인덱스
인덱스란
-
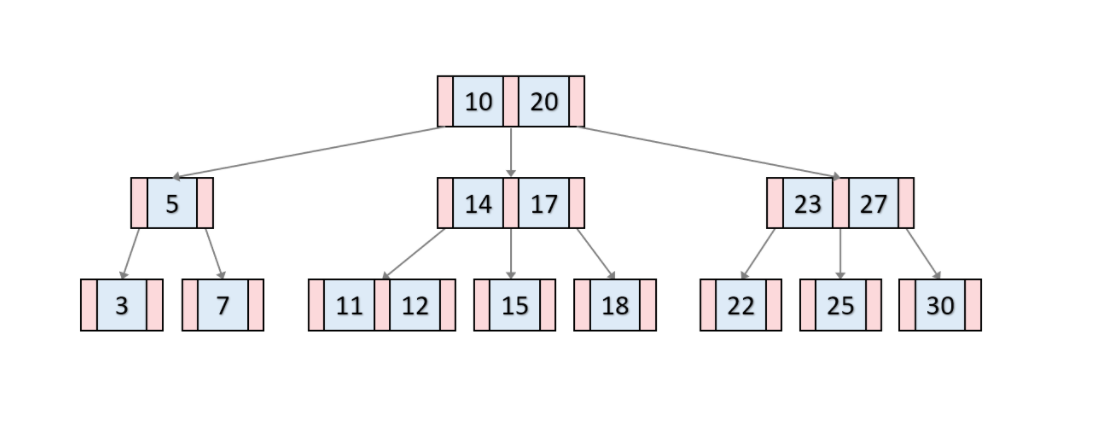
인덱스 구조 B-Tree
-
지정한 컬럼들을 메모리 영역에 목차를 생성
-
인덱스의 두번째 컬럼은 첫 번째 컬럼에 의존해서 정렬
-
인덱스의 개수는 3~4개가 적당
-
페이지는 16KB로 크기 고정 , 인덱스의 키는 킬수록 성능이슈 발생
-
insert, update, delete (Command)의 성능을 희생하고 대신 select (Query)의 성능을 향상
update, delete를 하기 위해 해당 데이터를 조회 하는 것은 인덱스가 있으면 빠르게 조회텍스트
인덱스구조
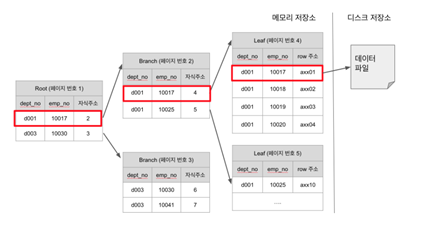
인덱스 컬럼기준
- Cardinarliy 가장 높은것 ex) 계좌번호, 주민등록번호
- 인덱스로 최대한 효율을 뽑아내려면, 해당 인덱스로 많은 부분을 걸러내야 한다.
- 여러 컬럼을 인덱스로 잡을 경우에도 Cardinarliy 높은순서 ex) group_no, from_date, is_bonus
- 조회 쿼리 사용시 인덱스를 태우려면 최소한 첫번째 인덱스 조건은 조회조건에 포함시킬것 - 첫번째 인덱스컬럼이 조회 쿼리에 없을경우 인덱스를 타지 않는다.
인덱스 조회 - 주의상항
-
between, like, <, >등 범위 조건은 해당 컬럼은 인덱스를 타지만, 그 뒤 인덱스 컬럼들은 인덱스가 사용되지 않습니다. ex) group_no=XX and is_bonus=YY and from_date > ?? 등으로 잡으면 is_bonus는 인덱스가 사용되지 않습니다.
-
반대로 = , in 은 다음 컬럼도 인덱스를 사용합니다. – 서브 쿼리를 넣게 되면 성능상 이슈가 발생합니다.
-
AND 연산자는 각 조건들이 읽어와 야할 ROW수를 줄이는 역할을 하지만, or 연산자는 비교해 야할 ROW가 더 늘어나기 때문에 풀 테이블 스캔이 발생할 확률이 높습니다. – (테이블에 포함된 레코드를 처음부터 끝까지 읽음)
-
Where salary * 10 > 150000;는 인덱스를 못타지만, where salary > 150000 / 10; 은 인덱스를 사용합니다.
-
컬럼이 문자열인데 숫자로 조회하면 타입이 달라 인덱스가 사용되지 않습니다. 정확한 타입을 사용
-
Null 값의 경우 is null 조건으로 인덱스 레인지 스캔 가능 - (루트 노드 -> 리프 노드까지 일반적인 인덱스 검색)
-
조회 컬럼의 순서는 인덱스에 큰 영향을 끼치지 못합니다.
B-Tree
B트리는 이진 트리와 다르게 하나의 노드에 많은 수의 정보를 가지고 있을 수 있습니다.