요즘 gpt 스터디를 위한 선행 학습인 phython 스터디를 하고 있다.
처음 웹개발 공부를 시작했을때 열심히 들었던 노마드 코더를 다시 듣고 있다.
Python으로 웹 스크래퍼 만들기 라는 무료 강의를 듣고 있다.
5년전 처음 Javascript를 배웠을때 처럼 설레기도 하고, 예전에는 이해 못했던 것들을 이제는 이해하는 모습을 보고 내가 꽤 성장했나? 하는 생각이 들어 뿌듯하기도 하다.
그 동안 Phyhon의 아주 기초적인 부분들을 배웠고 오늘부터는 JOB SCRAPER를 만든다. 떨린다~
vscode 대신 Replit 이라는 브라우저 기반 IDE를 사용한다.
- beautifulsoup4 이라는 dependencies를 다운받았다. scraping에 사용되는 라이브러리 인가보다.
- requests도 다운받는다.(이전 학습때 받아 뒀음) https 요청을 보낼 수 있다.
https://weworkremotely.com/categories/remote-full-stack-programming-jobs
라는 구인구직 사이트? 에 정보를 scraping 할 것이다.
- requests를 이용해서 get 요청을 날려본다.
from bs4 import BeautifulSoup
import requests
url = "https://weworkremotely.com/categories/remote-full-stack-programming-jobs"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
print(soup)
- 두둥..해싱된 html이 날라온다. (당황)
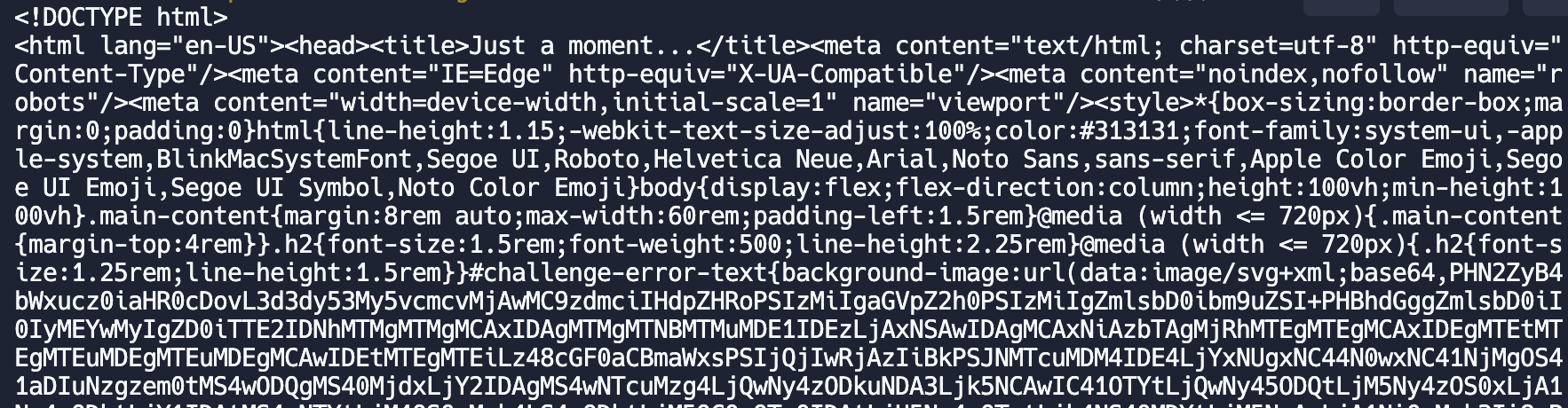
<title>Just a moment...</title>html 시작한다는것은 CloudFlare의 전형적인 보안 검사 페이지 라고 한다. 즉 CloudFlare로 보안처리된 website 라는뜻..!
- 당황하지말고 cloudscraper를 다운받도록 한다.
Cloudflare 로 보안 처리된 website를 우회 함 (브라우저 인척 해준다고함)
from bs4 import BeautifulSoup
import cloudscraper
scraper = cloudscraper.create_scraper()
url = "https://weworkremotely.com/categories/remote-full-stack-programming-jobs"
response = scraper.get(url)
soup = BeautifulSoup(response.content, "html.parser")
jobs = soup.find("section", class_="jobs").find_all("li", )
print(jobs)
오.. 보안 처리가 날아갔다.✈️✈️✈️
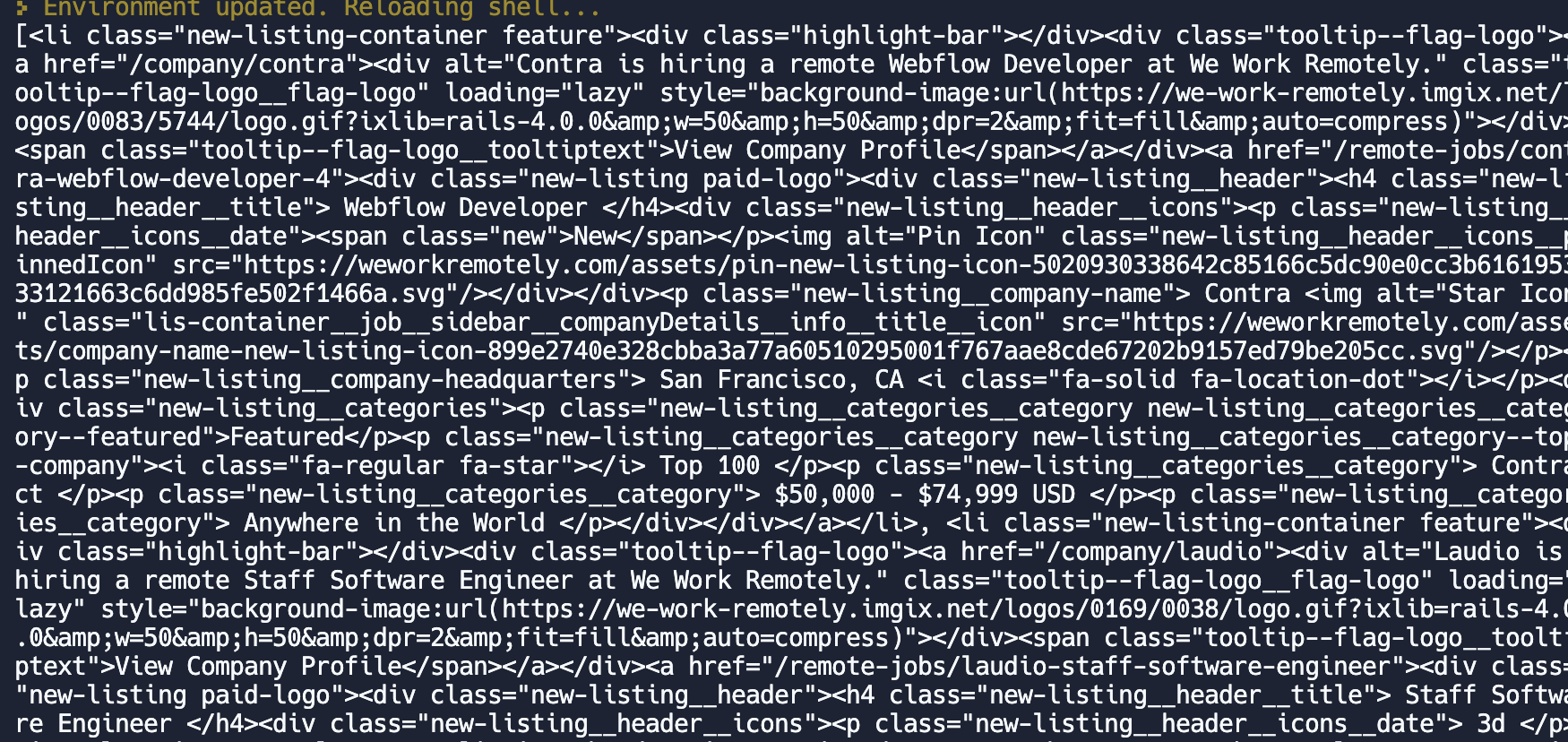
- 필요한 데이터를 가져와 봤다.
from bs4 import BeautifulSoup
import cloudscraper
scraper = cloudscraper.create_scraper()
url = "https://weworkremotely.com/categories/remote-full-stack-programming-jobs"
response = scraper.get(url)
soup = BeautifulSoup(response.content, "html.parser")
jobs = soup.find("section", class_="jobs").find_all("li")[1:-1]
for job in jobs:
title = job.find("h4", class_="new-listing__header__title").text
company = job.find('p', class_="new-listing__company-name").text
categories = job.find_all('p', class_='new-listing__categories__category')
region = categories and categories[-1].text
print(f"title: {title}, region:{region}, company: {company}")
완성본이다!
from bs4 import BeautifulSoup
import cloudscraper
scraper = cloudscraper.create_scraper()
url = "https://weworkremotely.com/categories/remote-full-stack-programming-jobs"
response = scraper.get(url)
soup = BeautifulSoup(response.content, "html.parser")
jobs = soup.find("section", class_="jobs").find_all("li")[1:-1]
for job in jobs:
title = job.find("h4", class_="new-listing__header__title").text
region = job.find_all('p', class_='new-listing__categories__category')[:-1]
print(title)
print(region)

잼나게 코딩하면서 살고 싶어요 ^O^/