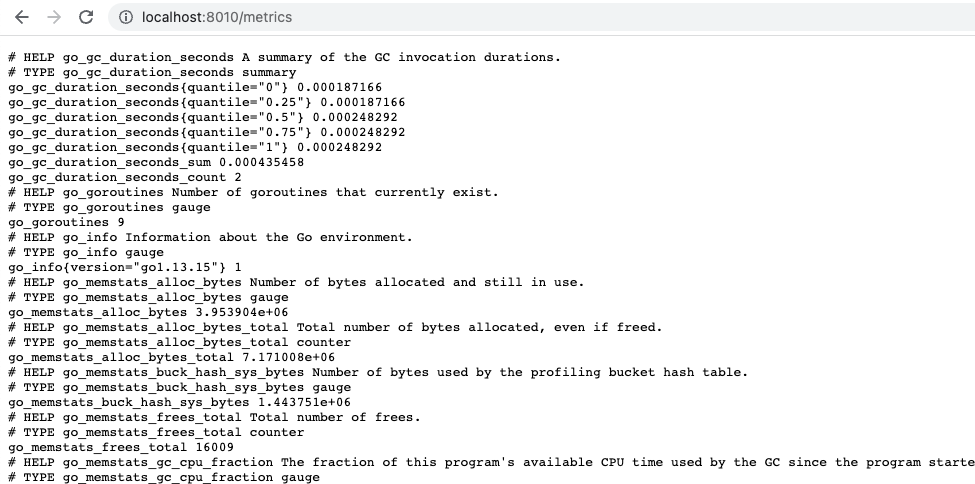
⭐️ 측정값의 포맷은 프로메테우스 포맷이지만 내용은 런타임 종류에 따라 다르다.
http://localhost:8011/actuator/prometheus <- 요기 접근하면 자바 REST API의 측정 값을 볼 수 있다.
컨테이너가 얼마나 열심히 동작하는지 (CPU 시간, 메모리, 스레드 등을 얼마나 많이 점유하는지) 내용을 포함한다.
측정값의 마지막 수준
- 애플리케이션에서 우리가 직접 노출시키는 핵심 정보로 구성된 애플리케이션 측정값이다.
- 컴포넌트가 처리하는 이벤트의 수, 평균 응답 처리 시간처럼 연산 중심의 정보일 수 있다.
- 현재 시스템을 사용중인 활성 사용자 수나 새로운 서비스를 사용하는 사용자의 수와 같은 비즈니스 중심의 정보 일 수 있다.
- 프로메테우스 클라이언트 라이브러리를 사용해도 이러한 애플리케이션 측정값을 수집할 수 있지만 애플리케이션에서 명시적으로 이들 정보를 생성하는 코드를 작성해야한다.
// Node.js에서 커스텀 프로메테우스 측정값을 선언하고 사용하기
// 측정값 선언하기
const accessCounter = new prom.Counter({
name: "access_log_total",
help: "Access Log - 총 로그 수"
});
const clientIpGauge = new prom.Gauge({
name: "access_client_ip_current",
helo: "Access Log - 현재 접속중인 IP 주소"
});
// 측정값 갱신하기
accessCounter.inc();
clientIpGauge.set(countOfIpAddresses);- 각각의 애플리케이션에서 프로메테우스 클라이언트 라이브러리는 서로 다른 방식으로 동작한다.
- 프로메테우스 측정값에도 몇 가지 유형이 있다.
- 이 애플리케이션에서 사용한 유형은 가장 간단한 종류인 카운터와 게이지다. 모두 숫자값이다.
- 가장 적합한 측정 값 유형 을 정하고 정확한 시점에 값을 갱신하는 것은 애플리케이션 개발자에게 달렸다. 나머지는 프로메테우스 라이브러리가 대신 처리해준다.
실습
image-gallery 애플리케이션에 부하를 가한다음, 해당 애플리케이션의 측정값이 출력되는 엔드포인트에 접근하라
as is

# 반복문을 돌며 다섯 번의 HTTP GET 요청을 보낸다.
for i in {1..5}; do curl http://localhost:8010 > /dev/null; done
웹 브라우저에서 https://localhost:8012/metrics에 접근한다.
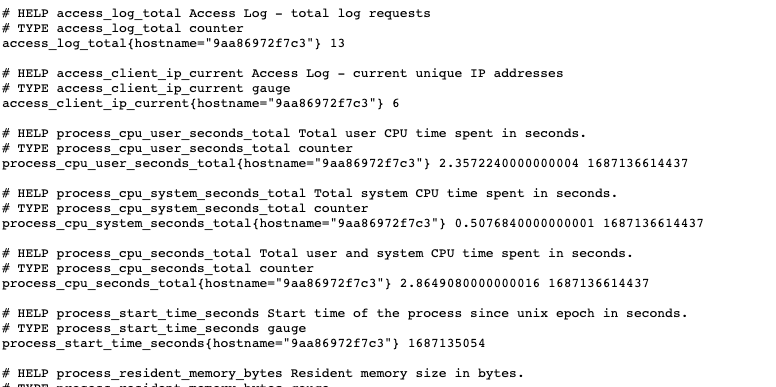
- Node.js 런타임에 대한 측정값과 커스텀 측정값이 한 엔드포인트에서 함께 제공된다.
- Node.js 런타임 측정값은 클라이언트 라이브러리가 생성한 것이다. 사용된 총 CPU시간이다.
어떤 값을 수집할지는 어떤 애플리케이션이냐에 따라 다르다. 다음 목록을 대강의 기준으로 삼을 수 있다.
- (만약 있다면) 외부 시스템과의 통신에 걸린 시간과 성공적으로 응답을 받았는지 여부에 대한 기록, 이 측정값으로 외부 시스템이 애플리케이션의 속도나 이상 상태에 영향을 줬는지 알 수 있다.
- 로그로 남길 가치가 있는 모든 정보, 로그로 남기는 것보다는 측정값으로 수집하는 편이 메모리, 디스크 용량, CPU 시간 면에서 저렴하고 추세를 볼 수 있도록 시각화 하기도 쉽다.
- 사업 부서에서 필요로 하는 애플리케이션의 상태 및 사용자 행동에 관한 모든 정보, 측정값을 활용하면 과거 정보를 수고를 들여 보고하는 대신 실시간 정보로 대시보드를 구성할 수 있다.
9.3 측정값 수집을 맡을 프로메테우스 컨테이너 실행하기
- 프로메테우스는 직접 측정값을 대상 시스템에서 받아다 수집하는 풀링 방식으로 동작한다.
- 프로메테우스에서 측정값을 수집하는 과정을 스크래핑이라고한다. 프로메테우스를 실행하면 스크래핑 대상 엔드포인트를 설정해야한다.
아래 예제는 image-gallery 애플리케이션의 두 컴포넌트로부터 측정값을 스크래핑 하기 위해 사용한 설정이다.
- 전역 설정인 global 항목을 보면 스크래핑 간격이 기본값인 10초로 설정돼있고, 각 컴포넌트마다 스크래핑 작업을 의미하는 job 설정이 정의돼 있다.
- jab 설정은 해당 스크래핑 작업의 이름과 측정값을 수집할 엔드포인트, 대상 컨테이너를 지정하는 정보로 구성된다.
- 이 설정에는 두가지 유형이 있다.
- 첫 번째는 정적 설정인 static_config인데 호스트 명으로 단일 컨테이너를 지정한다.
- 두번째는 dns_sd_config로 DNS 서비스 디스커버리 기능을 통해 여러 컨테이너를 지정할 수 있고 스케일링에 따라 대상 컨테이너를 자동으로 확대할 수 있다.
- 프로메테우스가 10초마다 한 번씩 모든 컨테이너에서 측정값을 수집한다.
// 애플레케이션 측정값을 스크래핑하기 위한 프로메테우스 설정
global:
scrape_interval: 10s
scrape_configs:
- job_name: "image-gallery"
metrics_path: /metrics
static_configs:
- targets: ["image-gallery"]
- job_name: "iotd-api"
metrics_path: /actuator/prometheus
static_configs:
- targets: ["iotd"]
- job_name: "access-log"
metrics_path: /metrics
dns_sd_configs:
- name:
- accesslog
type: A
port: 80- image-gallery에 대한 설정은 단일 컨테이너를 대상으로 하는 설정이므로 이 컴포넌트에 스케일링을 적용하면 의도치 않은 동작을 보일 수 있다.
- 프로메테우스는 DNS의 응답 중에서 가장 앞에오는 IP 주소를 사용하므로 도커 엔진이 DNS 응답을 통해 로드 밸런싱을 적용한 경우 그 컨테이너 모두에서 측정값을 받아 올 수 있다.
- accsslog 컴포넌트의 스크래핑은 여러 IP 주소를 상정해 설정됐으므로 모든 컨테이너의 IP 주소를 목록으로 만들어 이들 모두에게서 같은 간격으로 측정값을 수집한다.
원하는 설정값이 기본값으로 포함된 프로메테우스 이미지를 만들면 매번 추가로 설정을 작성하지 않아도 되며, 필요한 경우에는 기본값을 수정할 수 있다.
측정값은 여러 컨테이너에서 수집할 때 한층 더 흥미롭다. image-gallery 애플리케이션의 Node.js 컴포넌트를 스케일링해 컨테이너의 수를 증가시키면 프로메테우스가 이들 컨터에너 모두 에서 측정값을 수집한다.
실습
docker-compose-scale.yml 파일은 access-log서비스의 공개 포트를 무작위로 설정하기 때문에 해당 서비스에 스케일링을 적용할 수 있다. 세 개의 컨테이너로 이 서비스를 실행하고 웹 애플리케이션에서 부하를 가해보자.
docker-compose -f docker-compose-scale.yml up -d --scale accesslog=3
# HTTP GET 요청을 열 번 보냄(리눅스)
for i in {1..10}; do curl http://localhost:8010 > /dev/null; done- 웹 애플리케이션을 요청을 받을 때마다 access-log 서비스를 호출한다.
- access-log 서비스는 세 개의 컨테이너가 동작 중이므로 서비스에 대한 요청은 이들 컨테이너에 고르게 분배된다.
- access-log서비스에 로드 밸런싱이 잘 적용되었는지 어떻게 검증할 수 있는가?
- 애플리케이션 컴포넌트에서 수집한 측정값에는 측정값이 수집된 컨테이너의 호스트명 정보(여기서는 컨테이너 식별자)를 포함한다.
- 프로메테우스 웹 인터페이스를 열고 access-log 컴포넌트의 측정값을 살펴보자. 데이터가 세 개의 세트로 나뉜 것을 볼 수 있다.
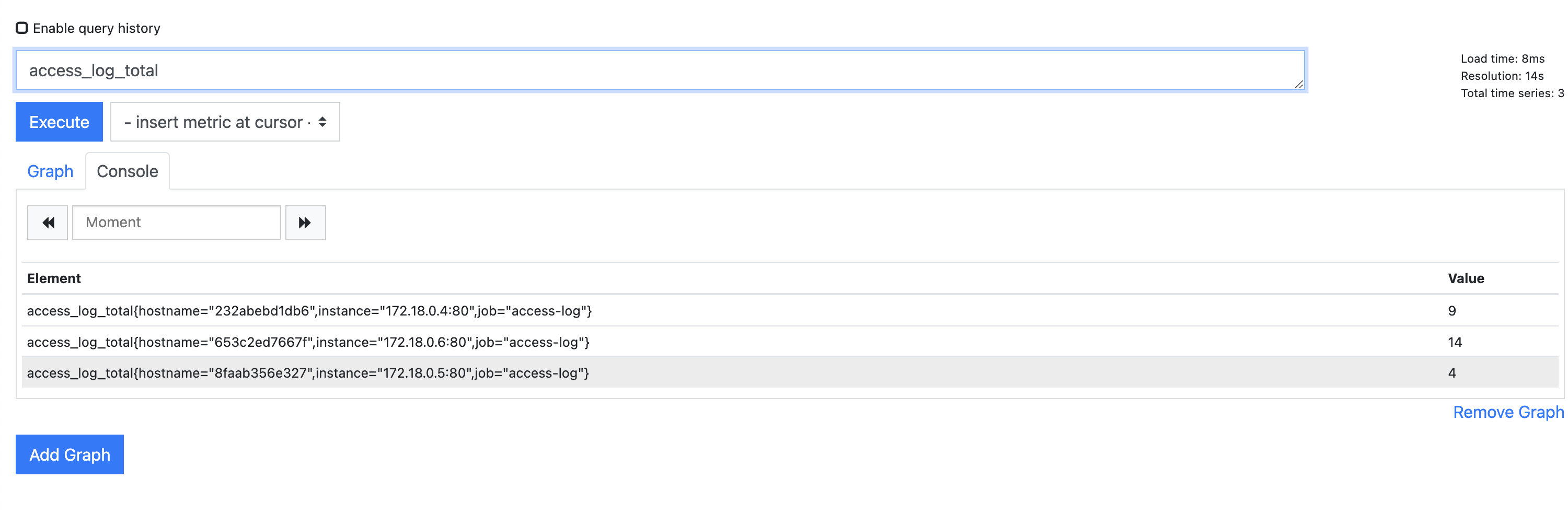
- 측정값 레이블에 컨테이너의 호스트 명이 포함되어있다. => 컨테이너마다 한 측정값이 수집됐다.
- 이 측정값의 값 항목을 보면 로드 밸런싱이 얼마나 고르게 부하를 분배했는지 알 수 있다.
- 로드 밸런싱에 네트워크가 관여하는 부분(DNS 캐시 혹은 HTTP keep-alive 커넥션등) 많으므로 단일 서버에서 도커를 실행했다면 측정 값이 완전히 같은 경우는 보기 어렵다.
실습
프로메테우스 웹 UI에서 Add Graph 버튼을 클릭하면 새로운 쿼리로 그래프를 추가할 수 있다.
표현식 텍스트 박스에 다음 쿼리를 입력하라
sum(access_log_total) without(hostname, instance)
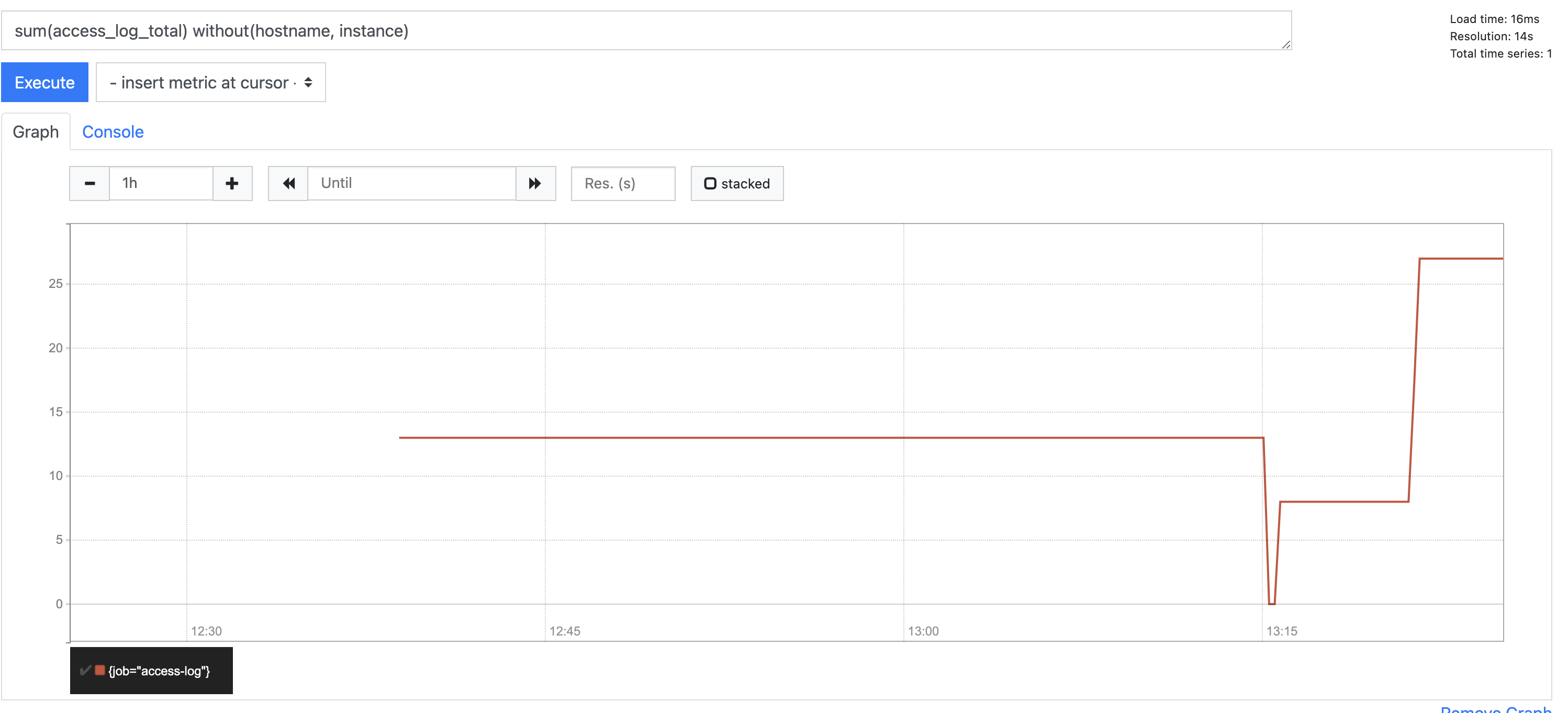
-
쿼리를 통해 모든 컨테이너의 access_log_total 측정값이 hostname과 instance를 따지지 않고 합해진다.
-
그래프 뷰로 넘어가면 시간 축에 따른 쿼리의 결과의 추이를 보여준다. 이 측정값은 카운터이기 때문에 시간에 따라 증가하는 패턴을 보인다.
p214 간단한 프로페테우스 쿼리 PromQL
9.4 측정값 시각화를 위한 그라파나 컨테이너 실행하기
-
어떤 측정값을 수집할 것인지는 비즈니스의 목표와 운영상의 필요에 따라 결정된다.
-
측정값을 어떻게 수집할 것인가는 애플리케이션을 구동하는 런타임과 이 런타임에서 동작하는 프로메테우스 클라이언트에 작동 방식에 달렸다.
-
프로메테우스를 사용해 데이터를 수집했다면! 측정값을 열람하거나 데이터 시각화를 위한 쿼리를 확인하고 손보는 데는 프로메테우스 웹 UI를 사용
-
이 쿼리를 연결해 대시보드를 구성하는 데는 그라파나를 사용한다.
-
대시보드로 애플리케이션의 상황을 일목요연하게 파악할 수 있다.
-
그라파나 대시보드는 애플리케이션의 핵심 정보를 다양한 수준에서 제공한다. 그래프 하나하나는 promQL로 작성된 단일 쿼리로 그려진다.
실습
로컬 컴퓨터의 IP 주소를 확인한다. 환경 변수로 저장된 IP 주소는 컴포즈 파일을 통해 프로메테우스 컨테이너로 전달된다. 도커 컴포즈로 애플리케이션을 실행한 다음 부하를 가한다.
# 로컬 컴퓨터의 IP 주소를 환경 변수로 저장하기(리눅스)
export HOST_IP=$(ip route get 1 | awk '{print $NF;exit}')
# 그라파나가 포함된 컴포즈 파일로 애플리케이션을 실행
docker-compose -f ./docker-compose-with-grafana.yml up -d --scale accesslog=3m1에서 그라파나(이미지) 동작이 안된다..
/run.sh: line 80: /usr/share/grafana/bin/grafana-server: No such file or directoryp218 예시
이 대시 보드 에는 애플리케이션의 부하가 얼마나 되는지, 이를 감당하기 위한 시스템의 부하는 어느정도인지 파악할 수 있는 네가지 측정값이 쓰였다.
- 대시보드느 그래프는 절대적인 값 보다는 변화하는 추세에서 알 수 있는 정보가 더 많다.
- 중요한 것은 평균 값에서 벗어나 수치가 튀어오르는 순간이 언제인지다.
- 컴포넌트의 측정값을 조합해 애플리케이션의 컴포넌트에 발생한 이상 현상과 이들의 상관관계를 찾아야한다.
마지막 단계는 지금까지 만든 데이터 소스 및 대시보드 설정을 포함시켜 그라파나 도커 이미지를 만드는 것이다.
//커스텀 그라파나 이미지의 Dockerfile 스크립트
FROM diamol/grafana:6.4.3
COPY datasource-prometheus.yaml ${GF_PATHS_PROVISIONING}/datasources/
COPY dashboard-provider.yaml ${GF_PATHS_PROVISIONING}/dashboards/
COPY datasource.json /var/lib/grafana/dashboards/
- 특정 버전의 그라파나 이미지를 기반 이미지로 삼은 다음, 몇 가지 YAML 파일고 JSON 파일을 이미지로 복사한다.
- 기본 설정은 이미지에 내장시키고 필요한 설정만 변경해서 사용한다.
- YAML 파일은 각각 프로메테우스에 연결하기 위한 정보와 /var/lib/Hrafana/dashboards 디렉터리에서 대시보드 구성을 읽으라는 내용을 담고있다.
- 마지막 인스트럭션은 지금 만든 대시보드 구성 파일을 설정된 디렉터리에 복사한다.
9.5 투명성의 수준
컨테이너 기술 초기의 모니터링은 정말 골치아팠다.. 오늘날의 컨테이너 모니터링은 이미 시행착오를 거친 신뢰성 있는 수단을 사용한다.
가장 중요한 것은 애플리케이션의 전체 상황을 조망하는 대시보드다. 측정값 중에서 가장 애플리케이션에 중요한 데이터를 모아 하나의 화면으로 구성할 수 있어야한다.
그래야 한눈에 이상상황을 파악하고 사태가 악화되기 전에 과감한 조치를 취할 수 있다.
