spring batch를 사용하며 겪었던 문제점들을 기록하려고 합니다.
아래 사진과 같이 api, batch 애플리케이션이 있고 분리된 데이터 저장소가 있는 구조
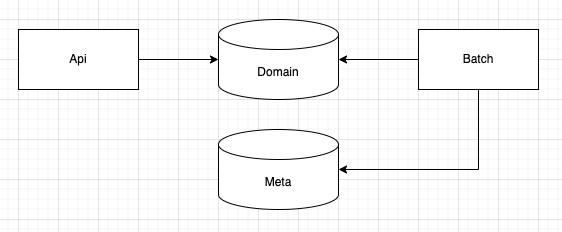
batch meta 데이터 저장소와 서비스 도메인 데이터 저장소에 대해 2개의 데이터소스와 트랜잭션 매니저를 관리해야 하기 때문에 별도의 설정이 필요하다.
설정파일은 다음과 같다.

- 서비스 도메인 데이터 저장소(이하 도메인 저장소)
- spring batch 메타 데이터 저장소(메타 저장소)
도메인 저장소는 별도의 jpa repository 설정을 요구하고, 메타 저장소는 필요하지 않기 때문에 JpaConfig 파일은 별도로 관리한다.
환경설정
spring:
config:
activate:
on-profile: local
batch:
job:
enabled: true
names: ${job.name:NONE}
logging:
level:
org.hibernate.SQL: DEBUG
server:
port: 6011
error:
include-message: always
spring:
config:
activate:
on-profile: local
jpa:
properties:
hibernate:
show_sql: true
format_sql: true
# 2개의 데이터소스를 사용하기 때문에, 아래와같이 정의한다.
domain-datasource:
pool-name: 'domain'
driver-class-name: org.mariadb.jdbc.Driver
jdbc-url: 'jdbc:mariadb://localhost:19910/domain?connectTimeout=1000&socketTimeout=600000'
username: 'root'
password: 'test'
auto-commit: false
connection-timeout: 5000
validation-timeout: 3000
maximum-pool-size: 10
minimum-idle: 2
idle-timeout: 30000
max-lifetime: 3000000
meta-datasource:
pool-name: 'meta'
jdbc-url: 'jdbc:mariadb://localhost:19910/meta?connectTimeout=1000&socketTimeout=600000'
username: 'root'
password: 'test'
auto-commit: false
connection-timeout: 5000
validation-timeout: 3000
maximum-pool-size: 10
minimum-idle: 2
idle-timeout: 600000
max-lifetime: 1800000datasource 설정
@Configuration
class BatchDataSourceConfig {
@Bean(DOMAIN_DATASOURCE)
@ConfigurationProperties(prefix = DOMAIN_PROPERTIES)
fun domainDataSource(): DataSource {
return DataSourceBuilder.create()
.type(HikariDataSource::class.java)
.build()
}
@Primary
@Bean(META_DATASOURCE)
@ConfigurationProperties(prefix = META_PROPERTIES)
fun metaDataSource(): DataSource {
return DataSourceBuilder.create()
.type(HikariDataSource::class.java)
.build()
}
companion object {
private const val DOMAIN_PROPERTIES = "spring.domain-datasource"
private const val META_PROPERTIES = "spring.meta-datasource"
const val DOMAIN_DATASOURCE = "dataSource"
const val META_DATASOURCE = "metaDataSource"
}
}jpa 설정
MetaConfig
@Configuration
@EnableConfigurationProperties(value = [JpaProperties::class, HibernateProperties::class])
@EnableJpaRepositories(
entityManagerFactoryRef = BatchMetaJpaConfig.META_ENTITY_MANAGER_FACTORY,
transactionManagerRef = BatchMetaJpaConfig.META_TX_MANAGER,
)
class BatchMetaJpaConfig(
private val entityManagerFactoryBuilder: EntityManagerFactoryBuilder,
private val jpaProperties: JpaProperties,
private val hibernateProperties: HibernateProperties,
) {
@Primary
@Bean(META_ENTITY_MANAGER_FACTORY)
fun metaEntityManagerFactory(
@Qualifier(BatchDataSourceConfig.META_DATASOURCE) dataSource: DataSource,
): LocalContainerEntityManagerFactoryBean = BatchEntityManagerFactory.create(
jpaProperties,
hibernateProperties,
entityManagerFactoryBuilder,
dataSource,
emptyList(),
"meta",
)
@Primary
@Bean(META_TX_MANAGER)
fun metaTransactionManager(
@Qualifier(META_ENTITY_MANAGER_FACTORY) entityManagerFactory: LocalContainerEntityManagerFactoryBean,
): PlatformTransactionManager {
val emfObject = entityManagerFactory.`object`
checkNotNull(emfObject) { "meta entityManagerFactory must not be null" }
return JpaTransactionManager(emfObject)
}
companion object {
const val META_ENTITY_MANAGER_FACTORY = "metaEntityManagerFactory"
const val META_TX_MANAGER = "metaBatchTransactionManager"
}
}메타저장소 설정에 @Primary 애노테이션을 명시해야합니다.
batch 작업이 실행될 때 어떤 데이터 저장소에서 도메인 데이터를 가져오고 배치 메타 데이터를 가져와야 하는지 애플리케이션이 알지 못하는데, 위 애노테이션으로 사용함으로써 batch job repository의 데이터소스가 설정됩니다.
두개이상의 데이터소스가 있을때 JobRepository를 명시하기위해 DefaultBatchConfigurer 클래스의 createJobRepository 메소드를 override 하는 방법도있다. 해당 메소드에서 메타저장소의 datasource와 transaction manager를 설정해 JobRepository 객체를 직접 생성할 수 있다.
하지만, 위 방법을 사용하지 않고 @Primary 애노테이션만 사용해도 문제없이 작동했다.
DomainConfig
@Configuration
@EnableJpaAuditing
@EnableConfigurationProperties(value = [JpaProperties::class, HibernateProperties::class])
@EnableJpaRepositories(
basePackages = JPA_PACKAGES,
entityManagerFactoryRef = BatchDomainJpaConfig.DOMAIN_ENTITY_MANAGER_FACTORY,
transactionManagerRef = BatchDomainJpaConfig.DOMAIN_TX_MANAGER,
)
@EntityScan(
basePackages = DOMAIN_PACKAGES
)
class BatchDomainJpaConfig(
private val entityManagerFactoryBuilder: EntityManagerFactoryBuilder,
private val jpaProperties: JpaProperties,
private val hibernateProperties: HibernateProperties,
) {
@Bean(DOMAIN_ENTITY_MANAGER_FACTORY)
fun domainEntityManagerFactory(
@Qualifier(BatchDataSourceConfig.DOMAIN_DATASOURCE) dataSource: DataSource,
): LocalContainerEntityManagerFactoryBean = BatchEntityManagerFactory.create(
jpaProperties,
hibernateProperties,
entityManagerFactoryBuilder,
dataSource,
JPA_PACKAGES,
"domain",
)
@Bean(DOMAIN_TX_MANAGER)
fun domainTransactionManager(
@Qualifier(DOMAIN_ENTITY_MANAGER_FACTORY) entityManagerFactory: LocalContainerEntityManagerFactoryBean,
): PlatformTransactionManager {
val emfObject = entityManagerFactory.`object`
checkNotNull(emfObject) { "domain entityManagerFactory must not be null" }
return JpaTransactionManager(emfObject)
}
companion object {
const val DOMAIN_ENTITY_MANAGER_FACTORY = "entityManagerFactory"
const val DOMAIN_TX_MANAGER = "domainBatchTransactionManager"
}
}멀티모듈 프로젝트 특성 상 도메인 객체와 jpa repository 클래스들이 각 도메인 모듈에 분산되어있다.
적절히 basePackages 를 설정해줘야한다.
EntityManagerFactory
class BatchEntityManagerFactory {
companion object {
fun create(
properties: JpaProperties,
hibernateProperties: HibernateProperties,
entityManagerFactoryBuilder: EntityManagerFactoryBuilder,
dataSource: DataSource,
packages: List<String>,
persistenceUnit: String,
): LocalContainerEntityManagerFactoryBean = entityManagerFactoryBuilder
.dataSource(dataSource)
.packages(*packages.toTypedArray())
.properties(getVendorProperties(hibernateProperties, properties.properties))
.persistenceUnit(persistenceUnit)
.mappingResources(*getMappingResources(properties.mappingResources))
.build()
private fun getMappingResources(resources: List<String>): Array<String> {
return if (!ObjectUtils.isEmpty(resources)) StringUtils.toStringArray(resources) else emptyArray()
}
private fun getVendorProperties(
hibernateProperties: HibernateProperties,
jpaProperties: Map<String, String>,
): Map<String, Any> = LinkedHashMap(
hibernateProperties.determineHibernateProperties(
jpaProperties,
HibernateSettings()
)
)
}
}설정이 끝났고, 각 도메인에 맞는 Job과 Step Configuration을 생성한다.

탈퇴한 사용자가 생성한 프로젝트를 모두 비공개처리하고, 프로젝트 참여내역(멤버)를 모두 삭제한다.
하나의 Job에 Step을 모두 구현해도 되겠지만, 도메인모듈이 나눠져있음에 따라 구분했다.
@Configuration
class AfterWithdrawalProcessingJobConfiguration(
private val jobBuilderFactory: JobBuilderFactory,
private val listener: JobLoggerListener,
@Qualifier(DeleteMemberStepConfiguration.STEP_NAME) private val deleteMemberStep: Step,
@Qualifier(HideProjectStepConfiguration.STEP_NAME) private val hideProjectStep: Step,
) {
@Bean(JOB_NAME)
fun afterWithdrawalProcessingJob(): Job = jobBuilderFactory.get(JOB_NAME)
.preventRestart()
.incrementer(RunIdIncrementer())
.listener(listener)
.start(deleteMemberStep)
.next(hideProjectStep)
.build()
companion object {
private const val JOB_NAME = "afterWithdrawalProcessingJob"
}
}위와같이 Job이 실행된다.
DeleteMemberStep
@Configuration
class DeleteMemberStepConfiguration(
private val stepBuilderFactory: StepBuilderFactory,
@Qualifier(BatchDomainJpaConfig.DOMAIN_ENTITY_MANAGER_FACTORY) private val domainEmf: EntityManagerFactory,
@Value("\${chunkSize:1000}") private val chunkSize: Int,
) {
@Bean(STEP_NAME)
fun deleteMemberStep(): Step = stepBuilderFactory.get(STEP_NAME)
.chunk<Member, Member>(chunkSize)
.reader(reader())
.processor(processor())
.writer(writer())
.build()
@Bean(READER_NAME)
fun reader(): JpaPagingItemReader<Member> {
return JpaPagingItemReaderBuilder<Member>()
.name(READER_NAME)
.pageSize(chunkSize)
.entityManagerFactory(domainEmf)
.queryString("~~~")
.build()
}
@Bean(PROCESSOR_NAME)
fun processor(): ItemProcessor<Member, Member> =
ItemProcessor { member -> member.apply { this.deletedAt = LocalDateTime.now() } }
@Bean(WRITER_NAME)
fun writer(): JpaItemWriter<Member> = JpaItemWriterBuilder<Member>()
.entityManagerFactory(domainEmf)
.build()
companion object {
private val log = LoggerFactory.getLogger(this::class.java)
const val STEP_NAME = "deleteMemberStep"
const val READER_NAME = "deleteMemberReader"
const val PROCESSOR_NAME = "deleteMemberProcessor"
const val WRITER_NAME = "deleteMemberWriter"
}
}Step을 구현하는 과정에서 reader를 구현하는 부분에 문제가 있었다.
Jpa를 사용하고 있으니 여기서도 JpaPagingItemReader를 사용했는데, 잘못된 쿼리로 데이터가 조회되지 않는 문제가 있었다.
해결이 되지않아 결국 JdbcPagingItemReader를 사용해서 reader를 구현했으나, 이번에는 writer에서 문제가 생겼다. 데이터를 가져와 processing 과정을 거친 후 이를 저장해야하는 update에 관한 작업이었으나 모두 insert 되어버렸다.
jdbc를 사용해 읽어온 데이터라, jpa 영속성 컨텍스트를 사용할 수 없어 update가 아니라, insert처리가 된것이다.
jdbc를 사용해 update 처리하려면 write를 커스텀해야하는데, jpa를 사용하면 간단히 해결 될 문제를 너무 돌아가는 방법인 것 같았다.
다시 JpaPagingItemReader를 사용하게 수정했고, 처음 시도했을때 쿼리가 제대로 동작하지 않던 이유를 찾았다.
JpaPagingItemReaderBuilder에서 사용하는 queryString에 테이블명과 컬럼명은 실제 테이블명과 컬럼명이 아니라, 논리적인 이름을 사용하고 있었다.
jdbc로 쿼리하면 alias 없이 물리적인 테이블명과 컬럼명을 사용하고, 테이블에 정의된대로 snake_case를 사용해야한다.
그러나, jpa에서는 논리적 이름을 사용한다. @Entity 애노테이션을 사용한 도메인 객체에서 메타데이터를 읽어오는 것 같다.
Listener
job builder에 사용한 listener 구현체다.
@Component
class JobLoggerListener : JobExecutionListenerSupport() {
override fun afterJob(jobExecution: JobExecution) {
log.info("JOB 수행완료 {}", jobExecution)
if (jobExecution.status.equals(BatchStatus.COMPLETED)) {
log.info("TODO: 성공 슬랙 API")
} else {
log.info("TODO: 실패 슬랙 API")
}
}
companion object {
private val log = LoggerFactory.getLogger(this::class.java)
}
}job 수행이 완료된 후처리에 대한 내용을 담고있다. 요구사항에 맞는 후처리를 잘 구현하면된다.
수정
20230703
새로운 Job을 생성하고 실행시켰는데, javax.persistence.TransactionRequiredException: no transaction is in progress 에러가 발생했다.
위에 작성된 예시의 경우 문제없이 실행되는데 새로 생성한 작업만 에러가 발생했다.
@Bean(STEP_NAME)
fun rejectExpiredJoinRequestStep(): Step = stepBuilderFactory.get(STEP_NAME)
.chunk<Member, Member>(chunkSize)
.reader(reader())
.processor(processor())
.writer(writer())
.transactionManager(domainTxManager)
/**
* reader로 읽어온 데이터가 다수 존재할 때, 트랜잭션 매니저 직접 할당안하면 javax.persistence.TransactionRequiredException: no transaction is in progress 에러가 발생한다.
*/
.build()PlatformTransactionManager 를 생성하며 EntityManagerFactory 를 등록해줘서, 해당 domainEmf를 사용하면 transactionManager 역시 함께 사용될거라 생각했지만, 직접 명시해주지 않으면 작동하지 않았다.
그러면, AfterWithdrawalProcessingJobConfiguration 은 어떻게 동작했는가?
여러가지 조건을 바꿔가며 테스트해봤는데, reader에서 여러건의 데이터가 가져와지고 다수의 아이템이 processing 되어 write 되는경우 이 문제가 발생했다. 단건 아이템이라면 별도의 트랜잭션 보장이 필요 없으니 에러가 발생하지 않고, 여러건의 save의 경우 트랜잭션 보장이 필요했기 때문에 에러가 발생한게 아닐까 추측한다.
