
객체 버전
- 객체 버전은 버킷 안에 한 객체의 여러 버전을 보관하는 기능이다.
- 이를 통해 이전 객체의 복구 등의 작업이 가능해진다.
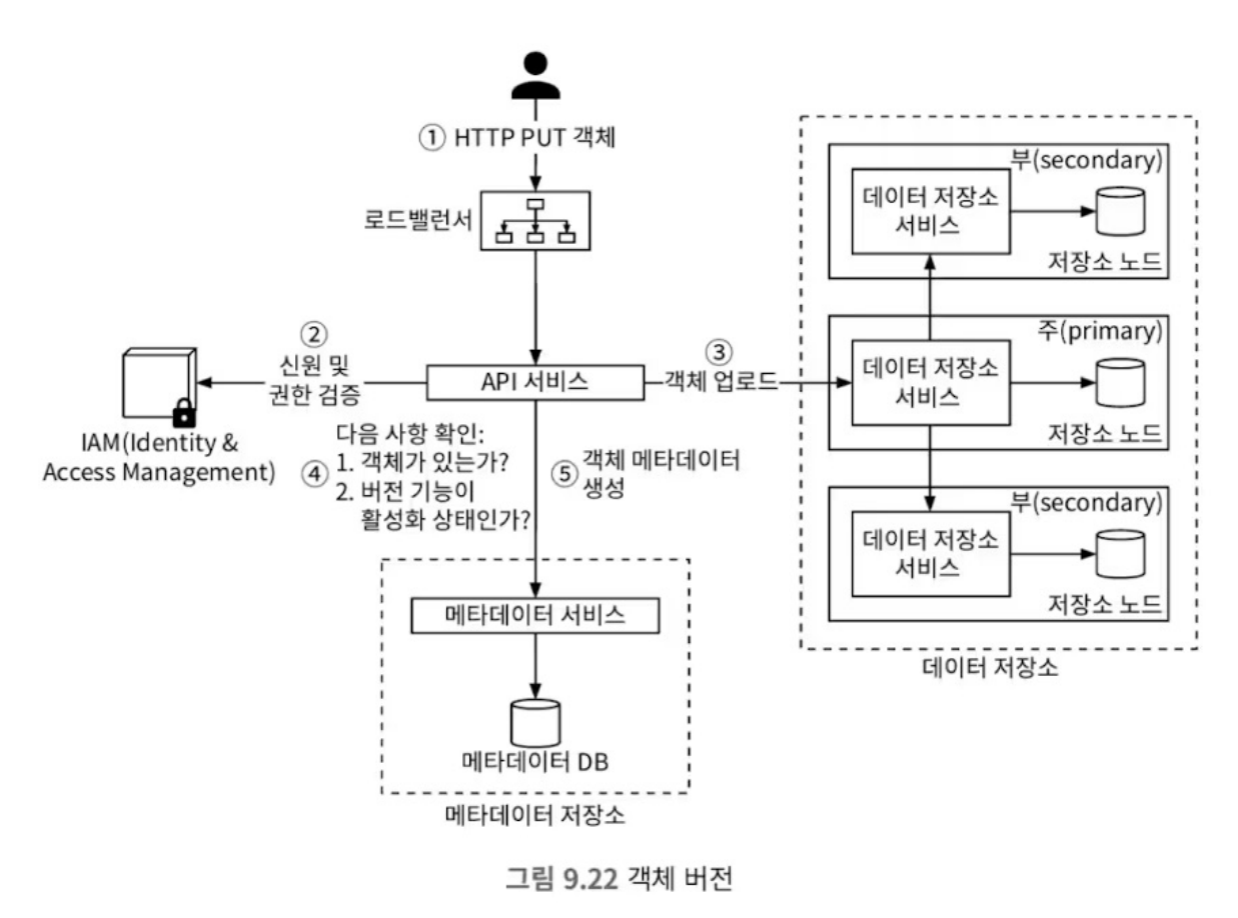
- 클라이언트가 HTTP로 PUT 요청을 보낸다.
- API 서비스는 IAM 서비스로부터 사용자의 신원과 권한을 확인한다.
- 확인결과 이상이 없다면 데이터를 저장소로 업로드한다. 데이터 저장소는 이를 각각의 노드에 복제한 후 UUID를 반환한다.
- API 서비스는 획득한 UUID를 바탕으로 메타데이터 저장소를 호출하여 메타데이터를 생성한다. 이 때 동일한 이름을 가진 기존 레코드가 있는지, 그리고 버저닝 기능이 활성화 되어있는지를 확인한다.
- 4번의 두 조건이 만족된다면 새로운 메타데이터를 생성한다. 이때
bucket_id,object_name은 같지만,object_id와object_version(TIMEUUID)이 다른 새로운 레코드를 생성한다.
- 일반적으로 이런 데이터의 삭제는 데이터를 직접 삭제하지 않고 삭제 표시를 남기는(soft delete) 방식을 사용한다.
- 이는 데이터 노드에서 데이터를 삭제하는 것이 아니라, 데이터 노드에 삭제 표시를 남기는 것이다.
큰 파일의 업로드 성능 최적화
- 수 GB 이상의 큰 파일을 업로드하는 경우도 고려해야 한다.
- 이 경우 데이터 전송에 오랜 시간이 걸리고, 그만큼 중단될 가능성도 높다.
- 따라서 다수의 작은 객체로 쪼갠 후 업로드하는 방식(multipart upload)을 사용한다.
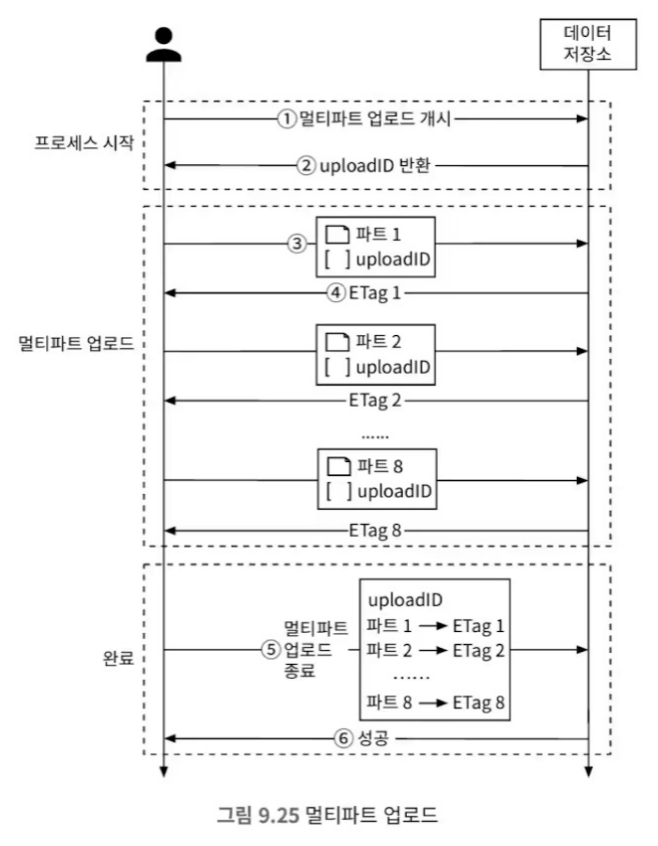
- 클라이언트가 대용량 파일을 업로드 요청을 보낸다.
- 데이터 저장소가 uploadID를 발급하고, 이를 클라이언트에 반환한다.
- 클라이언트가 파일을 작은 객체로 분할하여 업로드한다. 여기서는 1.6GB 파일을 8개로 분할하여 각 200MB씩 업로드한다고 가정하며, 각각의 파일을 2에서 얻은 uploadID를 포함하여 업로드한다.
- 조각 하나를 업로드 할 때 마다 데이터 저장소는 ETag를 클라이언트에 반환한다.
- 모든 조각이 업로드되면 클라이언트는 완료 요청을 보내며, 이때 uploadID와 각 조각의 ETag를 포함한다.
- 데이터 저장소는 이를 받아 각 조각을 복원하고 원본 파일을 재구성한다.
- 이 과정에서 실패하거나, 완성되더라도 개별 조각들이 삭제되지 않는다면 데이터 저장소에 계속 남아있을 것이다.
- 이를 방지하기 위해 데이터 저장소는 쓰레기 수집(garbage collection) 과정이 필요하다.
쓰레기 수집(가비지 컬렉션)
-
가비지 컬렉션은 더이상 사용되지 않을 데이터를 제거하여 저장 공간을 회수하는 절차이다.
-
이 설계에서는 대표적으로 아래와 같은 경우로 인해 가비지 컬렉션이 발생 할 수 있다.
- 객체의 지연 삭제(lazy object deletion): 삭제 표시를 남긴 객체가 실제로 삭제되는 시점
- 버려진 데이터(orphaned data): 업로드 중 중단된 데이터
- 훼손된 데이터(corrupted data): 체크섬, ETag 검증 등이 실패한 데이터
-
이러한 가비지 컬렉션은 매번 동작하지는 않는다.
- 비용이 많이 들기 때문에 특정 주기에 따라 실행된다.
-
가비지 컬렉션 과정에서 삭제뿐 아니라 데이터 저장소에 대한 정리 작업도 병행한다.
- 삭제가 필요한 불필요 데이터를 삭제한 뒤 여러개의 객체를 하나의 객체로 합치는 작업도 포함된다.
4단계: 마무리
- 생략

안녕하세요!